
Recently we discovered the concept of state stores used to deal with stateful aggregations in Structured Streaming. But at that moment we didn't spend the time on these aggregations. As promised, they'll be described now.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post begins with a short comparison between aggregations and stateful aggregations. Directly after the article ends with some tests illustrating the stateful aggregations.
Aggregations vs stateful aggregations
An aggregation is the operation computing a single value from multiple values. In Apache Spark an example of this kind of operation can be count or sum method. In the context of the streaming applications we talk about stateful aggregations, i.e. aggregations having a state those value evolves incrementally during the time.
After the explanations given for output modes, state store and triggers in Structured Streaming, it'd be easier to understand the specificity of the stateful aggregations. As told, the output modes determines not only the amount of the data but also, if used with watermark, when the intermediary state can be dropped. All these intermediary state is then persisted in a fault-tolerant state store. The state computation is executed at regular interval by the triggers for the data accumulated from the last trigger execution The following schema shows how all these part work together:
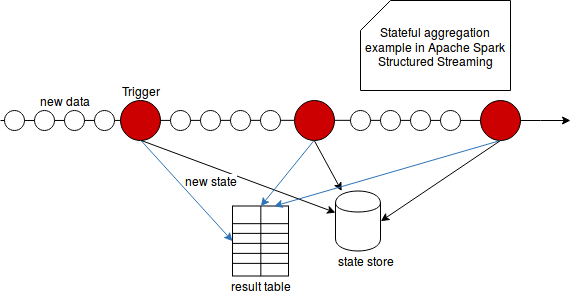
Thus to make it simple we could define the stateful aggregation as an aggregation those result evolves in time. The results computation is launched by the trigger and saved in the state store from where it can be dropped after the processed data passes before the watermark (if defined).
Stateful aggregation examples
Two tests show the stateful aggregation in Apache Spark Structured Streaming:
"stateful count aggregation" should "succeed after grouping by id" in {
val testKey = "stateful-aggregation-count"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.groupBy("id")
.agg(count("*"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("id")} -> ${row.getAs[Long]("count(1)")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, "a1"), (1, "a2"), (2, "b1"))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, "b2"), (2, "b3"), (2, "b4"), (1, "a3"))
}
}).start()
query.awaitTermination(25000)
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 4
readValues should contain allOf("1 -> 2", "2 -> 1", "1 -> 3", "2 -> 4")
}
"sum stateful aggregation" should "be did with the help of state store" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val testKey = "stateful-aggregation-sum"
val inputStream = new MemoryStream[(Long, Long)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "revenue")
.groupBy("id")
.agg(sum("revenue"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("id")} -> ${row.getAs[Double]("sum(revenue)")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, 10), (1, 11), (2, 20))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, 21), (2, 22), (2, 23), (1, 12))
}
}).start()
query.awaitTermination(35000)
// The assertions below show that the state is involved in the execution of the aggregation
// The commit messages are the messages like:
// Committed version 1 for HDFSStateStore[id=(op=0,part=128),
// dir=/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128] to file
// /tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/128/1.delta
val commitMessages = logAppender.getMessagesText().filter(_.startsWith("Committed version"))
commitMessages.filter(_.startsWith("Committed version 1 for HDFSStateStore")).nonEmpty shouldEqual(true)
commitMessages.filter(_.startsWith("Committed version 2 for HDFSStateStore")).nonEmpty shouldEqual(true)
// Retrieval messages look like:
// Retrieved version 1 of HDFSStateStoreProvider[id = (op=0, part=0),
// dir = /tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state/0/0] for update
// (org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider:54)
// It proves that the state is updated (new state is stored when new data is processed)
val retrievalMessages = logAppender.getMessagesText().filter(_.startsWith("Retrieved version"))
retrievalMessages.filter(_.startsWith("Retrieved version 0 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
retrievalMessages.filter(_.startsWith("Retrieved version 1 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
// The report messages show that the state is physically loaded. An example of the message looks like:
// Reported that the loaded instance StateStoreId(/tmp/temporary-6cbcad4e-70aa-4691-916c-cfccc842716b/state,0,3)
// is active (org.apache.spark.sql.execution.streaming.state.StateStore:58)
val reportMessages = logAppender.getMessagesText().filter(_.startsWith("Reported that the loaded instance"))
reportMessages.filter(_.endsWith("state,0,1) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,2) is active")).nonEmpty shouldEqual(true)
reportMessages.filter(_.endsWith("state,0,3) is active")).nonEmpty shouldEqual(true)
// The stateful character of the processing is also shown through the
// stateful operators registered in the last progresses of the query
// Usual tests on the values
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 4
readValues should contain allOf("2 -> 20", "1 -> 21", "1 -> 33", "2 -> 86")
}
"stateful count aggregation" should "succeed without grouping it by id" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("Retrieved version",
"Reported that the loaded instance StateStoreId", "Committed version"))
val testKey = "stateful-aggregation-count-without-grouping"
val inputStream = new MemoryStream[(Long, String)](1, sparkSession.sqlContext)
val aggregatedStream = inputStream.toDS().toDF("id", "name")
.agg(count("*").as("all_rows"))
val query = aggregatedStream.writeStream.trigger(Trigger.ProcessingTime(1000)).outputMode("update")
.foreach(
new InMemoryStoreWriter[Row](testKey, (row) => s"${row.getAs[Long]("all_rows")}"))
.start()
new Thread(new Runnable() {
override def run(): Unit = {
inputStream.addData((1, "a1"), (1, "a2"), (2, "b1"))
while (!query.isActive) {}
Thread.sleep(2000)
inputStream.addData((2, "b2"), (2, "b3"), (2, "b4"), (1, "a3"))
}
}).start()
query.awaitTermination(25000)
// We can see that the same assertions as for the previous test pass. It means that the
// stateful aggregation doesn't depend on the presence or not of the groupBy(...) transformation
val commitMessages = logAppender.getMessagesText().filter(_.startsWith("Committed version"))
commitMessages.filter(_.startsWith("Committed version 1 for HDFSStateStore")).nonEmpty shouldEqual(true)
commitMessages.filter(_.startsWith("Committed version 2 for HDFSStateStore")).nonEmpty shouldEqual(true)
val retrievalMessages = logAppender.getMessagesText().filter(_.startsWith("Retrieved version"))
retrievalMessages.filter(_.startsWith("Retrieved version 0 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
retrievalMessages.filter(_.startsWith("Retrieved version 1 of HDFSStateStoreProvider")).nonEmpty shouldEqual(true)
val reportMessages = logAppender.getMessagesText().filter(_.startsWith("Reported that the loaded instance"))
reportMessages.filter(_.endsWith("state,0,0) is active")).nonEmpty shouldEqual(true)
val readValues = InMemoryKeyedStore.getValues(testKey)
readValues should have size 2
readValues should contain allOf("3", "7")
}
This short post was the resume of the stateful data processing in Apache Spark Structured Streaming. After discovering the output modes, state store and triggers, we learned something more about the stateful aggregations. And in fact they are no much different than the stateless aggregations. The main difference consists on the fact that the computed values can change in the subsequent query executions, as shown in the first test from the 2nd section. And those intermediary results are stored in already described state store, what was proved in the second test from the same section.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Stateful aggregations in Apache Spark Structured Streaming here:
Related blog posts:
#ApacheSparkStructuredStreaming post about stateful aggregations summarizing output modes, triggers and state store - https://t.co/O0E5FHV8bX
— bardev (@waitingforcode) March 18, 2018