
After discovering two methods used to join DataFrames, broadcast and hashing, it's time to talk about the third possibility - sort-merge join.
The first section of this post explains the main idea of sort-merge join (also known as merge join). The next part presents its implementation in Spark SQL. Finally, the last part shows through learning tests, how to make Spark use the sort-merge join.
Sort-merge join explained
As the name indicates, sort-merge join is composed of 2 steps. The first step is the ordering operation made on 2 joined datasets. The second operation is the merge of sorted data into a single place by simply iterating over the elements and assembling the rows having the same value for the join key.
Below schema shows the steps made by the algorithm more clearly:
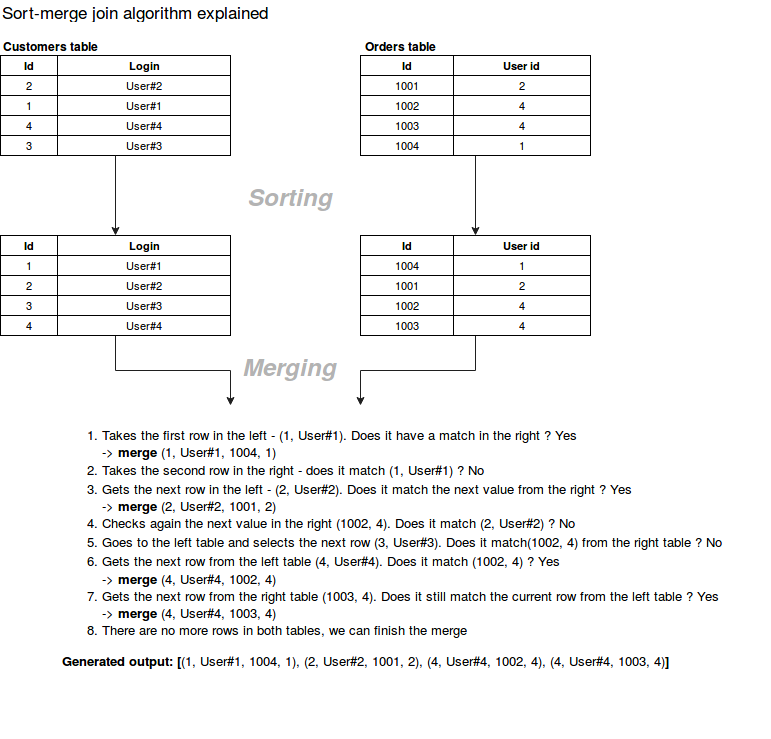
Sort-merge join in Spark SQL
In Spark SQL the sort-merge join is implemented in similar manner. But the difference is that the data is distributed and the algorithm is applied on partition level. Thus it's important to ensure that all rows having the same value for the join key are stored in the same partition. This prerequirement obviously leads to data shuffle between executors.
The sort-merge join can be activated through spark.sql.join.preferSortMergeJoin property that, when enabled, will prefer this type of join over shuffle one.
Among the most important classes involved in sort-merge join we should mention org.apache.spark.sql.execution.joins.SortMergeJoinExec. This is the central point dispatching code generation according to defined join type. It exposes the information about dataset location on different nodes (= occupied partitions) but among others, it generates the code described above that is used to execute sort-merge join. And we can easily check if the generated code uses the sort-merge join principle correctly. Let's suppose that we want to join 2 datasets with following schema: (id=Integer, customer_id=Integer, amount=Double) and (cid=Integer, login=String) and that the inner join key will be "customer_id == cid". Spark will generate the sorting code presented in the following snippet (explaination as class comments, some lines omitted for brevity):
/* 005 */ final class GeneratedIterator extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 010 */ private org.apache.spark.sql.execution.UnsafeExternalRowSorter sort_sorter;
/* 017 */
/* 022 */ public void init(int index, scala.collection.Iterator[] inputs) {
// The partitionIndex shows that the sort is called per partition
/* 023 */ partitionIndex = index;
/* 025 */ sort_needToSort = true;
/* 026 */ this.sort_plan = (org.apache.spark.sql.execution.SortExec) references[0];
/* 027 */ sort_sorter = sort_plan.createSorter();
/* 029 */
/* 030 */ inputadapter_input = inputs[0];
/* 035 */ }
/* 037 */ private void sort_addToSorter() throws java.io.IOException {
/* 038 */ while (inputadapter_input.hasNext()) {
/* 039 */ InternalRow inputadapter_row = (InternalRow) inputadapter_input.next();
// Iterates over all rows to sort and adds them to
// created instance of UnsafeExternalRowSorter that,
// internally, passes them to the UnsafeExternalSorter
// The rows aren't sorted in this moment
/* 040 */ sort_sorter.insertRow((UnsafeRow)inputadapter_row);
/* 041 */ if (shouldStop()) return;
/* 042 */ }
/* 043 */
/* 044 */ }
/* 045 */
/* 046 */ protected void processNext() throws java.io.IOException {
/* 047 */ if (sort_needToSort) {
/* 048 */ // ...
