
Joining DataFrames can be a performance-sensitive task. After all, it involves matching data from two data sources and keeping matched results in a single place. As you can deduce, the first thinking goes towards shuffle join operation. However, it's not the single strategy implemented in Spark SQL. For some specific use cases another type called broadcast join can be preferred.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is the first one describing different join strategies in Spark. It begins by explaining the logic implemented in broadcast join. Later, in the second part, it shows how to configure this join type.
Broadcast join explained
Broadcast join uses broadcast variables. Instead of grouping data from both DataFrames into a single executor (shuffle join), the broadcast join will send DataFrame to join with other DataFrame as a broadcast variable (so only once). As you can see, it's particularly useful when we know that the size of one of DataFrames is small enough to: be sent through the network and to fit in memory in a single executor. Otherwise either the cost of sending big object through the network will be costly or the OOM error can be thrown. The following schema shows one of potential use cases of broadcast join (a lot of football players data must be enriched with full information about theirs actual clubs):
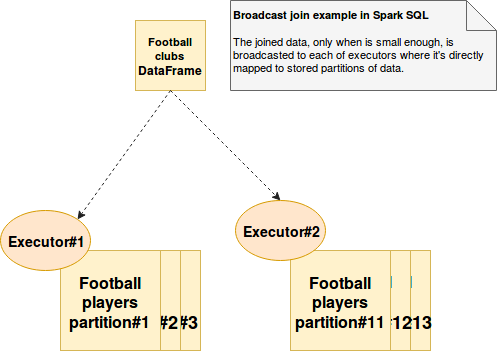
The broadcast join is controlled through spark.sql.autoBroadcastJoinThreshold configuration entry. This property defines the maximum size of the table being a candidate for broadcast. If the table is much bigger than this value, it won't be broadcasted.
In JoinSelection resolver, the broadcast join is activated when the join is one of supported types (inner, cross, left outer, right outer, left semi or left anti) and one of the following conditions is met:
- joined data is marked as broadcastable - it's small enough to be broadcasted. This property is associated to the org.apache.spark.sql.catalyst.plans.logical.Statistics class and by default is false (see the test "broadcast join" should "be executed when broadcast hint is defined - even if the RDBMS default size is much bigger than broadcast threshold")
- joined data size is smaller than spark.sql.autoBroadcastJoinThreshold
The broadcasted object is one of org.apache.spark.sql.execution.joins.HashedRelation implementations (UnsafeHashedRelation or LongHashedRelation) and is backed by corresponding map instance (org.apache.spark.sql.execution.joins.LongToUnsafeRowMap if joined key is an integer or long, or org.apache.spark.unsafe.map.BytesToBytesMap in other cases [String, double, ...]). Later, the broadcasted object is physically send to the executors and put into generated code. Below, you can find the code generated for the case of orders-customers join:
// Here, it tries to find the join key
// in streamed dataset (!= not joined)
boolean scan_isNull1 = scan_row.isNullAt(1);
int scan_value1 = scan_isNull1 ? -1 : (scan_row.getInt(1));
boolean bhj_isNull = scan_isNull1;
long bhj_value = -1L;
if (!scan_isNull1) {
bhj_value = (long) scan_value1;
}
// In this place, the join is made only when the join key was found
// Spark looks for the value corresponding to the join
// key in joined dataset
UnsafeRow bhj_matched = bhj_isNull ? null: (UnsafeRow)bhj_relation.getValue(bhj_value);
final boolean bhj_conditionPassed = true;
if (!bhj_conditionPassed) {
bhj_matched = null;
// reset the variables those are already evaluated.
}
bhj_numOutputRows.add(1);
// Here Spark resolves fields of joined dataset
boolean bhj_isNull3 = true;
int bhj_value3 = -1;
if (bhj_matched != null) {
int bhj_value2 = bhj_matched.getInt(0);
bhj_isNull3 = false;
bhj_value3 = bhj_value2;
}
boolean bhj_isNull5 = true;
UTF8String bhj_value5 = null;
if (bhj_matched != null) {
boolean bhj_isNull4 = bhj_matched.isNullAt(1);
UTF8String bhj_value4 = bhj_isNull4 ? null : (bhj_matched.getUTF8String(1));
bhj_isNull5 = bhj_isNull4;
bhj_value5 = bhj_value4;
}
// Finally the joined values are merged with the original row
if (bhj_isNull3) {
bhj_rowWriter.setNullAt(3);
} else {
bhj_rowWriter.write(3, bhj_value3);
}
if (bhj_isNull5) {
bhj_rowWriter.setNullAt(4);
} else {
bhj_rowWriter.write(4, bhj_value5);
}
Broadcast join example
Below are defined some learning tests showing how to configure broadcast joins and when they can be replaced by other join strategies:
override def beforeAll(): Unit = {
InMemoryDatabase.cleanDatabase()
JoinHelper.createTables()
val customerIds = JoinHelper.insertCustomers(1)
JoinHelper.insertOrders(customerIds, 4)
}
override def afterAll() {
InMemoryDatabase.cleanDatabase()
}
"joined dataset" should "be broadcasted when it's smaller than the specified threshold" in {
val sparkSession: SparkSession = createSparkSession(Int.MaxValue)
import sparkSession.implicits._
val inMemoryCustomersDataFrame = Seq(
(1, "Customer_1")
).toDF("id", "login")
val inMemoryOrdersDataFrame = Seq(
(1, 1, 50.0d, System.currentTimeMillis()), (2, 2, 10d, System.currentTimeMillis()),
