
Since the gain of popularity of cloud operators, serverless processing became one of serious alternatives to the cluster-based data pipelines. It's often cheaper to have event-based applications than different processings in the clusters. However, using serverless (and not only) in distributed and stateful computing can sometimes be difficult. But often one property can help in a lot of problems - idempotence.
This post explains how the idempotence can be useful in a sample serverless and stateful application. The first 2 sections introduce both discussed ideas. The next part explains the context of this post, i.e. the application with initially low consistency. The last part contains the code of this imaginary application with some tests illustrating the enhanced consistency.
Serverless processing
The serverless processing became popular thanks to cloud providers as AWS or Google. Unlike classical approach of data processing, the serverless doesn't take care of physical servers. Serverless functions are executed during the computation time (AWS limits this time to 5 minutes) somewhere in the cloud. Once the computation ends (or timeout is reached), they terminate and the used resources are freed. So the users don't need to care about the hardware installation. Often one of rare hardware considerations is the definition of expected amount of memory to use.
As it's easy to deduce, the serverless processing is by definition stateless - we can't store a state in memory because every time given function can be called on different server. But in the other side, it's possible to store the state in external storage with fast access characteristics (e.g. key-value storage).
Idempotence
Another important property in data processing is the idempotence. Simply speaking, we could tell that one function is idempotent if for multiple calls with the same arguments it always returns the same results. Formally speaking we can write it as: f(x) = f(f(x)). For instance, the function returning absolute value of the argument is idempotent: f(f(f-1)) will always be equal to 1. In the other side, the function returning random number is not idempotent.
In programming often we encounter the idempotence word in the context of RESTful services. For instance we have a client sending 10 consecutive DELETE requests to an endpoint. The first request will delete given resource, while subsequent ones will not. However, the DELETE operation is considered as idempotent since the state of the server doesn't change. For all 10 requests the server doesn't store deleted resource.
Another example of idempotence can be found in messaging. Idempotent messages are the simplest way to deal with duplicated messages. However, not all consumers can be idempotent. The most speaking example of that is money transfer request. If, by mistake, a message of crediting an account is sent twice, the client's balance will be credit twice and the bank will lose the money. The same problem occurs for withdrawal but in such case the client is losing.
The last but not the least point about idempotence concerns storage layer. If adding the same record multiple times produces at the end 1 new line in the database, we can consider the storage as idempotent. The example of this type of storage can be key-value data store where inserting new element for given key will always override the previous one. The counterexample of data storage idempotence is a relational database with auto-incremented column as primary key. In such case the fact of inserting given record several times will always add new line to the table.
Application context
Above theoretical introduction should help to understand the context. Our imaginary application collects the stats from the runners. The stats are sent by some physical device every 30 seconds. The message has JSON format and looks like in the following snippet:
{"user_id": 3000, "distance_meters": 199, "timestamp_utc": 1509547964734, "sequence_id": 2, "run_id": 3091019}
As you can see nothing strange or complicated. The goal of the application is to consume the message and derive from it the information valuable for the user. We'll face 2 problems: message sent more than once by the device and processing unexpected crashes. The architecture is presented in the following diagram in the example of AWS (disclaimer - the architecture is given only to provide a context for the exercise of enhancing consistency, it's clear that it could be done in several and better manners):
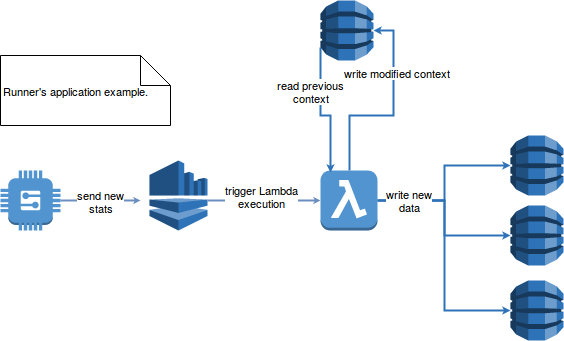
The Lambda function first retrieves previous execution context with the data required to generate new results. Thanks to this context the function sends updated context to the context table and generated stats to the remaining 3 tables representing:
- the user's tendency - table storing the information if the performs better or worse than his previous run (user_id as partition key, timestamp_utc as sort key, current performance and previous performance as columns)
- the stats for given run - total time, total distance (run_id as key, total_time and total_distance as columns)
- the backup of received messages for given user (user_id as partition key, timestamp_utc as sort key, message as column with JSON message)
Application's issues
As we can see, this application risks some issues. The first potential problem is inconsistent context. The inconsistency can occur in the case when the new context is saved and the rest of processing fails (e.g. because of Lambda execution timeout). The second problem can occur when the same message is mistakenly sent more than once by the device. Even if there is no processing issues, the final result will be inconsistent. Another problem can be caused by the network issues. Let's imagine that the message A is sent before the message B but the latter one arrives first to the Kinesis stream. If we don't take this complication into account, at the end the user can see his distance and exercise time decrease (= the last message always wins).
