
During the years Apache Spark's streaming was perceived as working with micro-batches. However, the release 2.3.0 tries to change this and proposes a new execution model called continuous. Even though it's still in experimental status, it's worthy to learn more about it.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post describes the new experimental feature of the continuous streaming processing. The first part explains and compares it with the micro-batch execution strategy. The next one shows some internals details. In the third part we can learn about at-least-once guarantee. The final section shows a simple continuous execution use case on the example of rate-based source.
Continuous streaming
After all why replace the distinguish mark of Spark that is micro-batch processing (unlike Apache Flink or Apache Beam that allow continuous streaming processing) ? The answer is simple - latency. With the micro-batch implementation, the latency was high. In the worst case, the latency was the sum of the batch time and the task launching time and was estimated to houndreds of milliseconds. The continuous processing reduces the latency between data arrival and its processing to some milliseconds. The latency decrease was the primary motivation behind this (still) experimential feature.
From the bird's eye view the continuous query is executed in multiple threads. Each of them is responsible for different partition. Thus to guarantee the best parallelism, the number of available cores in the cluster must be equal to the number of partitions to process. During the processing the results are written by these threads continuously to the result table.
Technically speaking the continuous processing is enabled with continuous trigger through .trigger(Trigger.Continuous("1 second")). But it's important to emphasize that not all operations are exposed to this mode in the current (2.3.0) Spark version. Among the available transformations we can distinguish only the projections (select, mapping functions) and selections (filter clauses).
However, the lower latency doesn't came without costs. In fact faster processing decreases the delivery guarantees to at-least-once from exactly-once. So the continuous execution is advised for the systems where the processing latency is more important than the delivery guarantee.
ContinuousExecution class
Initially in structured streaming the StreamExecution contained the whole execution logic. Only in the 2.3.0 version it became an abstract class extended by MicroBatchExecution and ContinuousExecution. The departure point for both classes is org.apache.spark.sql.execution.streaming.StreamExecution#runStream() that after some initialization steps activates the streaming query implemented in each of execution strategies as runActivatedStream(sparkSessionForStream: SparkSession) method.
The ContinuousExecution runs the query continuously thanks to the following code:
do {
runContinuous(sparkSessionForStream)
} while (state.updateAndGet(stateUpdate) == ACTIVE)
Inside this runContinuous method a lot of operations happen. The first of them consists on transforming the query logical plan into a sequence of ContinuousReaders. This interface defines if given data source can be read in continuous manner. Currenty only Apache Kafka and rate-based source are supported (a source generating X (timstamp, counter) rows per seconds at regular Y interval where X and Y are configuration parameters). If some of sources or operations don't support continuous mode, an UnsupportedOperationException is thrown before launching the query.
After the source creation the starting offsets are resolved to determine when the processing will begin for given execution. If the query is launched for the first time, the offsets are naturally empty. However, when the query is executed once again, the offsets are retrieved from the commit log. Later an instance of StreamingDataSourceV2Relation is created for each of data sources mapped to the read offsets. Next the data reader and writer are created and the execution plan is generated exactly the same way as in the micro-batch approach.
In the next step the engine plays with epochs (= similar to batch in micro-batch processing) through the EpochCoordinator instance. It's a master piece of the continuous processing. This RPC endpoint is responsible for handling the following messages:
- generating new epoch id - through the message IncrementAndGetEpoch the epoch id is atomically incremented. The new value is then returned in the runContinuous method.
- returning the current epoch id - this getter message represented as an instance of GetCurrentEpoch is used by the thread executing periodically the logic defined in EpochPollRunnable. In this logic the engine retrieves the currently known epoch and adds it to an internal queue of the messages to process. It will be detailed better in the schema below this list.
- committing partition under the epoch - when the processing of the partitions in given epoch terminates, the CommitPartitionEpoch message is sent to the EpochCoordinator to signal this fact. If all of epoch's partitions are processed the ContinuousExecution marks this epoch as committed. It means that the epoch is persisted to the commit log and in the case of reprocessing the offsets associated with it are used as the starting ones (see the previous paragraph).
