
Shuffle consists on moving data with the same key to the one executor in order to execute some specific processing on it. We could think that it concerns only *ByKey operations but it's not necessarily true.
Another operation involving shuffle is join and it's the topic of this post. The first part explains this operation, called more specifically, a shuffle join. The second part shows how to use it in Spark code.
Shuffle join explained
Shuffle join, as every shuffle operation, consists on moving data between executors. At the end of that, rows from different DataFrames are grouped in a single place according to the keys defined in join operation. The following schema shows how the shuffle join performs. For illustration it takes the case of customers and orders, shown in learning tests in the second section:
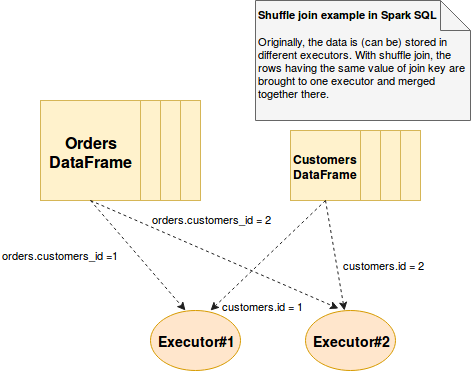
The shuffle join is the default one and is chosen when its alternative, broadcast join, can't be used. Concretely, the decision is made by the org.apache.spark.sql.execution.SparkStrategies.JoinSelection resolver. The shuffle join is made under following conditions:
- the join is not broadcastable (please read about Broadcast join in Spark SQL)
- and one of 2 conditions is met:
- either:
- sort-merge join is disabled (spark.sql.join.preferSortMergeJoin=false)
- the join type is one of: inner (inner or cross), left outer, right outer, left semi, left anti
- a single partition of given logical plan is small enough to build a hash table - small enough means here that the estimated size of physical plan for one of joined columns is smaller than the result of spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions. In other words, it's most worthwhile to hash and shuffle data than to broadcast it to all executors.
- according to the code comment, creating hash tables is costly and it can be only done when one of tables is at least 3 times smaller than the other. The "smaller" is often an estimation of the size of given relation, for instance:
- local relation (DataFrames created in memory) size is estimated as the sum of the sizes of all attributes multiplied by the number of rows. For instance, a DataFrame with 20 rows composed of an IntegerType and StringType has the total size of (8 + 20) * 20 (where 8 is the default size of an integer and 20 of a string)
- logical relation (e.g. the one representing database table - JDBCRelation) that, in addition to attributes size, default uses the value defined in spark.sql.defaultSizeInBytes property (Long.MaxValue). This value is large by default too block default broadcasting of relations that physically can represent a big table. If you are interested on some real-life example, go the test "sort merge join" should "be executed instead of shuffle when the data comes from relational database"
- or:
- join keys of left table aren't orderable, i.e. they're different than NullType, AtomicType and orderables StructType, ArrayType and UserDefinedType
- either:
Once shuffle join allowed, the join is performed through org.apache.spark.sql.execution.joins.ShuffledHashJoinExec class that calls org.apache.spark.sql.execution.joins.HashJoin#join(streamedIter: Iterator[InternalRow], hashed: HashedRelation, numOutputRows: SQLMetric). Inside, the rows of datasets are physically merged as JoinedRow instances. For example, the inner join has the following implementation:
private def innerJoin(
streamIter: Iterator[InternalRow],
hashedRelation: HashedRelation): Iterator[InternalRow] = {
val joinRow = new JoinedRow
val joinKeys = streamSideKeyGenerator()
streamIter.flatMap { srow =>
joinRow.withLeft(srow)
val matches = hashedRelation.get(joinKeys(srow))
if (matches != null) {
matches.map(joinRow.withRight(_)).filter(boundCondition)
} else {
Seq.empty
}
}
}
Shuffle join example
As you can see after reading the previous section, achieving shuffle join is not easy. The following tests show how it's touchy to deal with this join strategy:
val sparkSession: SparkSession = SparkSession.builder()
.appName("Spark shuffle join").master("local[*]")
.config("spark.sql.autoBroadcastJoinThreshold", "1")
.config("spark.sql.join.preferSortMergeJoin", "false")
.getOrCreate()
before {
InMemoryDatabase.cleanDatabase()
}
override def afterAll() {
InMemoryDatabase.cleanDatabase()
sparkSession.stop()
}
"much smaller table" should "be joined with shuffle join" in {
import sparkSession.implicits._
val inMemoryCustomersDataFrame = Seq(
(1, "Customer_1")
).toDF("id", "login")
val inMemoryOrdersDataFrame = Seq(
(1, 1, 50.0d, System.currentTimeMillis()), (2, 2, 10d, System.currentTimeMillis()),
