
Apache Spark leverages the observer design pattern for the framework-to-code communication. One of the consumers' implementations is StreamingQueryListener.
Query states
StreamingQueyrListener is an interface with 4 methods. Each of them corresponds to a dedicated state of the streaming query:
- onQueryStarted triggered when the query starts
- onQueryProgress triggered whenever the query makes progress
- onQueryIdle triggered whenever the query waits for the new data to process
- onQueryTerminated triggered when the query stops or fails
There are one important difference between these 4 events, the execution mode. The onQueryStarted is the single synchronous execution meaning that it blocks the progress as long as it's running. This difference is visible in the StreamingQueryListenerBus:
def post(event: StreamingQueryListener.Event): Unit = {
event match {
case s: QueryStartedEvent =>
activeQueryRunIds.synchronized { activeQueryRunIds += s.runId }
sparkListenerBus.foreach(bus => bus.post(s))
// post to local listeners to trigger callbacks
postToAll(s)
case _ =>
sparkListenerBus.foreach(bus => bus.post(event))
}
}
abstract class StreamingQueryListener extends Serializable {
import StreamingQueryListener._
/**
* Called when a query is started.
* @note This is called synchronously with
* [[org.apache.spark.sql.streaming.DataStreamWriter `DataStreamWriter.start()`]],
* that is, `onQueryStart` will be called on all listeners before
* `DataStreamWriter.start()` returns the corresponding [[StreamingQuery]]. Please
* don't block this method as it will block your query.
* @since 2.0.0
*/
def onQueryStarted(event: QueryStartedEvent): Unit
As you can see in the snippet above, all the events but QueryStartedEvent are a part of a fire-and-forget execution mode, hence asynchronous. For the QueryStartedEvent one, the listener bus waits for the listeners execution results before resuming the data processing.
It implies 2 things. First, the blocking event will lock the query progress. If you have any listeners implemented doing some heavy setup job in this step, it can explain why your first processing job instance is slower than the others. Second, the non-blocking character of the remaining events implies that they don't follow the query processing frequency. Let's understand it better with an example.
Your micro-batch processes data in 20-30 seconds. One listener does some quick task as a part of the onQueryProgress handler and it takes 5-10 seconds. In that scenario, you can consider your listener being a part of the job as each micro-batch should have the progress handler executed. Now, if you reverse these numbers, the listener is slower than each job. As a result, due to its asynchronous character and execution time, there is no 1-to-1 execution model between them.
Execution flow
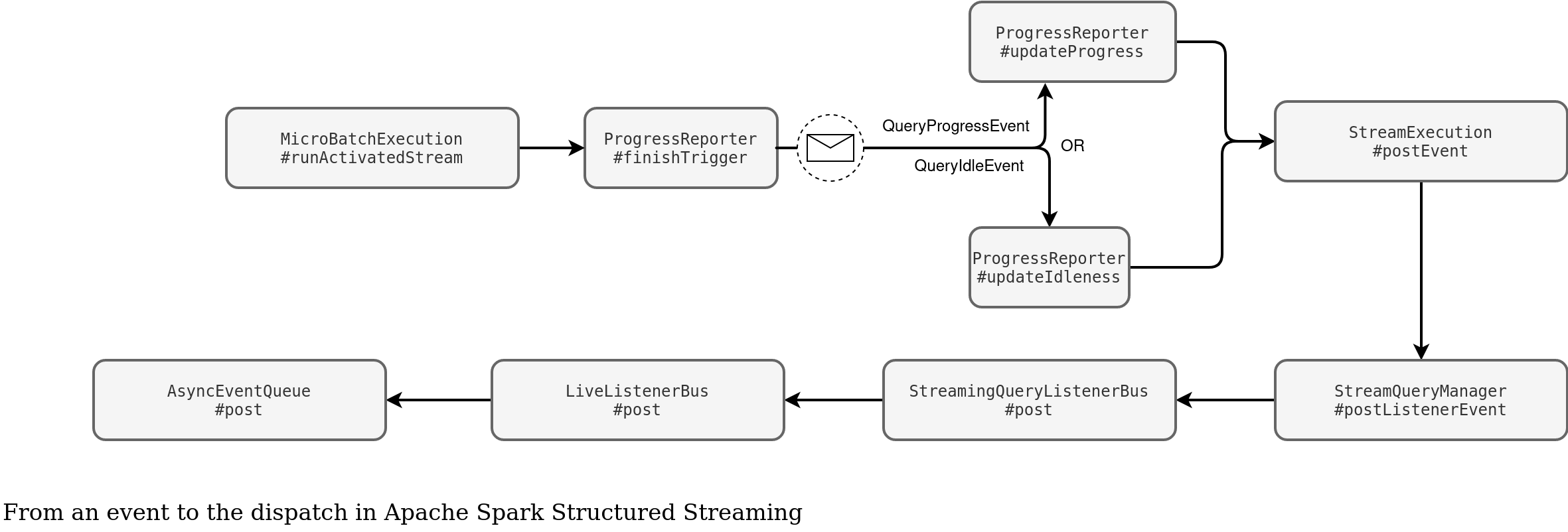
That's the execution flow schema for the events of a running query. As you can see, whenever a trigger completes, the execution class classifies the run either as a data processing, or an idle one. The former case summarizes the execution stats and invokes the updateProgress handler whereas the latter calls the updateIdleness callback. Next, both pass the event message to the underlying message bus.
