
It's the last part of the shuffle writers series. The picture so far composed of SortShuffleWriter and BypassMergeSortShuffleWriter, will be completed today with UnsafeShuffleWriter.
Looking for a better data engineering position and skills?
 You have been working as a data engineer but feel
stuck? You don't have any new challenges and are still writing the same
jobs all over again? You have now different options. You can try to look for a new job, now
or later, or learn from the others! "Become a Better Data Engineer"
initiative is one of these places where you can find online learning resources
where the theory meets the practice.
They will help you prepare maybe for the next job, or at least, improve your current
skillset without looking for something else.
You have been working as a data engineer but feel
stuck? You don't have any new challenges and are still writing the same
jobs all over again? You have now different options. You can try to look for a new job, now
or later, or learn from the others! "Become a Better Data Engineer"
initiative is one of these places where you can find online learning resources
where the theory meets the practice.
They will help you prepare maybe for the next job, or at least, improve your current
skillset without looking for something else.
👉 I'm interested in improving my data engineering skillset
See you there, Bartosz
The post organization is similar to the 2 previous articles. It will start by showing when Apache Spark uses the UnsafeShuffleWriter. In the next part, you will see what happens when the writer generates shuffle files.
UnsafeShuffleWriter - when?
UnsafeShuffleWriter is used with SerializedShuffleHandle. Apache Spark creates it if:
- the number of shuffle partitions is greater than spark.shuffle.sort.bypassMergeThreshold and one of the following conditions is met:
- shuffle serializer supports object relocation - object relocation is an important property of the UnsafeShuffleWriter because it stores serialized binary data instead of Java objects. Thanks to it, it reduces the memory consumption and GC overhead. One of the 3 serializers supporting the relocation every time and it's the one used for Dataset-based API (UnsafeRowSerializer). The KryoSerializer supports relocation only when its auto-reset property is turned on whereas the last serializer, JavaSerializer doesn't support it.
- the processing code doesn't contain a map-side aggregation
- the number of shuffle partitions is lower than 16777216 (MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE)
UnsafeShuffleWriter - 2 buffers
Once Apache Spark knows that it can use the UnsafeShuffleWriter, it follows the writing path which can already be similar to you if you read the blog posts about 2 previous writers. To understand it correctly, we have to know two important things. The first is that the UnsafeShuffleWriter acquires the memory for shuffle data storage from the task memory pool. As a result, it will store the objects in memory pages managed by the MemoryBlock class. However, it's not UnsafeShuffleWriter which will put the objects directly into this structure. It's the responsibility of ShuffleExternalSorter called at the end of records iteration:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
// ...
public void write(scala.collection.Iterator<Product2<K, V>> records) throws IOException {
// ...
while (records.hasNext()) {
insertRecordIntoSorter(records.next());
}
// ...
}
@Nullable private ShuffleExternalSorter sorter;
void insertRecordIntoSorter(Product2<K, V> record) throws IOException {
assert(sorter != null);
final K key = record._1();
final int partitionId = partitioner.getPartition(key);
serBuffer.reset();
serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
serOutputStream.flush();
final int serializedRecordSize = serBuffer.size();
assert (serializedRecordSize > 0);
sorter.insertRecord(
serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
}
In the snippet we have the first buffer storing serialized objects. But if you check what else happens in the insertRecord(Object recordBase, long recordOffset, int length, int partitionId), you will notice that there is another in-memory buffer! This buffer from the ShuffleInMemorySorter class is responsible for storing the shuffle partition id and the location of the serialized record in the MemoryBlock page. The insertRecord updates these 2 places while iterating over all records generated by the mapping function:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
void insertRecordIntoSorter(Product2<K, V> record) throws IOException {
// ...