/* 049 */ sort_addToSorter();
// Here the effective sorting occurs. The generated code
// calls UnsafeExternalRowSorter that internally invokes
// UnsafeExternalSorter#getSortedIterator() that uses
// UnsafeInMemorySorter#getSortedIterator() to retrieve ordered rows
/* 050 */ sort_sortedIter = sort_sorter.sort();
/* 051 */ // ...
/* 055 */ sort_needToSort = false;
/* 056 */ }
// Adds all sorted items to the LinkedList[InternalRow] that is a
// protected field of BufferedRowIterator abstract class
/* 058 */ while (sort_sortedIter.hasNext()) {
/* 059 */ UnsafeRow sort_outputRow = (UnsafeRow)sort_sortedIter.next();
/* 060 */
/* 061 */ append(sort_outputRow);
/* 062 */
/* 063 */ if (shouldStop()) return;
/* 064 */ }
/* 065 */ }
/* 066 */ }
And merge part looks like (explanation inside the class):
/* 005 */ final class GeneratedIterator extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 006 */ private Object[] references;
// Note that "smj" is the prefix for SortMergeJoin
// Complete mapping for used variables can be found in
// org.apache.spark.sql.execution.CodegenSupport#variablePrefix
/* 010 */ private InternalRow smj_leftRow;
/* 011 */ private InternalRow smj_rightRow;
/* 013 */ private java.util.ArrayList smj_matches;
/* 014 */ private int smj_value3;
/* 026 */
/* 027 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 028 */ partitionIndex = index;
/* 030 */ smj_leftInput = inputs[0];
/* 031 */ smj_rightInput = inputs[1];
/* 032 */
/* 033 */ smj_rightRow = null;
/* 034 */
/* 035 */ smj_matches = new java.util.ArrayList();
/* 042 */ }
/* 044 */ private boolean findNextInnerJoinRows(
/* 045 */ scala.collection.Iterator leftIter,
/* 046 */ scala.collection.Iterator rightIter) {
// smj_leftRow is a class variable so
/* 047 */ smj_leftRow = null;
/* 048 */ int comp = 0;
/* 049 */ while (smj_leftRow == null) {
/* 050 */ if (!leftIter.hasNext()) return false;
/* 051 */ smj_leftRow = (InternalRow) leftIter.next();
/* 052 */
/* 053 */ int smj_value = smj_leftRow.getInt(1);
// In the case when the next row from the left side is the same
// as previous processed row, return matches directly - do that
// until meeting new key in the left
/* 058 */ if (!smj_matches.isEmpty()) {
/* 061 */ comp = (smj_value > smj_value3 ? 1 : smj_value < smj_value3 ? -1 : 0);
/* 063 */
/* 064 */ if (comp == 0) {
/* 065 */ return true;
/* 066 */ }
/* 067 */ smj_matches.clear();
/* 068 */ }
/* 069 */
/* 070 */ do {
// Gets the row from the right side - especially
// the value of join key (smj_value2)
/* 071 */ if (smj_rightRow == null) {
/* 072 */ if (!rightIter.hasNext()) {
/* 073 */ smj_value3 = smj_value;
/* 074 */ return !smj_matches.isEmpty();
/* 075 */ }
/* 076 */ smj_rightRow = (InternalRow) rightIter.next();
/* 077 */
/* 078 */ int smj_value1 = smj_rightRow.getInt(0);
/* 083 */ smj_value2 = smj_value1;
/* 084 */ }
// Resolves the state of join:
// 0 -> both keys are the same, so the rows can be joined
// 1 -> left key is greater, so try the next key in the right
// -1 -> right key is greater, so stop processing on the
// current left key and return the accumulated results
