
After recent introduction to Apache ZooKeeper in Apache Pulsar, it's time to see another component of this messaging system, namely Apache BookKeeper. In this first post of the series, I will introduce the key concepts of BookKeeper and also try to see how they're implemented.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Definitions in image
If you take a look at the BookKeeper's documentation, you will see its main building blocks, namely entry, ledger and bookie. If you are familiar with Apache Kafka's logs and segments, all these concepts should look familiar to you. First of them, an entry, is the representation of a particular record written by the client to an append-only structure called ledger. This append-only structure is stored by a node called bookie.
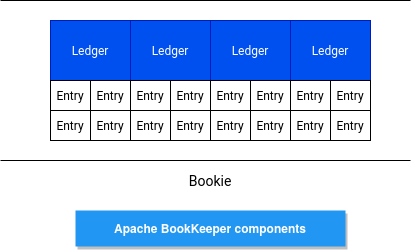
That's a quite high-level view. Let's deep delve into some details not and analyze the class representing our bookie.
Bookie and journals
The bookie server is represented by org.apache.bookkeeper.bookie.Bookie and by analyzing its fields, you will see there is much more than ledgers. The first important extra feature is a journal which, as you can see in the method below, is associated to every ledger:
private Journal getJournal(long ledgerId) {
return journals.get(MathUtils.signSafeMod(ledgerId, journals.size()));
}
Journal is a transaction log where all transactions describing every update, are first written:
/**
* Add an entry to a ledger as specified by handle.
*/
private void addEntryInternal(LedgerDescriptor handle, ByteBuf entry,
boolean ackBeforeSync, WriteCallback cb, Object ctx, byte[] masterKey)
throws IOException, BookieException, InterruptedException {
long ledgerId = handle.getLedgerId();
long entryId = handle.addEntry(entry);
// ...
getJournal(ledgerId).logAddEntry(entry, ackBeforeSync, cb, ctx);
}
It doesn't mean that one ledger stores its entries in one journal though. As you can see in the getJournal method, the journal is computed as a modulo of ledger id divided by the number of journals. And this number of journals comes from the configuration entry called journalDirectories:
this.journalDirectories = Lists.newArrayList();
for (File journalDirectory : conf.getJournalDirs()) {
this.journalDirectories.add(getCurrentDirectory(journalDirectory));
}
journals = Lists.newArrayList();
for (int i = 0; i < journalDirectories.size(); i++) {
journals.add(new Journal(i, journalDirectories.get(i),
conf, ledgerDirsManager, statsLogger.scope(JOURNAL_SCOPE), allocator));
}
Journal doesn't write the entries directly to the files. Instead, it buffers them in an in-memory queue and only later persists them inside an asynchronous thread into a journal file. Every file will have approximately the size defined in this configuration property: journalMaxSizeMB:
boolean shouldRolloverJournal = (lastFlushPosition > maxJournalSize);
// check whether journal file is over file limit
if (shouldRolloverJournal) {
// if the journal file is rolled over, the journal file will be closed after last
// entry is force written to disk.
logFile = null;
continue;
}
Bookie and entry logs
Initially, I thought that the journal is the synonym of Apache Kafka's log structure and the journal files are the log segments. But in fact, it's not really true because the data read by the clients is stored on ledgers. And how does it happen? Do you remember Bookie's addEntryInternal method? At the beginning it retrieves the ledger id and just after that, it adds the entry to the ledger storage:
long ledgerId = handle.getLedgerId();
long entryId = handle.addEntry(entry);
The storage implementation is defined in ledgerStorageClass property (one of: DbLedgerStorage, SortedLedgerStorage or InterleavedLedgerStorage). The simple high-level picture from the beginning, will now look like that:

But, is there a difference between journal and entry log? After all, it would be much easier to keep only one storage. It could be, but there are some differences. Journal contains all entries written in one or multiple ledgers whereas entry log exists at ledger's level:
// HandlerFactoryImpl
@Override
public LedgerDescriptor getHandle(final long ledgerId, final byte[] masterKey) throws IOException, BookieException {
LedgerDescriptor handle = ledgers.get(ledgerId);
if (handle == null) {
handle = LedgerDescriptor.create(masterKey, ledgerId, ledgerStorage);
ledgers.putIfAbsent(ledgerId, handle);
}
handle.checkAccess(masterKey);
return handle;
}
// Bookie
LedgerDescriptor handle = handles.getHandle(ledgerId, key);
recBuff.rewind();
handle.addEntry(Unpooled.wrappedBuffer(recBuff));
In consequence, the journal below would have 3 different ledger storages:
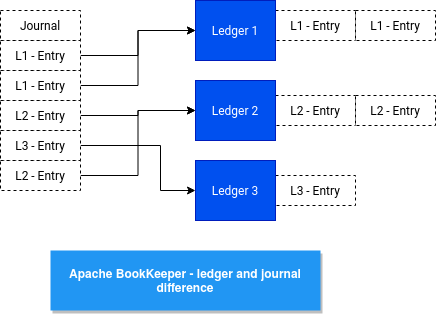
To be honest with you, I made several mistakes during the exploration. First, I thought that the journal logs are synchronized with ledgers only when the journal thread terminates. But this synchronization, in the code represented by the concept of "replaying the logs", happens when the bookie starts. Even though everything is not clear for me at this stage, I'll move forward and check how BookKeeper integrates with Pulsar in the next post of the series, trying to find some extra answers.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about The role of Apache BookKeeper in Apache Pulsar - part 1 here:
Related blog posts:
- Global and local Apache ZooKeeper in Apache Pulsar - part 2
- Global and local Apache ZooKeeper in Apache Pulsar - part 1
- Apache Pulsar - global architecture and local setup
After the focus on the ZooKeeper's role in #ApachePulsar, it's time analyze the BookKeeper's role ⏱️ The first part blog post is online ? https://t.co/NVaoKrjq7t
— Bartosz Konieczny (@waitingforcode) September 6, 2020