The handler's invocation is asynchronous:
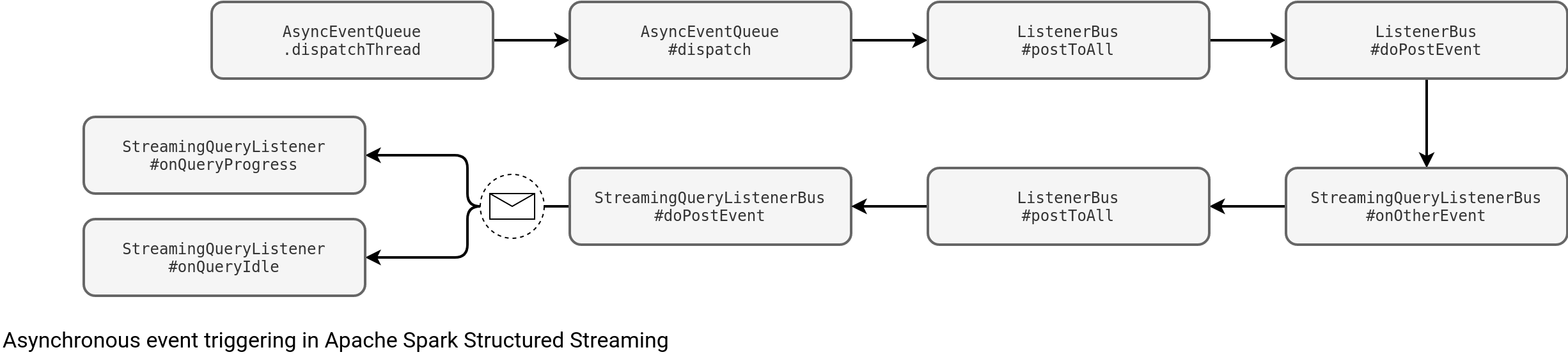
More specifically, the last branch of the graph above is located here::
class StreamingQueryListenerBus(sparkListenerBus: Option[LiveListenerBus])
extends SparkListener with ListenerBus[StreamingQueryListener, StreamingQueryListener.Event] {
// ...
override protected def doPostEvent(listener: StreamingQueryListener, event: StreamingQueryListener.Event): Unit = {
event match {
case queryStarted: QueryStartedEvent =>
if (shouldReport(queryStarted.runId)) {
listener.onQueryStarted(queryStarted)
}
case queryProgress: QueryProgressEvent =>
if (shouldReport(queryProgress.progress.runId)) {
listener.onQueryProgress(queryProgress)
}
case queryIdle: QueryIdleEvent =>
if (shouldReport(queryIdle.runId)) {
listener.onQueryIdle(queryIdle)
}
case queryTerminated: QueryTerminatedEvent =>
if (shouldReport(queryTerminated.runId)) {
listener.onQueryTerminated(queryTerminated)
}
case _ =>
}
}
Listener too slow
So, what happens when your listener is too slow? Good news here, as it's asynchronous, it shouldn't impact your data workflow. It shouldn't because it can indeed have some negative impact if the listener's action uses too many cluster resources which become unavailable for your processing job.
But what happens with the progress events recorded while your slow listener is running? Eventually, the listener will consume them. Eventually because the underlying queues storing events have a static capacity. If there are some events remaining for processing, the queue won't accept them and you should see dropping messages in the logs:
private class AsyncEventQueue( ///...
private val eventQueue = new LinkedBlockingQueue[SparkListenerEvent](capacity)
def post(event: SparkListenerEvent): Unit = {
if (stopped.get()) {
return
}
eventCount.incrementAndGet()
if (eventQueue.offer(event)) {
return
}
eventCount.decrementAndGet()
droppedEvents.inc()
droppedEventsCounter.incrementAndGet()
if (logDroppedEvent.compareAndSet(false, true)) {
// Only log the following message once to avoid duplicated annoying logs.
logError(s"Dropping event from queue $name. " +
"This likely means one of the listeners is too slow and cannot keep up with " +
"the rate at which tasks are being started by the scheduler.")
}
logTrace(s"Dropping event $event")
Buggy listener
Fine, you already know the slow listener gotcha. But what happens if your listener throws an exception? Does it stop the main job? As the callbacks run a dedicated thread, they won't block the job. Does the failure is fatal, meaning that a failed callback will never restart? Here again the answer is "no". Failures are local to each micro-batch and don't invalidate the listener anyhow.
What about multiple listeners among whom one fails? The query won't block, for sure but what about all the listeners? Will they run? Yes, here too the workflow is local to each listener. It's possible thanks to the ListenerBus safe distribution logic:
private[spark] trait ListenerBus[L <: AnyRef, E] extends Logging {
def postToAll(event: E): Unit = {
// ...
val iter = listenersPlusTimers.iterator
while (iter.hasNext) {
lazy val listenerName = Utils.getFormattedClassName(listener)
try {
doPostEvent(listener, event)
if (Thread.interrupted()) {
// We want to throw the InterruptedException right away so we can associate the interrupt
// with this listener, as opposed to waiting for a queue.take() etc. to detect it.
throw new InterruptedException()
}
} catch {
case ie: InterruptedException =>
logError(s"Interrupted while posting to ${listenerName}. Removing that listener.", ie)
removeListenerOnError(listener)
case NonFatal(e) if !isIgnorableException(e) =>
logError(s"Listener ${listenerName} threw an exception", e)
} finally {
// ...
As you can see, any failure is caught by the NonFatal case and logged, without impacting any neighboring listeners.
Streaming query listeners are then fully separated components from the main job working in isolation. Even though you shouldn't worry about the impact of their failures on your job, you should keep your concerns about the resources they use. After all, they run on your cluster and can cause some trouble in case of too heavy computations.
