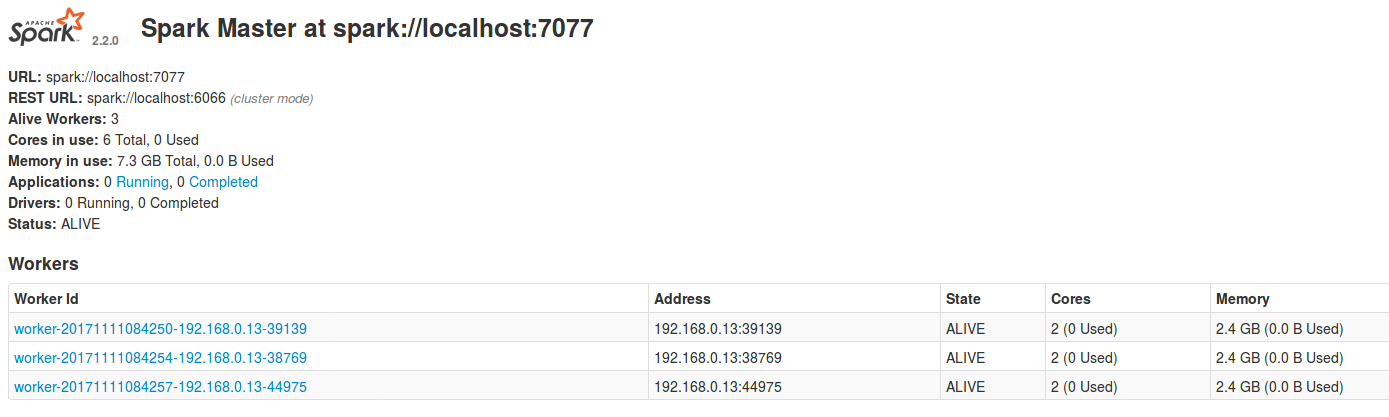
Starting 2 or more workers in standalone mode is based on exporting corresponding Spark's environment variable SPARK_WORKER_INSTANCES. Eventually it can be followed by the definition of SPARK_WORKER_MEMORY and SPARK_WORKER_CORES. The whole operation is presented in the following snippet:
bartosz:~/programming/spark-2.2.0-bin-hadoop2.7/sbin$ ./start-master.sh --host localhost starting org.apache.spark.deploy.master.Master, logging to /home/bartosz/programming/spark-2.2.0-bin-hadoop2.7/logs/spark-bartosz-org.apache.spark.deploy.master.Master-1-bartosz-localhost.out bartosz:~/programming/spark-2.2.0-bin-hadoop2.7/sbin$ export SPARK_WORKER_INSTANCES=3 bartosz:~/programming/spark-2.2.0-bin-hadoop2.7/sbin$ export SPARK_WORKER_MEMORY=2500M bartosz:~/programming/spark-2.2.0-bin-hadoop2.7/sbin$ export SPARK_WORKER_CORES=2 bartosz:~/programming/spark-2.2.0-bin-hadoop2.7/sbin$ ./start-slave.sh spark://localhost:7077 starting org.apache.spark.deploy.worker.Worker, logging to /home/bartosz/programming/spark-2.2.0-bin-hadoop2.7/logs/spark-bartosz-org.apache.spark.deploy.worker.Worker-1-bartosz-localhost.out starting org.apache.spark.deploy.worker.Worker, logging to /home/bartosz/programming/spark-2.2.0-bin-hadoop2.7/logs/spark-bartosz-org.apache.spark.deploy.worker.Worker-2-bartosz-localhost.out starting org.apache.spark.deploy.worker.Worker, logging to /home/bartosz/programming/spark-2.2.0-bin-hadoop2.7/logs/spark-bartosz-org.apache.spark.deploy.worker.Worker-3-bartosz-localhost.out
If the operation works as expected, you'd see the following screen in Spark UI: