
You know me already, I'm a big fan of Apache Spark but also of all kinds of patterns. And one of the patterns that nowadays gains in popularity is lakehouse. Most of the time (always?), this pattern is implemented on top of an ACID-compatible file system like Apache Hudi, Apache Iceberg or Delta Lake. But can we do it differently and use another storage, like BigQuery?
Looking for a better data engineering position and skills?
 You have been working as a data engineer but feel
stuck? You don't have any new challenges and are still writing the same
jobs all over again? You have now different options. You can try to look for a new job, now
or later, or learn from the others! "Become a Better Data Engineer"
initiative is one of these places where you can find online learning resources
where the theory meets the practice.
They will help you prepare maybe for the next job, or at least, improve your current
skillset without looking for something else.
You have been working as a data engineer but feel
stuck? You don't have any new challenges and are still writing the same
jobs all over again? You have now different options. You can try to look for a new job, now
or later, or learn from the others! "Become a Better Data Engineer"
initiative is one of these places where you can find online learning resources
where the theory meets the practice.
They will help you prepare maybe for the next job, or at least, improve your current
skillset without looking for something else.
👉 I'm interested in improving my data engineering skillset
See you there, Bartosz
The post starts with a short presentation of Lakehouse architecture. If you want to know more about it, I put some links in the "Read more" section. Next, I will try to answer the question from the title, namely whether is it possible to use a different backend than the ACID-compatible file systems in that pattern?
Lakehouse 101
Lakehouse's approach addresses 10 data lake issues identified by Databricks and very clearly summarized in the Data+AI Summit Europe 2020:

As you can see, the data lake problems come from:
- The lack of transactional support (reliability problems).
- Any indexing mechanism (performance).
- Table-level access control with fine grained column or row level (security).
- The validation mechanism for the schema and the data (quality).
To fix all of these, Databricks proposes Delta Lake - an ACID-compatible, highly optimized file format. Although I didn't find the examples for Apache Hudi or Apache Iceberg, I suppose that they could also be used to solve the presented issues (or at least, a part of them).
As the outcome of this pattern, you can get a relatively simple data architecture with direct access to your data from the analytics and data science layers, as presented below:
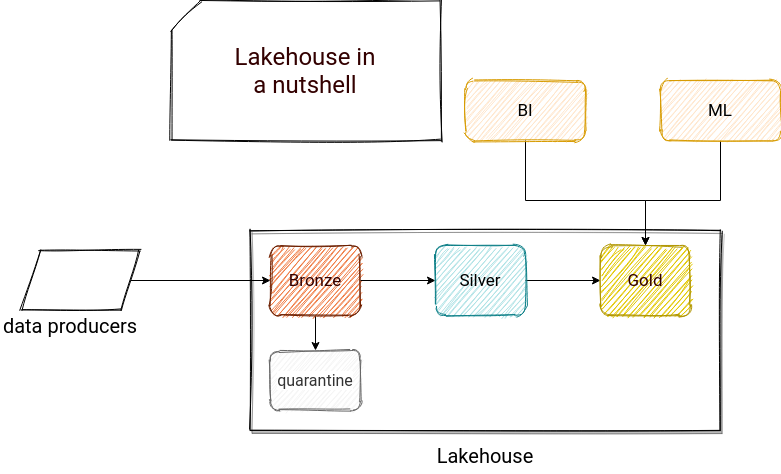
A few things to notice here. First, lakehouse organizes datasets in 3 categories called Bronze, Silver, and Gold. The idea is to augment the data quality with every new maturity epoch so that the only one exposed to the users is the Gold dataset. In the schema, you can also see a quarantine component layer responsible for storing the data not matching the schema or validation rules. The last interesting thing is that I have a feeling that we can consider the Gold dataset.
That's the quick summary. I will develop more detailed points in the next sections of this article.
BigQuery - the lakehouse's Delta Lake?
BigQuery, aside from Redshift Spectrum (AWS) or Synapse Analytics (Azure), is one of the managed services quoted in the original paper presenting the Lakehouse architecture. It's considered there as a solution having "some of the lakehouse features listed above, but they are examples that focus primarily on BI and other SQL applications". When I'm writing this blog post, I'm also preparing for GCP Data Engineer certification. To improve my preparation process, I will see whether we can consider BigQuery as the backbone of a Lakehouse architecture.