// for later processing (merging 2 rows) - if there are any
// matches. Otherwise, process next row from the left
/* 086 */ comp = 0;
/* 087 */ if (comp == 0) {
/* 088 */ comp = (smj_value > smj_value2 ? 1 : smj_value < smj_value2 ? -1 : 0);
/* 089 */ }
// Here the actions for resolved state are executed
/* 091 */ if (comp > 0) {
/* 092 */ smj_rightRow = null;
/* 093 */ } else if (comp < 0) {
/* 094 */ if (!smj_matches.isEmpty()) {
/* 095 */ smj_value3 = smj_value;
/* 096 */ return true;
/* 097 */ }
/* 098 */ smj_leftRow = null;
/* 099 */ } else {
/* 100 */ smj_matches.add(smj_rightRow.copy());
/* 101 */ smj_rightRow = null;;
/* 102 */ }
/* 103 */ } while (smj_leftRow != null);
/* 104 */ }
/* 105 */ return false; // unreachable
/* 106 */ }
/* 108 */ protected void processNext() throws java.io.IOException {
/* 109 */ while (findNextInnerJoinRows(smj_leftInput, smj_rightInput)) {
/* 110 */ int smj_size = smj_matches.size();
/* 114 */ for (int smj_i = 0; smj_i < smj_size; smj_i ++) {
/* 115 */ InternalRow smj_rightRow1 = (InternalRow) smj_matches.get(smj_i);
// Missing lines represent the merge process of 2 rows (left and right)
// They construct an object called smj_result that is later copied
// and added to LinkedList[InternalRow] of BufferedRowIterator
/* 140 */ append(smj_result.copy());
/* 141 */
/* 142 */ }
/* 143 */ if (shouldStop()) return;
/* 144 */ }
/* 145 */ }
/* 146 */ }
Sort-merge join example
Below tests show how to use sort-merge join (or rather how to ensure that it's used):
val sparkSession = SparkSession.builder().appName("Sort-merge join test")
.master("local[*]")
.config("spark.sql.join.preferSortMergeJoin", "true")
.config("spark.sql.autoBroadcastJoinThreshold", "1")
.config("spark.sql.defaultSizeInBytes", "100000")
.getOrCreate()
after {
sparkSession.stop()
}
"sort-merge join" should "be used when neither broadcast nor hash join are possible" in {
import sparkSession.implicits._
val customersDataFrame = (1 to 3).map(nr => (nr, s"Customer_${nr}")).toDF("cid", "login")
val ordersDataFrame = Seq(
(1, 1, 19.5d), (2, 1, 200d), (3, 2, 500d), (4, 100, 1000d),
(5, 1, 19.5d), (6, 1, 200d), (7, 2, 500d), (8, 100, 1000d)
).toDF("id", "customers_id", "amount")
val ordersWithCustomers = ordersDataFrame.join(customersDataFrame, $"customers_id" === $"cid")
val mergedOrdersWithCustomers = ordersWithCustomers.collect().map(toAssertRow(_))
val explainedPlan = ordersWithCustomers.queryExecution.toString()
explainedPlan.contains("SortMergeJoin [customers_id") shouldBe true
mergedOrdersWithCustomers.size shouldEqual(6)
mergedOrdersWithCustomers should contain allOf(
"1-1-19.5-1-Customer_1", "2-1-200.0-1-Customer_1", "3-2-500.0-2-Customer_2",
"5-1-19.5-1-Customer_1", "6-1-200.0-1-Customer_1", "7-2-500.0-2-Customer_2"
)
}
"for not sortable keys the sort merge join" should "not be used" in {
import sparkSession.implicits._
// Here we explicitly define the schema. Thanks to that we can show
// the case when sort-merge join won't be used, i.e. when the key is not sortable
// (there are other cases - when broadcast or shuffle joins can be chosen over sort-merge
// but it's not shown here).
