
Good write throughput and horizontal scalability are maybe the most visible advantages of NoSQL storage systems. However very often people with a solid RDBMS background fall in the trap of index that can't be so easily created. Fortunately, a lot of patterns helping to deal with this problem exist. One of them is the index table pattern.
This post presents the index table pattern as one of solutions to multiple access patterns problem. Its first section gives the context of this problem. The next part shows the concept of index table and makes an insight on its advantages and drawbacks. The last part shows its simple implementation in Cassandra.
Multiple access patterns
Some NoSQL databases are optimized to the access by key. The examples of such storage engines can be found very quickly: Cassandra, DynamoDB, HBase... Thus it's easy to work with them if we know exactly what we want to query (= we know the "primary key"). However the situation becomes more complicated when we start to have multiply access patterns. For instance instead of getting the customer by his ID we want to get all customers living in a given country. With the not reworked state of the data model in this engines, the only solution is the scan operation over all stored rows and filtering of the lines not matching the country predicate at query level. Unfortunately, this operation is costly and doesn't perform well.
But several alternatives exist and maybe the 2 most popular are index table and secondary index. Here we'll focus only on this first solution. The latter one will be described in one of further posts.
Index table pattern
The implementation of the index table pattern is straightforward and is illustrated in the following image:
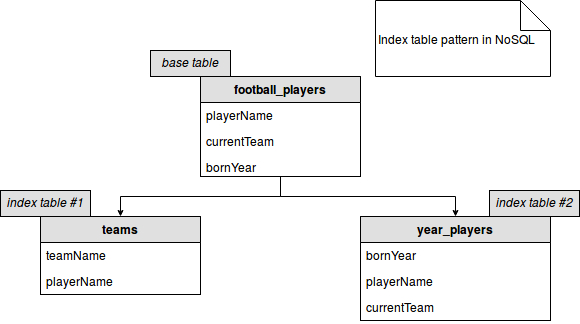
As you can see, the index tables are created from the information held by the base table. Each of index tables is optimized for given access pattern (all players of a given team, all players born in given year). The implementation above shows denormalized version of the index table because we simply duplicate the queryable values (team name, first and last names). But its normalized version exists too and is shown in the below image:
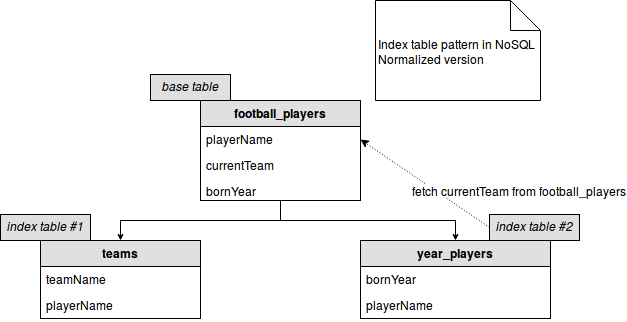
As you can see now, the YearPlayers table doesn't store the information about the current team of each player. Instead at reading time it'll retrieve it from FootballPlayers table through the row key. Thanks to that we can reduce the maintenance overhead and gain better consistency. But in the other side we'll probably slow down the queries because an additional lookup is required for every one selected line.
But index tables also have some drawbacks that we'd keep in mind before using them:
- index table table complexifies the architecture - after all we create an additional place where some copy of the original data is stored. This place, exactly as the original place, must be monitored and maintained
- no silver bullet - both normalized and denormalized versions have their drawbacks (less maintenance vs faster query)
- read eventual consistency - if no distributed transaction is provided we can end up with partially true values. For instance when they're correctly saved to the base table and only a half of them is duplicated to index table we'll end up with only a subset of valid data
- chose the index table column carefully - the index table is still a table, so it'd follow the same best practices as them, such as even distribution over nodes. Uneven distribution will obviously lead to slower query execution
Index table example
In order to see a simple implementation of the index table, let's take the example of FootballPlayers table and write it on Cassandra. First, the declaration of needed tables:
CREATE TABLE football_players (
playerName text,
currentTeam text,
bornYear int,
PRIMARY KEY (playerName)
)
CREATE TABLE teams (
teamName text,
playerName text,
PRIMARY KEY (teamName, playerName)
)
CREATE TABLE year_players (
bornYear int,
playerName text,
currentTeam text,
PRIMARY KEY (bornYear, playerName)
)
Now we can pass to learning tests and show some of possible behaviors:
@Test
public void should_add_player_to_all_3_tables() {
SESSION.execute("INSERT INTO football_players (playerName, currentTeam, bornYear) " +
" VALUES ('Pavel Nedved', 'Juventus Turin', 1972)");
SESSION.execute("INSERT INTO teams (teamName, playerName) " +
" VALUES ('Juventus Turin', 'Pavel Nedved')");
SESSION.execute("INSERT INTO year_players (bornYear, playerName, currentTeam) " +
" VALUES (1972, 'Pavel Nedved', 'Juventus Turin')");
ResultSet resultSetPlayers = SESSION.execute("SELECT * FROM football_players");
ResultSet resultSetTeams = SESSION.execute("SELECT * FROM teams");
ResultSet resultSetYears = SESSION.execute("SELECT * FROM year_players");
assertThat(resultSetPlayers.all()).hasSize(1);
assertThat(resultSetTeams.all()).hasSize(1);
assertThat(resultSetYears.all()).hasSize(1);
}
@Test
public void should_show_eventual_consistency_when_values_from_1_table_are_missing() {
SESSION.execute("INSERT INTO football_players (playerName, currentTeam, bornYear) " +
" VALUES ('Pavel Srnicek', 'Newcastle United', 1968)");
SESSION.execute("INSERT INTO teams (teamName, playerName) " +
" VALUES ('Newcastle United', 'Pavel Srnicek')");
ResultSet resultSet = SESSION.execute("SELECT * FROM year_players WHERE bornYear = 1968");
assertThat(resultSet.all()).isEmpty();
}
As proven, the index table pattern can be a solution for different access patterns. Its logic is quite simple - we only need to create n index tables with different partition keys, duplicate or not queried values and adapt the writing code to this new context. However, as listed in the 2nd section, this simplistic approach has also a lot of drawbacks, such as eventual consistency and architecture complexification. And as we'll see in one of next posts, the index table pattern is not a single solution for multiple access patterns.