final Object base = currentPage.getBaseObject();
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
UnsafeAlignedOffset.putSize(base, pageCursor, length);
pageCursor += uaoSize;
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
inMemSorter.insertRecord(recordAddress, partitionId);
This dependency is summarized in the following schema:
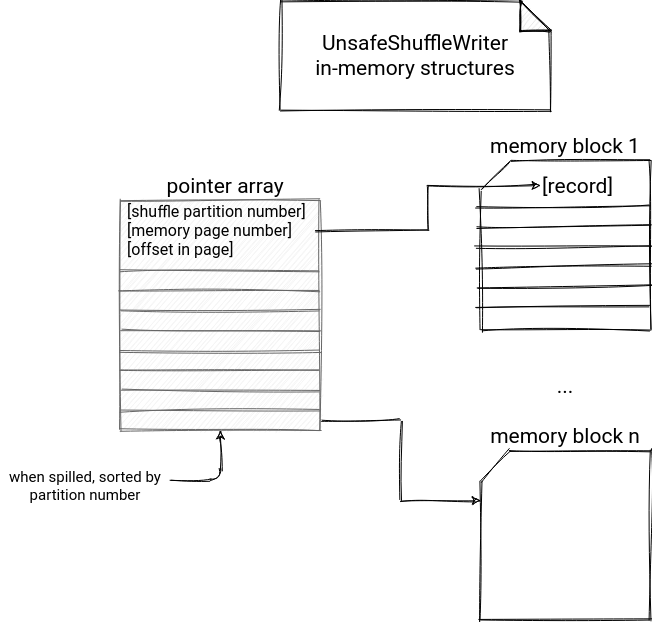
Spilling
I skipped a part of the insertRecordIntoSorter method on purpose. This part is responsible for acquiring memory or growing the in-memory buffers. It also triggers spilling if there is no room left for the new records. The spilling operation happens in different places. First, it can occur when the number of buffered elements is greater than spark.shuffle.spill.numElementsForceSpillThreshold:
final class ShuffleExternalSorter extends MemoryConsumer {
// ...
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
// ...
if (inMemSorter.numRecords() >= numElementsForSpillThreshold) {
logger.info("Spilling data because number of spilledRecords crossed the threshold " +
numElementsForSpillThreshold);
spill();
}
Second, it can also take place when the buffer storing partition and addresses is too big to fit in a single memory page:
final class ShuffleExternalSorter extends MemoryConsumer {
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
// ...
if (inMemSorter.numRecords() >= numElementsForSpillThreshold) {
// ...
}
growPointerArrayIfNecessary();
final int uaoSize = UnsafeAlignedOffset.getUaoSize();
// Need 4 or 8 bytes to store the record length.
final int required = length + uaoSize;
acquireNewPageIfNecessary(required);
// ...
}
private void growPointerArrayIfNecessary() throws IOException {
assert(inMemSorter != null);
if (!inMemSorter.hasSpaceForAnotherRecord()) {
long used = inMemSorter.getMemoryUsage();
LongArray array;
try {
// could trigger spilling
array = allocateArray(used / 8 * 2);
} catch (TooLargePageException e) {
// The pointer array is too big to fix in a single page, spill.
spill();
return;
}
// ...
Even though spilling data on disk will probably affect the performances, it's a very important place in the UnsafeShuffleWriter which happens even when the memory is not full! In the write method, after processing all input records, the writer trigger spilling for all buffered data:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
@Override
public void write(scala.collection.Iterator<Product2<K, V>> records) throws IOException {
try {
while (records.hasNext()) {
insertRecordIntoSorter(records.next());
}
closeAndWriteOutput();
// ...
@VisibleForTesting
void closeAndWriteOutput() throws IOException {
// ...
final SpillInfo[] spills = sorter.closeAndGetSpills();
// ....
}
}
final class ShuffleExternalSorter extends MemoryConsumer {
public SpillInfo[] closeAndGetSpills() throws IOException {
if (inMemSorter != null) {
// Do not count the final file towards the spill count.
writeSortedFile(true);
freeMemory();
inMemSorter.free();
inMemSorter = null;
}
return spills.toArray(new SpillInfo[spills.size()]);
}
Why the spilling is so important? Because of sorting!
Sorting
As you could see from the previous snippet, the method materializing buffered data is writeSortedFile. The first thing it does is to retrieve the ShuffleInMemorySorter.ShuffleSorterIterator instance. The parent class of this iterator is the one which stores the partition id and records offsets in the LongArray buffer. And it's the single buffer which is sorted! Apache Spark sorts its content per partition id, in ascending order, with previously introduced Tim sort or new Radix sort algorithm. The latter is used by default but you can turn it off by disabling the spark.shuffle.sort.useRadixSort property:
final class ShuffleExternalSorter extends MemoryConsumer {
private void writeSortedFile(boolean isLastFile) {
/// ...
// This call performs the actual sort.
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
inMemSorter.getSortedIterator();
// ...