// Globally, a "sortable" data type is:
// - NullType, one of AtomicType
// - StructType having all fields sortable
// - ArrayType typed to sortable field
// - User Defined DataType backed by a sortable field
// The method checking sortability is org.apache.spark.sql.catalyst.expressions.RowOrdering.isOrderable
// As you see, CalendarIntervalType is not included in any of above points,
// so even if the data structure is the same (id + login for customers, id + customer id + amount for orders)
// with exactly the same number of rows, the sort-merge join won't be applied here.
val schema = StructType(
Seq(StructField("cid", CalendarIntervalType), StructField("login", StringType))
)
val schemaOrder = StructType(
Seq(StructField("id", IntegerType), StructField("customers_id", CalendarIntervalType), StructField("amount", DoubleType))
)
val customersRdd = sparkSession.sparkContext.parallelize((1 to 3).map(nr => (new CalendarInterval(nr, 1000), s"Customer_${nr}")))
.map(attributes => Row(attributes._1, attributes._2))
val customersDataFrame = sparkSession.createDataFrame(customersRdd, schema)
val ordersRdd = sparkSession.sparkContext.parallelize(Seq(
(1, new CalendarInterval(1, 1000), 19.5d), (2, new CalendarInterval(1, 1000), 200d),
(3, new CalendarInterval(2, 1000), 500d), (4, new CalendarInterval(11, 1000), 1000d),
(5, new CalendarInterval(1, 1000), 19.5d), (6, new CalendarInterval(1, 1000), 200d),
(7, new CalendarInterval(2, 1000), 500d), (8, new CalendarInterval(11, 1000), 1000d)
).map(attributes => Row(attributes._1, attributes._2, attributes._3)))
val ordersDataFrame = sparkSession.createDataFrame(ordersRdd, schemaOrder)
val ordersWithCustomers = ordersDataFrame.join(customersDataFrame, $"customers_id" === $"cid")
val mergedOrdersWithCustomers = ordersWithCustomers.collect().map(toAssertRowInterval(_))
val explainedPlan = ordersWithCustomers.queryExecution.toString()
explainedPlan.contains("ShuffledHashJoin [customers_id") shouldBe true
explainedPlan.contains("SortMergeJoin [customers_id") shouldBe false
mergedOrdersWithCustomers.size shouldEqual(6)
mergedOrdersWithCustomers should contain allOf(
"1-1:1-19.5-1:1-Customer_1", "2-1:1-200.0-1:1-Customer_1", "5-1:1-19.5-1:1-Customer_1",
"6-1:1-200.0-1:1-Customer_1", "3-2:1-500.0-2:1-Customer_2", "7-2:1-500.0-2:1-Customer_2"
)
}
private def toAssertRowInterval(row: Row): String = {
val orderId = row.getInt(0)
val orderCustomerId = row.getAs[CalendarInterval](1)
val orderAmount = row.getDouble(2)
val customerId = row.getAs[CalendarInterval](3)
val customerLogin = row.getString(4)
s"${orderId}-${orderCustomerId.months}:${orderCustomerId.milliseconds()}-"+
s"${orderAmount}-${customerId.months}:${customerId.milliseconds()}-${customerLogin}"
}
private def toAssertRow(row: Row): String = {
val orderId = row.getInt(0)
val orderCustomerId = row.getInt(1)
val orderAmount = row.getDouble(2)
val customerId = row.getInt(3)
val customerLogin = row.getString(4)
s"${orderId}-${orderCustomerId}-${orderAmount}-${customerId}-${customerLogin}"
}
Sort-merge join was the 3rd join algorithm implemented in Spark and described here. Since it was more complicated than broadcast and hash joins, the first part of this post explained the general idea hidden behind it. We could see that it's composed of 2 stages: sorting of both sides (left + right) on join keys and merging, taking sorted keys in order to find the matches. The second part shown that through the code generated by SortMergeJoinExec. It's especially visible inside findNextInnerJoinRows method when the application iterates over left keys and tries to find the matches in the right side. The last part proved that sort-merge join really works in Spark SQL but in some cases, as not sortable keys, it's not applied.
