
Last time we've discovered different encoding methods available in Apache Parquet. But the encoding is not the single technique helping to reduce the size of files. The other one, very similar, is the compression.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post gives an insight on the compression provided by Apache Parquet. However the first part recalls the basics and focuses on compression as a process independent of any framework. Only the second section lists and explains the compression codecs available in Parquet. The last section shows some compression tests.
Compression definition
Data compression is a technique that the main purpose is the reduction of the logical size of the file. So reduced file should take less place on disk and be transferred faster over the network. Very often the compression works similarly to encoding. It identifies repetitive patterns and replaces them with more compact representations.
The difference between encoding and compression is subtle. The encoding changes data representation. For instance it can represent the word "abc" as "11" and often it can be based on the same principles as the compression. An example of that is Run-Length Encoding that replaces repeated symbols (e.g. "aaa") with shorter form ("3a"). In the other side, the compression deals with the whole information and takes advantage of data redundancy to reduce the total size. For instance, it can remove the parts of information that are useless (e.g. repeated patterns or pieces of information meaningless for the receiver).
Compression codecs in Parquet
The compression in Parquet is done per column. Except uncompressed representation, Apache Parquet comes with 3 compression codecs:
- gzip - pretty popular lossless compression method based on DEFLATE algorithm being a combination of Huffman coding and LZ77.
The Huffman coding is a variable-length technique that assigns smaller codes for the most frequently used characters. For instance, if we'd like to encode the word "aaaaabbbc" with 2 bits we'd use 9*2 = 18 bits. In the other side, encoding this sequence of characters with Huffman coding could reduce the number of bits to 5+3*2+2 = 13 bits where the most frequent character "a" is encoded as 0 and two others in usual 2 bits. It was a simple explanation. More exactly Huffman coding works by combining trees with nodes representing characters from encoded value. Each node represents one character and is labeled with the character's weight (= the number of occurrences). The algorithm starts with 1-node trees that are combined step by step until there is only 1 tree. The merge step consists on choosing 2 trees with the least weights and combining them together. At the end the encoding is resolved by defining encoding rule. For instance the encoding rule can tell that all values on the left are encoded with 1 and the right ones with 0. This algorithm is presented in the below image:
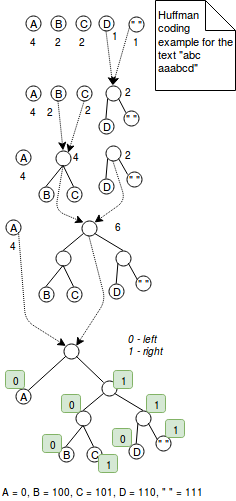
In the other side, LZ77 represents repeated information in more concise triplets of (distance, length). For instance, if we encode the text "ABAC" with LZ77, it'll be represented as "AB(2,1)C". The image below explains better the steps of this method:
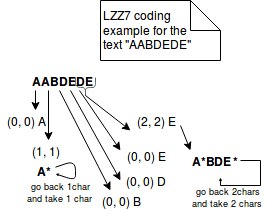
- Snappy - Snappy is open-sourced by Google, byte-oriented (whole bytes are emitted or consumed from a stream) compression method. The compressed format begins with a field indicating the length of uncompressed data. Later, the compressed data is represented either as literals or as copies. Both of these representations are included in a structure called tag byte. The 2 low bytes of this structure indicate the used representation (00 for literals, 01, 10, 11 for copies).
Literal is used to represent the data that can't be compressed. It has a concept of length that can be stored in 2 different places. For the literals up to 60 bytes, the length is stored directly in the tag byte. For the bigger literals, the length is stored directly after the tag byte. In this case the tag byte contains only the information about how many place is occupied by the length.
The second type of representation is called copy. It uses similar concept to the LZ77 encoding since it represents repeated data in tuples of (offset, length). Depending on the length from the tuple, we can distinguish 3 different types of copies:- The copy with 1-byte offset encodes the lengths between 4 and 11 bytes. In the tag byte it's prefixed with 01 in the tag byte.
- For the copy with 2-byte offset the lengths between 1 and 64 bytes are prefixed with 10 in the tag byte. The offset information is stored in 2 bytes following the tag byte as a 16 bits little-endian int.
- The copy with 4-byte offset is represented as 11 in the tag byte. It has similar characteristics than the previous copy. The only difference is the offset storage that is 32-bit integer.
However, Snappy is not purely LZ77 encoding. It's more like LZ-style. LZ77 consists on 2 parts: matching algorithm that recognizes the repetitions and encoding. Snappy skips the last part because it uses fixed and hand-tuned packing format of literals and copies. - LZO - dictionary-based and lossless compression method. It favors compression speed over the compression ratio. The LZO belongs to the family of LZ encodings because it's the variation of LZ77. The difference is that it's optimized to take advantage of the fact that the nowadays computers are optimized for performing integer operations. It brings so quick hash lookup tables and better optimized output tokens. The data that can't be compressed is copied in uncompressed form to the output stream on a 32-bit long word basis.
Unlike 2 previous compression methods, the LZO compression needs some additional work. A native LZO library must be installed separately and some solutions was given on StackOverflow: Hadoop-LZO strange native-lzo library not available error or Class com.hadoop.compression.lzo.LzoCodec not found for Spark on CDH 5?.
