
One of approaches to load big volumes of data efficiently is to use bulk operations. The idea is to take all the records and put them into data store at once. For this purpose, AWS Redshift exposes an operation called COPY.
The post has 4 sections and explains some properties of COPY operation. The first part briefly describes the command. The second part shows how to use it with custom schemas. The next one explains how to handle default values for columns whereas the last one focuses on managing errors.
COPY 101
COPY command is AWS Redshift convenient method to load data in batch mode. AWS advises to use it to loading data into Redshift alongside the evenly sized files. Since Redshift is a Massively Parallel Processing database, you can load multiple files in a single COPY command and let the data store to distribute the load:
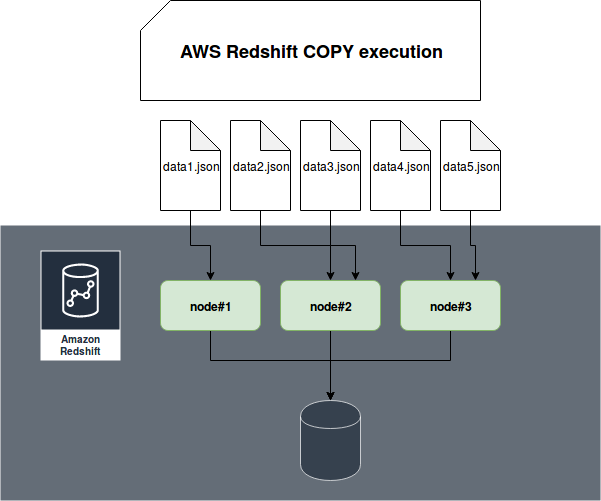
To execute COPY command, you must define at least: a target table, a source file(s) and an authorization statement. An example that you can find on the documentation is:
copy mytable from 's3://mybucket/file.txt' iam_role 'arn:aws:iam:::role/ ' region 'us-west-2';
During the execution Redshift will not only distribute the load for input file(s) but also load everything from the files into a table. If any inconsistency is detected, like mismatched schema, the loading will fail. Well, this is not always true and I will show you some exceptions in the 3 following sections.
Custom schemas
The first feature presented here addresses the case when your table schema doesn't match the structure of your input files. It will be likely to happen if you're integrating data from different 3rd party systems which don't share the same naming conventions. For instance, System A can define delivery address in "delivery_address" field whereas a System B can represent this value in the "address" field. How to deal with that situation? First, we can create a table, load data to it and expose the data through a VIEW with correctly named fields. But we can also do it differently with the help of JSON schemas and not duplicate use the view.
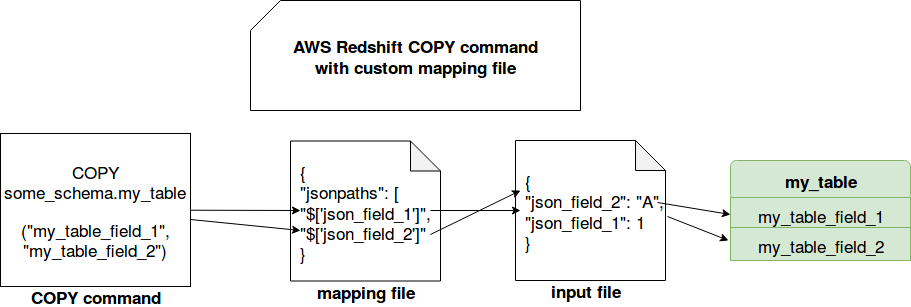
To get a better understanding of JSON schemas, let's suppose that we have the following command to execute (meaningfulness parts are commented with "#..."):
COPY some_schema.my_table ( "my_table_field_1", "my_table_field_2" ) # ... FORMAT AS JSON 's3://my_bucket/my_table/copy/mapping.json' # ...
As you can see here, we define some extra parameters. The first one is the list of columns of the table that we want to extract from loaded JSON files. The second one is a mapping file looking like this:
{
"jsonpaths": [
"$['json_field_1']",
"$['json_field_2']",
}
The reason of adding mapping file is that the input JSON is structured like:
{"json_field_1": 1, "json_field_2": "A"}
{"json_field_1": 2, "json_field_2": "B"}
Thanks to the list of the columns directly after the COPY operator, and the mapping file, Redshift will conciliate both. Otherwise, it would expect to find "my_table_field_1, my_table_field_2" in the JSON data file.
Defaults
For the second use case let's imagine a situation where we want to create a column whose values will be set only by Redshift's DEFAULT operation. For instance, we can use it to track loading time:
loading_time_utc DATETIME DEFAULT NOW()
How to fill this value? Once again, the query from the second part will be helpful. By defining a list of columns you're saying Redshift to retrieve all specified values in the mapping file and to consider the remaining ones are missing. Since our column has a default value defined, we don't need to specify it in the mapping and schema files.
Errors flexibility
Depending on your use case, you can accept some threshold of errors during the loading. Here I will discuss 2 parts where you can apply it. The first one concerns data and is controlled by MAXERROR. This property defines how many errors are allowed during the load. An "error" here is considered as, for instance, a too long or an incorrectly formatted field. If the number of errors reaches the value defined in this property, the COPY operation fails. Otherwise, it succeeds and returns all errors as logs in the console.
The second property concerns manifest file. A manifest file is a list of all files that should be loaded into Redshift so it will help to ensure consistency of the operation. It can also be useful when the files to load are mixed with other files and, therefore, using a prefix would be difficult. However, a manifest file can also be a source of errors. By default all files listed in the file are optional but if you change this property to required and the file is missing, the COPY operation can fail. Below you can find an example of a manifest file with mandatory and optional files:
{"entries":[
{"url": "s3://my-bucket/file1.json,"mandatory": true},
{"url": "s3://my-bucket/file2.json,"mandatory": true},
{"url": "s3://my-bucket/file3.json,"mandatory": false}
]}
COPY command is hard to summarize in short 4 sections. However, they should already give you some input about the capabilities of this operation. As you can see, you can simply load a bunch of files from a prefix, customize the mapping between file and database, and also control failures behavior.