}
final class ShuffleInMemorySorter {
public ShuffleSorterIterator getSortedIterator() {
int offset = 0;
if (useRadixSort) {
offset = RadixSort.sort(
array, pos,
PackedRecordPointer.PARTITION_ID_START_BYTE_INDEX,
PackedRecordPointer.PARTITION_ID_END_BYTE_INDEX, false, false);
} else {
MemoryBlock unused = new MemoryBlock(
array.getBaseObject(),
array.getBaseOffset() + pos * 8L,
(array.size() - pos) * 8L);
LongArray buffer = new LongArray(unused);
Sorter<PackedRecordPointer, LongArray> sorter =
new Sorter<>(new ShuffleSortDataFormat(buffer));
sorter.sort(array, 0, pos, SORT_COMPARATOR);
}
return new ShuffleSorterIterator(pos, array, offset);
}
Radix sort is faster than Tim sort but requires more memory. Anyway, whatever algorithm you use, the iterator will return all record locations ordered by the shuffle partition id. After that, ShuffleExternalSorter will iterate over these sorted pairs and read the partition id of every record. If the partition is different from the previous record, it will trigger a flush action to write the buffered data on disk. If the partition doesn't change, nothing will happen and the sorter will directly pass to the reading part of the data.
To read the records, ShuffleExternalSorter will use the MemoryBlock pages and the address stored in the pair read from the sorted iterator. By "reading", I mean here the copy of the record by taking the spark.shuffle.spill.diskWriteBufferSize bytes every time and putting them to the spilled buffer:
final class ShuffleExternalSorter extends MemoryConsumer {
private void writeSortedFile(boolean isLastFile) {
// ...
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
inMemSorter.getSortedIterator();
// If there are no sorted records, so we don't need to create an empty spill file.
if (!sortedRecords.hasNext()) {
return;
}
while (sortedRecords.hasNext()) {
sortedRecords.loadNext();
final int partition = sortedRecords.packedRecordPointer.getPartitionId();
assert (partition >= currentPartition);
if (partition != currentPartition) {
// Switch to the new partition
if (currentPartition != -1) {
final FileSegment fileSegment = writer.commitAndGet();
spillInfo.partitionLengths[currentPartition] = fileSegment.length();
}
currentPartition = partition;
}
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer();
final Object recordPage = taskMemoryManager.getPage(recordPointer);
final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer);
int dataRemaining = UnsafeAlignedOffset.getSize(recordPage, recordOffsetInPage);
long recordReadPosition = recordOffsetInPage + uaoSize; // skip over record length
while (dataRemaining > 0) {
final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining);
Platform.copyMemory(
recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
writer.write(writeBuffer, 0, toTransfer);
recordReadPosition += toTransfer;
dataRemaining -= toTransfer;
}
After creating the spilling file, the UnsafeShuffleWriter passes to the commit phase where it merges all spilled files inside the mergeSpills(SpillInfo[] spills) method:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
public void write(scala.collection.Iterator<Product2<K, V>> records) throws IOException {
// Keep track of success so we know if we encountered an exception
// We do this rather than a standard try/catch/re-throw to handle
// generic throwables.
boolean success = false;
try {
while (records.hasNext()) {
insertRecordIntoSorter(records.next());
}
closeAndWriteOutput();
// ...
}
@VisibleForTesting
void closeAndWriteOutput() throws IOException {
assert(sorter != null);
updatePeakMemoryUsed();
serBuffer = null;
serOutputStream = null;
final SpillInfo[] spills = sorter.closeAndGetSpills();
sorter = null;
final long[] partitionLengths;
try {
partitionLengths = mergeSpills(spills);
} finally {
for (SpillInfo spill : spills) {
if (spill.file.exists() && !spill.file.delete()) {
logger.error("Error while deleting spill file {}", spill.file.getPath());
}
}
}
mapStatus = MapStatus$.MODULE$.apply(
blockManager.shuffleServerId(), partitionLengths, mapId);
Well, the merge doesn't always happen. It's be skipped when the map task doesn't generate any shuffle data and when it generates only a single spill file. In the latter case, the writer will simply rename the spill file to the shuffle file - at least, in the default local disk shuffle writer implementation.
But what happens if there are 2 or more spill files?
Spills merge - transfer version
When it happens, UnsafeShuffleWriter will use one of 2 methods to merge all of them into a single shuffle file, still ordered by the shuffle partition id. The first of these methods was introduced in the previous blog posts with NIO's transferTo method. It happens when the generated files are not encrypted, the spark.shuffle.unsafe.fastMergeEnabled and spark.file.transferTo are enabled, and the compression codec supports concatenation of serialized streams; i.e. is one of: snappy, LZ4, LZF or ZStandard:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
private long[] mergeSpills(SpillInfo[] spills) throws IOException {
long[] partitionLengths;
if (spills.length == 0) {
// ...
} else if (spills.length == 1) {
// ...
if (maybeSingleFileWriter.isPresent()) {
// ...