(3, 2, 10d, System.currentTimeMillis()), (4, 2, 10d, System.currentTimeMillis())
).toDF("id", "customers_id", "amount", "date")
val ordersByCustomer = inMemoryOrdersDataFrame
.join(inMemoryCustomersDataFrame, inMemoryOrdersDataFrame("customers_id") === inMemoryCustomersDataFrame("id"),
"left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder)
})
// shuffle join is executed because:
// * the size of plan is greater than the size of broadcast join configuration (96 > 1):
// 96 because: IntegerType (4) + IntegerType (4) + DoubleType (8) + LongType (8)) * 3 = 24 * 4 = 96)
// * merge-sort join is disabled
// * the join type is inner (supported by shuffle join)
// * built hash table is smaller than the cost of broadcast (96 < 1 * 200, where 1 is spark.sql.autoBroadcastJoinThreshold
// and 200 is the default number of partitions)
// * one of tables is at least 3 times smaller than the other (72 <= 96, where 72 is the size of customers
// table*3 and 96 is the total place taken by orders table)
val queryExecution = ordersByCustomer.queryExecution.toString()
println(s"> ${queryExecution}")
queryExecution.contains("ShuffledHashJoin [customers_id#20], [id#5], LeftOuter, BuildRight") should be (true)
}
"when any of tables is at lest 3 times bigger than the other merge join" should "be prefered over shuffle join" in {
// This situation is similar to the previous one
// The difference is that the last column (timestamp) was removed from orders.
// Because of that, the size of orders decreases to 96 - 4 * 8 = 64
// Thus the criterion about the table at least 3 times bigger is not respected anymore.
import sparkSession.implicits._
val inMemoryCustomersDataFrame = Seq(
(1, "Customer_1")
).toDF("id", "login")
val inMemoryOrdersDataFrame = Seq(
(1, 1, 50.0d), (2, 2, 10d), (3, 2, 10d), (4, 2, 10d)
).toDF("id", "customers_id", "amount")
val ordersByCustomer = inMemoryOrdersDataFrame
.join(inMemoryCustomersDataFrame, inMemoryOrdersDataFrame("customers_id") === inMemoryCustomersDataFrame("id"),
"left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder)
})
val queryExecution = ordersByCustomer.queryExecution.toString()
println("> " + ordersByCustomer.queryExecution)
queryExecution.contains("ShuffledHashJoin [customers_id#20], [id#5], LeftOuter, BuildRight") should be (false)
queryExecution.contains("SortMergeJoin [customers_id#18], [id#5], LeftOuter") should be (true)
}
"sort merge join" should "be executed instead of shuffle when the data comes from relational database" in {
InMemoryDatabase.cleanDatabase()
JoinHelper.createTables()
val customerIds = JoinHelper.insertCustomers(1)
JoinHelper.insertOrders(customerIds, 4)
val OptionsMap: Map[String, String] =
Map("url" -> InMemoryDatabase.DbConnection, "user" -> InMemoryDatabase.DbUser, "password" -> InMemoryDatabase.DbPassword,
"driver" -> InMemoryDatabase.DbDriver)
val customersJdbcOptions = OptionsMap ++ Map("dbtable" -> "customers")
val customersDataFrame = sparkSession.read.format("jdbc")
.options(customersJdbcOptions)
.load()
val ordersJdbcOptions = OptionsMap ++ Map("dbtable" -> "orders")
val ordersDataFrame = sparkSession.read.format("jdbc")
.options(ordersJdbcOptions)
.load()
val ordersByCustomer = ordersDataFrame
.join(customersDataFrame, ordersDataFrame("customers_id") === customersDataFrame("id"), "left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder.toString())
})
// As explained in the post, the size of plan data is much bigger
// than accepted to make the shuffle join. It's because the default sizeInBytes
// used by JDBCRelation that is the same as the one used by
// org.apache.spark.sql.sources.BaseRelation.sizeInBytes:
// def sizeInBytes: Long = sqlContext.conf.defaultSizeInBytes
// Thus even if the size of our data is the same as in the first test where
// shuffle join was used, it won't be used here.
val queryExecution = ordersByCustomer.queryExecution.toString()
println("> " + ordersByCustomer.queryExecution)
queryExecution.contains("ShuffledHashJoin [customers_id#20], [id#5], LeftOuter, BuildRight") should be (false)
queryExecution.contains("SortMergeJoin [customers_id#6], [id#0], LeftOuter") should be (true)
}
Through two last sections we could discover one of Spark's join strategies - shuffle join. As this name suggests, this type uses shuffle operation to move joined data to the same executors. To do so, it generates as hash representation for each row that is later used to transfer them to appropriate places. However, at the 2nd section proved, it's not easy to setup the shuffle join - it uses hashing that is more costly operation than merge sort join or sometimes broadcast join.