Parquet compression examples
In below tests, because of LZO installation complexity, only gzip and Snappy codecs are presented:
private static final CodecFactory CODEC_FACTORY = new CodecFactory(new Configuration(), 1024);
private static final CodecFactory.BytesCompressor GZIP_COMPRESSOR =
CODEC_FACTORY.getCompressor(CompressionCodecName.GZIP);
private static final CodecFactory.BytesCompressor SNAPPY_COMPRESSOR =
CODEC_FACTORY.getCompressor(CompressionCodecName.SNAPPY);
private static final BytesInput BIG_INPUT_INTS;
static {
List<BytesInput> first4000Numbers =
IntStream.range(1, 4000).boxed().map(number -> BytesInput.fromInt(number)).collect(Collectors.toList());
BIG_INPUT_INTS = BytesInput.concat(first4000Numbers);
}
private static final BytesInput SMALL_INPUT_STRING = BytesInput.concat(
BytesInput.from(getUtf8("test")), BytesInput.from(getUtf8("test1")), BytesInput.from(getUtf8("test2")),
BytesInput.from(getUtf8("test3")), BytesInput.from(getUtf8("test4"))
);
private static final BytesInput INPUT_DATA_STRING;
private static final BytesInput INPUT_DATA_STRING_DISTINCT_WORDS;
static {
URL url = Resources.getResource("lorem_ipsum.txt");
try {
String text = Resources.toString(url, Charset.forName("UTF-8"));
INPUT_DATA_STRING = BytesInput.from(getUtf8(text));
String textWithDistinctWords = Stream.of(text.split(" ")).distinct().collect(Collectors.joining(", "));
INPUT_DATA_STRING_DISTINCT_WORDS = BytesInput.from(getUtf8(textWithDistinctWords));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Test
public void should_compress_lorem_ipsum_more_efficiently_with_gzip_than_without_compression() throws IOException {
BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING);
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size());
assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());
}
@Test
public void should_compress_text_without_repetitions_more_efficiently_with_gzip_than_without_compression() throws IOException {
BytesInput compressedLorem = GZIP_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS);
System.out.println("Compressed size = "+compressedLorem.size() +
" vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size());
assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());
}
@Test
public void should_compress_small_text_less_efficiently_with_gzip_than_without_compression() throws IOException {
BytesInput compressedLorem = GZIP_COMPRESSOR.compress(SMALL_INPUT_STRING);
// Compressed size is greater because GZIP adds some additional compression metadata as, header
// It can be seen in java.util.zip.GZIPOutputStream.writeHeader()
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size());
assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());
}
@Test
public void should_compress_ints_more_efficiently_with_gzip_than_without_compression() throws IOException {
BytesInput compressedLorem = GZIP_COMPRESSOR.compress(BIG_INPUT_INTS);
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size());
assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());
}
@Test
public void should_compress_lorem_ipsum_more_efficiently_with_snappy_than_without_compression() throws IOException {
BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING);
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+INPUT_DATA_STRING.size());
assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING.size());
}
@Test
public void should_compress_text_without_repetitions_more_efficiently_with_snappy_than_without_compression() throws IOException {
BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(INPUT_DATA_STRING_DISTINCT_WORDS);
System.out.println("Compressed size = "+compressedLorem.size() +
" vs plain size = "+INPUT_DATA_STRING_DISTINCT_WORDS.size());
assertThat(compressedLorem.size()).isLessThan(INPUT_DATA_STRING_DISTINCT_WORDS.size());
}
@Test
public void should_compress_small_text_less_efficiently_with_snappy_than_without_compression() throws IOException {
BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(SMALL_INPUT_STRING);
// For snappy the difference is much less smaller than in the case of Gzip (1 byte)
// The difference comes from the fact that Snappy stores the length of compressed output after
// the compressed values
// You can see that in the Snappy implementation C++ header file:
// https://github.com/google/snappy/blob/32d6d7d8a2ef328a2ee1dd40f072e21f4983ebda/snappy.h#L111
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+SMALL_INPUT_STRING.size());
assertThat(compressedLorem.size()).isGreaterThan(SMALL_INPUT_STRING.size());
}
@Test
public void should_compress_ints_more_efficiently_with_snappy_than_without_compression() throws IOException {
BytesInput compressedLorem = SNAPPY_COMPRESSOR.compress(BIG_INPUT_INTS);
// Snappy is only slightly different than the plain encoding (1 byte less)
System.out.println("Compressed size = "+compressedLorem.size() + " vs plain size = "+ BIG_INPUT_INTS.size());
assertThat(compressedLorem.size()).isLessThan(BIG_INPUT_INTS.size());
}
@Test
public void should_fail_compress_with_lzo_when_the_native_library_is_not_loaded() throws IOException {
assertThatExceptionOfType(RuntimeException.class).isThrownBy(() -> CODEC_FACTORY.getCompressor(CompressionCodecName.LZO))
.withMessageContaining("native-lzo library not available");
}
private static final byte[] getUtf8(String text) {
try {
return text.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
The compression is one of other Parquet's weapons for the battle against inefficient storage. It's complementary to already explained encoding methods and can be applied on column level as well. That brings the possibility to use different compression methods, according to the contained data. Apache Parquet provides 3 compression codecs detailed in the 2nd section: gzip, Snappy and LZO. Two first are included natively while the last requires some additional setup. As shown in the final section, the compression is not always positive. Sometimes the compressed data occupies more place than the uncompressed. We'd explain that by an extra overhead brought by encoding information.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Compression in Parquet here:
- Encoding vs compression vs encryption Snappy format description LZ77 algorithm Huffman Coding: A CS2 Assignment Compression Speed Enhancements to LZO for Multi-Core Systems
Related blog posts:
Compression methods in #ApacheParquet explained https://t.co/vCaGW5FNsf
— bardev (@waitingforcode) November 26, 2017