These continuous processing logic involving epoch coordinator can be resumed in the following simplified schema:
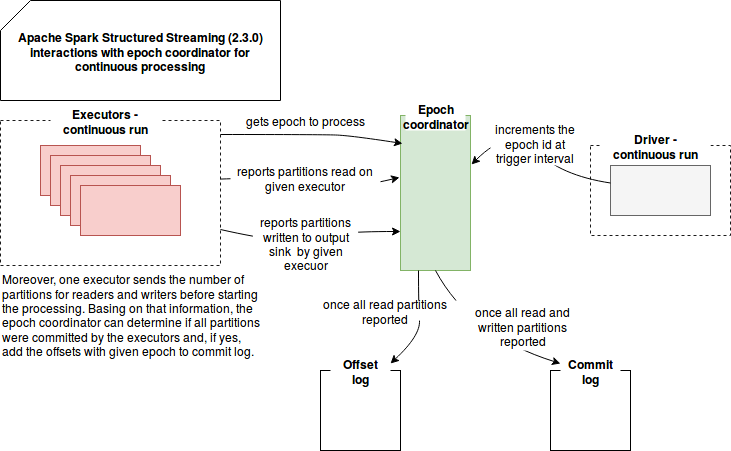
At-least-once guarantee
You may wonder why the continuous mode is at-least-once guarantee ? As already mentioned, the main rationale is about the decreased latency. In the code it's translated in the moment where the starting offsets are resolved for each source. You can see this in the following schema showing the first moments of execution for micro-batch and continuous processing:
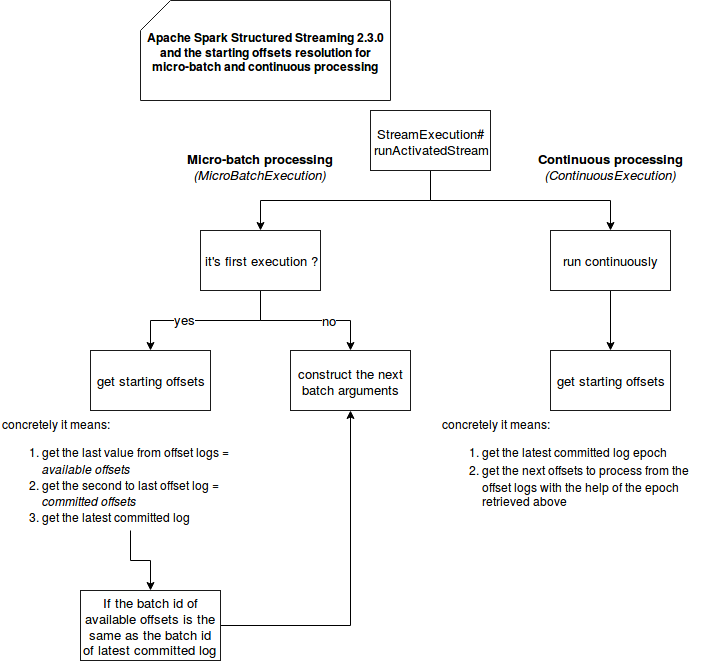
As you can see, the starting offsets generation is slightly different for both modes. The micro-batch processing is based on both offset and commit logs while the continuous one uses only committed log. From the writing part (not shown in the picture), the offsets are always persisted before the commit log. The latter one is saved only after the successful processing of given epoch or micro-batch. Seeing that the writing workflow is the same for both kinds of processing, the difference in reading part highlights the at-least-once guarantee in continuous strategy.
To understand it better nothing better than an example. Let's say that that the last batch/epoch id in commit logs is #2 and that it corresponds to the offsets (4, 5, 6) (= 3 Kafka partitions). The most recent values in offset logs are (7, 8, 9) and they correspond to the batch/epoch #3. Now, the continuous execution reads the commit log and see the last epoch #2. It retrieves then the offsets corresponding to it ((4, 5, 6)). So it'll reprocess the (4, 5, 6). The micro-batch execution does more steps. First it gets the last offsets logs ((7, 8, 9)). Next it compares them with the last committed offsets ((4, 5, 6)). Since both have different batch id, the offsets corresponding to the most recent batch id are kept for the processing.
Offsets nuance
In fact Apache Spark Structured Streaming deals with offset ranges composed of: start offset (inclusive) and end offset (exclusive). The end offset is used as the starting point in the next processing. You can see that for intance in org.apache.spark.sql.kafka010.KafkaSource#getBatch that according to the comment: "Returns the data that is between the offsets [`start.get.partitionToOffsets`, `end.partitionToOffsets`), i.e. end.partitionToOffsets is exclusive."
The single values from above example was given only to simplify the case.