These problems can be eliminated in different ways but the simplest ones are: correct algorithm (steps, paradigm) and idempotent data storage. Let's explain:
- Inconsistent context problem - to solve this issue we can analyze all writing operations. As we can see, there are 4 operations: 1 writes the modified context table and 3 remaining write the user valuable information to user-related tables. In order to keep the context consistent, the write with modified context should be done at the end of all operations.
Moreover the function generating new aggregations should be idempotent. By being so it'll generate the same stats for given input message - even if some of these stats were already written to output DynamoDB tables. In our case is quite easy to achieve since we deal with idempotent sum operation and stronglt consistent context. - Message sent more than once by the device - naïvely we'd solve this issue with one more DynamoDB table storing the messages already processed for given user. The table, let's call id tracking_table, could be composed of 2 columns: user_id (user_id of JSON message) and message_hash (hashed content of the message). But this new table brings another problem - how to order the writes to guarantee strong consistency (using transactions is not conceivable) ? If first we write message to tracking_table and the rest of writes fail, we'll have at most once processing. If in the other side we'll write the information to tracking_table at the end, we'll have at least once processing.
A solution for that is the use of context table. Except context information used to generate user data we can add here a new column and store the sequence_id of already processed messages. - Message sent in disorder - this case will modify the strategy used by the aggregation algorithm. The messages arriving in disorder will be simply rejected and it won't change any aggregation stats.
To track the messages not arriving in the order of generation we can simply transform the column created in previous point. Now instead of keeping the ids of already seen messages it'll simply store the id of the last seen message. Thanks to that the aggregation algorithm will accept only the messages with the sequence_id greater than the last encountered sequence_id. It's possible here because the data generated by the application allows it - to compute the distance or the time of exercise we need only to know the most recent message and we can simply ignore previous ones. So if they arrive in disorder, we only need to know what is the most recent processed message. - Message saved twice - this problem can occur when the processing failed somewhere in the generation of user data. We'd have properly generated data saved more than once. But this issue can be solved easily and without any programming effort. The solution is brought by idempotent data storage. Thanks to it multiple writes of the same message will always result in a 1 line in the table.
To resume, the aggregation application's algorithm looks like in the following plan:
1. Get or initialize execution context (c) 2. Check if the message (m) can be processed within given context. 2.1. If no, stop the processing. 2.2. If yes, start the processing: 2.2.1. Apply aggregation function on data (x) and context, and return new user data with modified context: g(x, c) = (r, c') 2.2.2. Write new user data r 2.2.3. Update the context c'
Application with enhanced consistency
The analyze application with defined processing looks like in the snippet below:
class RunningProcessing(contextStore: ContextStore, outputStores: OutputStores) {
def process(inputData: InputData) = {
val context = contextStore.getContext(inputData.userId).getOrElse(createDefaultContext(inputData))
if (inputData.sequenceId > context.lastSequenceId) {
val totalMeters = context.distanceInMeters + inputData.distanceInMeters
val totalTime = inputData.timestampUtc - context.firstTimestampUtc
val aggregatedMetrics = AggregatedMetrics(totalMeters, totalTime)
outputStores.saveRunStats(inputData.runId, aggregatedMetrics)
val currentTendency = "good job"
// new tendency is saved in external table but it's also copied to the persisted context
// to prevent against processing given message more than once - but it's not an universal solution for all
// madness. Often the data stores limit the size of stored items. In this case we'd create a file with context
// information, save it on HDFS/S3 and put the path to the file in the table's column.
// However every time the processing will be impacted by the fact of loading this file.