} else {
partitionLengths = mergeSpillsUsingStandardWriter(spills);
}
return partitionLengths;
}
private long[] mergeSpillsUsingStandardWriter(SpillInfo[] spills) throws IOException {
long[] partitionLengths;
final boolean compressionEnabled = (boolean) sparkConf.get(package$.MODULE$.SHUFFLE_COMPRESS());
final CompressionCodec compressionCodec = CompressionCodec$.MODULE$.createCodec(sparkConf);
final boolean fastMergeEnabled =
(boolean) sparkConf.get(package$.MODULE$.SHUFFLE_UNSAFE_FAST_MERGE_ENABLE());
final boolean fastMergeIsSupported = !compressionEnabled ||
CompressionCodec$.MODULE$.supportsConcatenationOfSerializedStreams(compressionCodec);
final boolean encryptionEnabled = blockManager.serializerManager().encryptionEnabled();
// ...
if (fastMergeEnabled && fastMergeIsSupported) {
// Compression is disabled or we are using an IO compression codec that supports
// decompression of concatenated compressed streams, so we can perform a fast spill merge
// that doesn't need to interpret the spilled bytes.
if (transferToEnabled && !encryptionEnabled) {
logger.debug("Using transferTo-based fast merge");
mergeSpillsWithTransferTo(spills, mapWriter);
}
The transferTo-based operation first initialized one FileInputStream's FileChannel for every spill file. Later, it starts the iteration over all shuffle partitions and for every partition it:
- creates a ShufflePartitionWriter that will create a WritableByteChannelWrapper where the spilled data will be copied
- iterates over all spill files and for each of them retrieves the shuffle partition length and copies all bytes available from the previous operation to the WritableByteChannelWrapper:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> { for (int i = 0; i < spills.length; i++) { long partitionLengthInSpill = spills[i].partitionLengths[partition]; final FileChannel spillInputChannel = spillInputChannels[i]; final long writeStartTime = System.nanoTime(); Utils.copyFileStreamNIO( spillInputChannel, resolvedChannel.channel(), spillInputChannelPositions[i], partitionLengthInSpill); copyThrewException = false; spillInputChannelPositions[i] += partitionLengthInSpill; writeMetrics.incWriteTime(System.nanoTime() - writeStartTime); }
The logic behind the second spilling technique is based on streams and is very similar.
Spills merge - streams version
Everything starts again by initializing an input stream for the spill files, but this time the used class is NioBufferedFileInputStream:
public class UnsafeShuffleWriter<K, V> extends ShuffleWriter<K, V> {
for (int i = 0; i < spills.length; i++) {
spillInputStreams[i] = new NioBufferedFileInputStream(
spills[i].file,
inputBufferSizeInBytes);
}
Just after that, the writer iterates over all shuffle partitions and creates a ShufflePartitionWriter with corresponding OutputStream:
for (int partition = 0; partition < numPartitions; partition++) {
boolean copyThrewException = true;
ShufflePartitionWriter writer = mapWriter.getPartitionWriter(partition);
OutputStream partitionOutput = writer.openStream();
After that, the writer reads all spills for given partition, extracts the InputStream and copies it to the partitionOutput:
for (int i = 0; i < spills.length; i++) {
final long partitionLengthInSpill = spills[i].partitionLengths[partition];
InputStream partitionInputStream = null;
if (partitionLengthInSpill > 0) {
boolean copySpillThrewException = true;
try {
partitionInputStream = new LimitedInputStream(spillInputStreams[i],
partitionLengthInSpill, false);
partitionInputStream = blockManager.serializerManager().wrapForEncryption(
partitionInputStream);
if (compressionCodec != null) {
partitionInputStream = compressionCodec.compressedInputStream(
partitionInputStream);
}
ByteStreams.copy(partitionInputStream, partitionOutput);
copySpillThrewException = false;
} finally {
Closeables.close(partitionInputStream, copySpillThrewException);
}
}
}
Index file
After merging spill files, UnsafeShuffleWriter calls the commitAllPartitions method where it creates an index file indicating where the data for every partition is located. But how does it know that? Do you remember the ShufflePartitionWriter from the previous parts? It's used to write records at partition basis; i.e. the writer creates a new instance for every partition. Under-the-hood this instance keeps an output stream where it writes partition records and at the end it closes the stream. When it happens, it also updates a variable called partitionLengths storing the number of bytes written for the given partition:
@Override
public void close() throws IOException {
partitionLengths[partitionId] = getCount();
bytesWrittenToMergedFile += partitionLengths[partitionId];
}
The same variable - since it's not tied to the partition writer but to a more global map output writer - is later used to build the offsets in the index file.
It was the last post from the Spark shuffle writers series. You saw that despite their apparent differences like the underlying in-memory structures used to buffer the records, they share some common points like data spilling.