Continuous processing example
The use case presented in the following snippet presents shortly the continuous processing:
"continuous execution" should "execute trigger at regular interval independently on data processing" in {
val messageSeparator = "SEPARATOR"
val logAppender = InMemoryLogAppender.createLogAppender(Seq("New epoch", "has offsets reported from all partitions",
"has received commits from all partitions. Committing globally.", "Committing batch"),
(loggingEvent: LoggingEvent) => LogMessage(s"${loggingEvent.timeStamp} ${messageSeparator} ${loggingEvent.getMessage}", ""))
val rateStream = sparkSession.readStream.format("rate").option("rowsPerSecond", "10")
.option("numPartitions", "2")
val numbers = rateStream.load()
.map(rateRow => {
// Slow down the processing to show that the epochs don't wait commits
Thread.sleep(500L)
""
})
numbers.writeStream.outputMode("append").trigger(Trigger.Continuous("2 second")).format("memory")
.queryName("test_accumulation").start().awaitTermination(60000L)
// A sample output of accumulated messages could be:
// 13:50:58 CET 2018 : New epoch 1 is starting.
// 13:51:00 CET 2018 : New epoch 2 is starting.
// 13:51:00 CET 2018 : Epoch 0 has offsets reported from all partitions: ArrayBuffer(
// RateStreamPartitionOffset(1,-1,1521958543518), RateStreamPartitionOffset(0,-2,1521958543518))
// 13:51:00 CET 2018 : Epoch 0 has received commits from all partitions. Committing globally.
// 13:51:01 CET 2018 : Committing batch 0 to MemorySink
// 13:51:01 CET 2018 : Epoch 1 has offsets reported from all partitions: ArrayBuffer(
// RateStreamPartitionOffset(0,24,1521958546118), RateStreamPartitionOffset(1,25,1521958546118))
// 13:51:01 CET 2018 : Epoch 1 has received commits from all partitions. Committing globally.
// 13:51:01 CET 2018 : Committing batch 1 to MemorySink
// 13:51:02 CET 2018 : New epoch 3 is starting.
// 13:51:04 CET 2018 : New epoch 4 is starting.
// 13:51:06 CET 2018 : New epoch 5 is starting.
// 13:51:08 CET 2018 : New epoch 6 is starting.
// As you can see, the epochs start according to the defined trigger and not after committing given epoch.
// Even if given executor is in late for the processing, it polls the information about the epochs regularly through
// org.apache.spark.sql.execution.streaming.continuous.EpochPollRunnable
var startedEpoch = -1
var startedEpochTimestamp = -1L
for (message <- logAppender.getMessagesText()) {
val Array(msgTimestamp, messageContent, _ @_*) = message.split(messageSeparator)
if (messageContent.contains("New epoch")) {
// Here we check that the epochs are increasing
val newEpoch = messageContent.split(" ")(3).toInt
val startedNewEpochTimestamp = msgTimestamp.trim.toLong
newEpoch should be > startedEpoch
startedNewEpochTimestamp should be > startedEpochTimestamp
startedEpoch = newEpoch
startedEpochTimestamp = startedNewEpochTimestamp
} else if (messageContent.contains("Committing globally")) {
// Here we prove that the epoch commit is decoupled from the starting of the new
// epoch processing. In fact the new epoch starts according to the delay defined
// in the continuous trigger but the commit happens only when all records are processed
// And both concepts are independent
val committedEpoch = messageContent.split(" ")(2).toInt
startedEpoch should be > committedEpoch
msgTimestamp.trim.toLong should be > startedEpochTimestamp
}
}
}
The continuous processing is another interesting solution proposed by Apache Spark to the community. With the classical micro-batch-oriented execution, the streaming processing has exactly-once-guarantee. However as shown in the first section, the cost of it is the latency. The continuous processing is an alternative approach that sacrifies the exactly-once-guarantee to decrease the latency. As presented in 2 next parts, it passes by splitting StreamExecution class into 2 classes representing each of strategies. In the case of continuous execution, the difference consists on offsets resolution. It's based only on commit logs while in the case of micro-batch, a mix of offset and commit logs is used to reduce unecessary reprocessing. The last section presented a simple test case with the use of continuous execution.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Continuous execution in Apache Spark Structured Streaming here:
- SPIP: Continuous Processing Mode for Structured Streaming How to get Kafka offsets for structured query for manual and reliable offset management?
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
Deep look at the continuous processing in #ApacheSpark #StructuredStreaming; code internals, delivery guarantees and a small example at the end: https://t.co/imqa4c5KSe
— bardev (@waitingforcode) March 25, 2018