outputStores.saveUserTendency(inputData.userId, inputData.timestampUtc, currentTendency, context.previousTendency)
outputStores.saveMessage(inputData.userId, inputData)
// It's important to save the execution context at the end
// The context brings the processing context so we can't write it elsewhere
// Otherwise we could not execute the function in the case of reprocessing the same input after a crash
// (context check is not valid but we've inconsistent stats in the tables)
val newContext = context.copy(lastSequenceId = inputData.sequenceId, distanceInMeters = totalMeters,
previousTendency = currentTendency)
contextStore.saveContext(newContext)
}
}
private def createDefaultContext(inputData: InputData): ExecutionContext = {
ExecutionContext(inputData.userId, inputData.sequenceId-1, 0, inputData.timestampUtc, "fine")
}
}
Nothing complicated and it was the goal. Now we can see the objects involved in the processing (stores and messages):
class ContextStore {
val contexts = mutable.Map[Int, ExecutionContext]()
def getContext(userId: Int): Option[ExecutionContext] = {
Some(contexts(userId))
}
def saveContext(executionContext: ExecutionContext): Unit = {
contexts(executionContext.userId) = executionContext
}
}
object InMemoryDataStore {
val stats = mutable.Map[Long, AggregatedMetrics]()
val messages = mutable.Map[Int, mutable.Map[Long, InputData]]().withDefaultValue(new mutable.HashMap[Long, InputData]())
val userTendencies = mutable.Map[Int, (Long, String, String)]()
}
class OutputStores {
def saveUserTendency(userId: Int, timestampUtc: Long, currentPerformance: String, previousPerformance: String) = {
InMemoryDataStore.userTendencies(userId) = (timestampUtc, currentPerformance, previousPerformance)
}
def saveRunStats(runId: Long, aggregatedMetrics: AggregatedMetrics) = {
InMemoryDataStore.stats(runId) = aggregatedMetrics
}
def saveMessage(userId: Int, message: InputData): Unit = {
InMemoryDataStore.messages(userId)(message.timestampUtc) = message
}
}
case class InputData(userId: Int, runId: Long, timestampUtc: Long, distanceInMeters: Int, sequenceId: Int)
case class AggregationContext(distanceInMeters: Int)
case class AggregatedMetrics(totalMeters: Int, totalTimeMillis: Long)
case class ExecutionContext(userId: Int, lastSequenceId: Int, distanceInMeters: Int, firstTimestampUtc: Long,
previousTendency: String)
Here too we see any complication. The tests were written in similar, self-explanatory spirit:
class IdempotenceTest extends FlatSpec with Matchers with BeforeAndAfter {
private val MessageTimestampUtc = 1509559388000L
private val Message = InputData(1, 1000L, MessageTimestampUtc, 120, 5)
private val MinuteInMillis = 60*1000
before {
clearContext()
}
after {
clearContext()
}
private def clearContext(): Unit = {
InMemoryDataStore.messages.clear()
InMemoryDataStore.stats.clear()
InMemoryDataStore.userTendencies.clear()
}
"duplicated message" should "not be processed twice" in {
val previousMessageTimestampUtc = MessageTimestampUtc - 10*MinuteInMillis
val existentContext = ExecutionContext(Message.userId, Message.sequenceId-1, 150, previousMessageTimestampUtc, "fine")
val contextStore = new ContextStore()
contextStore.contexts(Message.userId) = existentContext
val outputStore = new OutputStores()
val processing = new RunningProcessing(contextStore, outputStore)
processing.process(Message)
// Change timestamp only to see if it's written twice
processing.process(Message.copy(timestampUtc = -1L))
InMemoryDataStore.messages(Message.userId).size shouldEqual 1
InMemoryDataStore.messages(Message.userId)(Message.timestampUtc) shouldEqual Message
InMemoryDataStore.stats(Message.runId).totalMeters shouldEqual 270
InMemoryDataStore.stats(Message.runId).totalTimeMillis shouldEqual 10*MinuteInMillis
InMemoryDataStore.userTendencies(Message.userId) shouldEqual (Message.timestampUtc, "good job", "fine")
}
"message making processing fail" should "not produce inconsistent state" in {
val previousMessageTimestampUtc = MessageTimestampUtc - 10*MinuteInMillis
val existentContext = ExecutionContext(Message.userId, Message.sequenceId-1, 150, previousMessageTimestampUtc, "well done")
val contextStore = new ContextStore()
contextStore.contexts(Message.userId) = existentContext
val outputStore = Mockito.spy(new OutputStores())
// saveMessage is before the last writing operation
// So it's a good place to test data consistency after an unexpected crash
Mockito.when(outputStore.saveMessage(Message.userId, Message)).thenThrow(classOf[IllegalStateException])
val processing = new RunningProcessing(contextStore, outputStore)
try {
processing.process(Message)
} catch {
case _: IllegalStateException => {
println("IllegalStateException thrown as expected")
}
}
val retriedProcessing = new RunningProcessing(contextStore, new OutputStores())
retriedProcessing.process(Message)
InMemoryDataStore.messages(Message.userId).size shouldEqual 1
InMemoryDataStore.messages(Message.userId)(Message.timestampUtc) shouldEqual Message
InMemoryDataStore.stats(Message.runId).totalMeters shouldEqual 270
InMemoryDataStore.stats(Message.runId).totalTimeMillis shouldEqual 10*MinuteInMillis
InMemoryDataStore.userTendencies(Message.userId) shouldEqual (Message.timestampUtc, "good job", "well done")
}
}
The idempotent operations and data storage can help to write simple and functional data processing code. As we could see above, the idempotent function guarantees the same processing results for given input message. It's more difficult to achieve for the stateful applications since the context must be written in correct order regarding to the processing. But idempotent function is not the single requirement. In order to work we'd also be able to store the computation results in idempotent manner - i.e. the consecutive writings of the same message should always produce 1 and the same result in the data store.
This post gives an example on how to use idempotence in data processing applications in (by definition) stateless serverless functions. But it also emphasizes the importance of idempotent operations and gives some simple pattern to the work with stateful operations thanks to this property.