BigQuery architecture fulfills 3 points from the Databricks article's checklist, namely the transaction support, schema enforcement and governance, and storage decoupled from compute. To prove you that, let's start with the architecture of BigQuery:
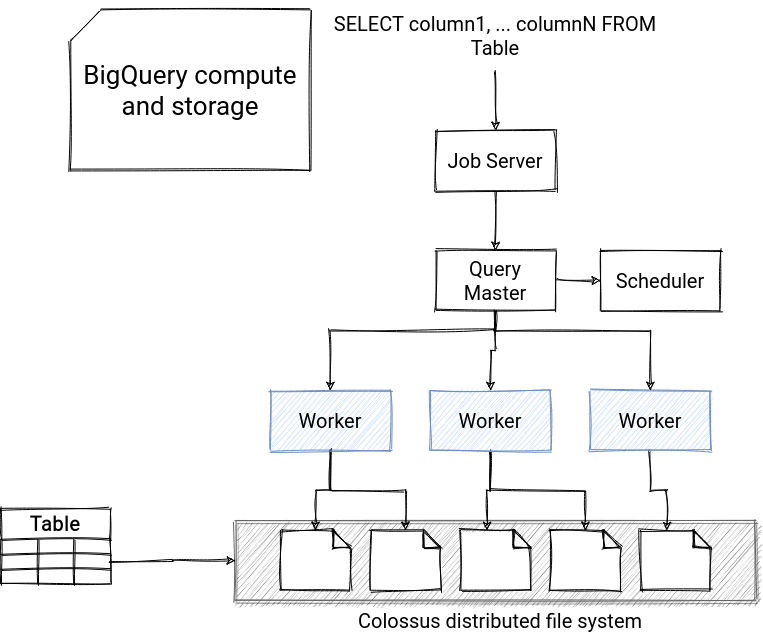
From the picture, you can see that every table is represented as the files stored in the fault-tolerant Colossus file system. Looks similar to storing the data in Delta Lake format and exposing it through the tables, right? It also proves the points about decoupled storage from compute and schema enforcement. Since the table represents here a structured dataset, it automatically involves a normalized and consistent schema. It also provides the auditing mechanism through the Cloud Audit Logs service. Regarding the ACID transactions, BigQuery supports them, and it's highlighted in the documentation.
That's OK, but what about the other points from the checklist? BI is widely supported. BigQuery has built-in support for GCP data visualization products like Data Studio, but it also developed its JDBC and ODBC connectors to connect with other systems and solutions. And if you don't want to use them, you can always pass via the RESTful API, for example, from a custom JavaScript backend.
This connectivity point checks the next square, the support for various data use cases. As you saw, BigQuery can be used - and is used - for data visualization, but it can also be employed in Machine Learning scenarios. Apart from the APIs and *DBC connectors, BigQuery also provides a Python SDK that you can use in the ML scenarios.
The last matched point from my perspective concerns the end-to-end streaming. BigQuery supports streaming ingestion from Dataflow but can't be used as a streaming data source like Delta Lake with Apache Spark Structured Streaming. Therefore, it fulfills this requirement partially.
Is it a perfect fit?
From the previous section, you can think that yes, but there are still 2 points to check. The first of them is the support for diverse data types (structured, unstructured). Storing full text or binary files in BigQuery is not a good idea (is it even possible technically for the binary ones?). The service pricing is based on the amount of queried data, and that's why the unstructured data is often stored in GCS and referenced from BigQuery. Even though I wouldn't say that it's a discriminating point for considering BigQuery as a Lakehouse, it means that you will need another storage for the unstructured files.
And finally the last point, the openness, defined as:
Openness: The storage formats they use are open and standardized, such as Parquet, and they provide an API so a variety of tools and engines, including machine learning and Python/R libraries, can efficiently access the data directly.
BigQuery storage is a closed-source technology, even though you can find some high-level details in various sources. But on the other hand, this vendor-locking aspect is a very common trade-off for choosing managed cloud services to reduce the time-to-market and operational part. If you can accept that, it shouldn't be then a blocking point.
To summarize, in the following picture you will find the 8 checkpoints from the original Lakehouse article matched to GCP technologies:
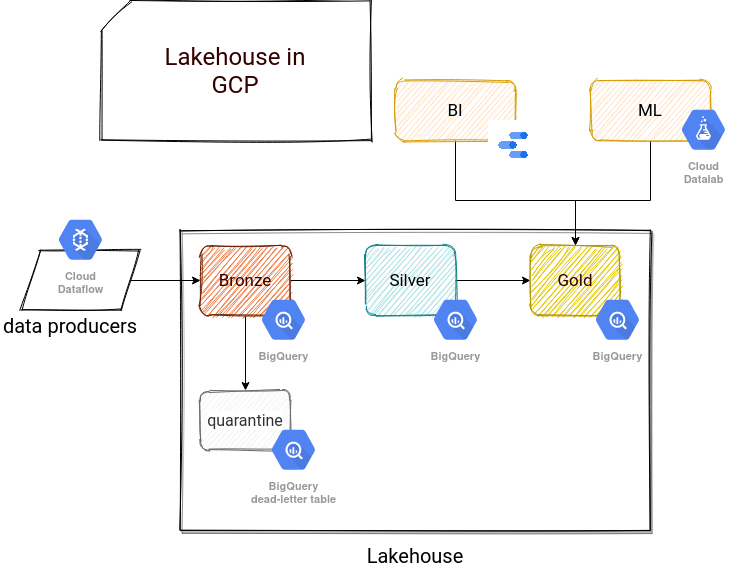
As you can see, a lot of points are checked, some of them are not or are only partially valid. I would say that despite these small differences, BigQuery fits to lakehouse pattern. And you?