(3, 2, 10d, System.currentTimeMillis()), (4, 2, 10d, System.currentTimeMillis())
).toDF("id", "customers_id", "amount", "date")
val ordersByCustomer = inMemoryOrdersDataFrame
.join(inMemoryCustomersDataFrame, inMemoryOrdersDataFrame("customers_id") === inMemoryCustomersDataFrame("id"),
"left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder)
})
val queryExecution = ordersByCustomer.queryExecution.toString()
println(s"> ${queryExecution}")
queryExecution.contains("BroadcastHashJoin [customers_id#20], [id#5], LeftOuter, BuildRight") should be (true)
sparkSession.stop()
}
"joined dataset" should "not be broadcasted because the threshold was exceeded" in {
val sparkSession: SparkSession = createSparkSession(10)
import sparkSession.implicits._
val inMemoryCustomersDataFrame = Seq(
(1, "Customer_1")
).toDF("id", "login")
val inMemoryOrdersDataFrame = Seq(
(1, 1, 50.0d, System.currentTimeMillis()), (2, 2, 10d, System.currentTimeMillis()),
(3, 2, 10d, System.currentTimeMillis()), (4, 2, 10d, System.currentTimeMillis())
).toDF("id", "customers_id", "amount", "date")
val ordersByCustomer = inMemoryOrdersDataFrame
.join(inMemoryCustomersDataFrame, inMemoryOrdersDataFrame("customers_id") === inMemoryCustomersDataFrame("id"),
"left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder)
})
val queryExecution = ordersByCustomer.queryExecution.toString()
println(s"> ${queryExecution}")
queryExecution.contains("BroadcastHashJoin [customers_id#20], [id#5], LeftOuter, BuildRight") should be (false)
queryExecution.contains("ShuffledHashJoin [customers_id#71], [id#56], LeftOuter, BuildRight") should be (true)
sparkSession.stop()
}
"broadcast join" should "be executed when data comes from RDBMS and the default size in bytes is smaller " +
"than broadcast threshold" in {
val sparkSession: SparkSession = createSparkSession(Int.MaxValue, 20L)
val customersDataFrame = getH2DataFrame("customers", sparkSession)
val ordersDataFrame = getH2DataFrame("orders", sparkSession)
val ordersByCustomer = ordersDataFrame
.join(customersDataFrame, ordersDataFrame("customers_id") === customersDataFrame("id"), "left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder.toString())
})
// Here we expect broadcast join. It's because the default size of RDBMS datasource was
// set to quite small number (20) and the condition of joined table size < broadcast threshold
// is respected
val queryExecution = ordersByCustomer.queryExecution.toString()
println("> " + ordersByCustomer.queryExecution)
// Do not assert on more than the beginning of the join.
// Sometimes the ids after customers_id can be different
queryExecution.contains("*BroadcastHashJoin [customers_id") should be (true)
queryExecution.contains("SortMergeJoin [customers_id") should be (false)
}
"sort merge join" should "be executed instead of broadcast when the RDBMS default size is much bigger than" +
"broadcast threshold" in {
val sparkSession: SparkSession = createSparkSession(Int.MaxValue)
val customersDataFrame = getH2DataFrame("customers", sparkSession)
val ordersDataFrame = getH2DataFrame("orders", sparkSession)
// Here the default size of RDBMS datasource is Long.MaxValue.
// It means that we expect the data be too big to broadcast. Instead, it'll be
// joined with sort-merge join.
val ordersByCustomer = ordersDataFrame
.join(customersDataFrame, ordersDataFrame("customers_id") === customersDataFrame("id"), "left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder.toString())
})
val queryExecution = ordersByCustomer.queryExecution.toString()
println("> " + ordersByCustomer.queryExecution)
queryExecution.contains("*BroadcastHashJoin [customers_id") should be (false)
queryExecution.contains("SortMergeJoin [customers_id") should be (true)
}
"broadcast join" should "be executed when broadcast hint is defined -" +
"even if the RDBMS default size is much bigger than broadcast threshold" in {
val sparkSession: SparkSession = createSparkSession(Int.MaxValue)
val customersDataFrame = getH2DataFrame("customers", sparkSession)
val ordersDataFrame = getH2DataFrame("orders", sparkSession)
// Here the default size of RDBMS datasource is Long.MaxValue.
// But we explicitly tells Spark to use broadcast join
val ordersByCustomer = ordersDataFrame
.join(broadcast(customersDataFrame), ordersDataFrame("customers_id") === customersDataFrame("id"), "left")
ordersByCustomer.foreach(customerOrder => {
println("> " + customerOrder.toString())
})
val queryExecution = ordersByCustomer.queryExecution.toString()
println("> " + ordersByCustomer.queryExecution)
queryExecution.contains("**BroadcastHashJoin [customers_id") should be (true)
queryExecution.contains("SortMergeJoin [customers_id") should be (false)
}
private def getH2DataFrame(tableName: String, sparkSession: SparkSession): DataFrame = {
val OptionsMap: Map[String, String] =
Map("url" -> InMemoryDatabase.DbConnection, "user" -> InMemoryDatabase.DbUser, "password" -> InMemoryDatabase.DbPassword,
"driver" -> InMemoryDatabase.DbDriver)
val jdbcOptions = OptionsMap ++ Map("dbtable" -> tableName)
sparkSession.read.format("jdbc")
.options(jdbcOptions)
.load()
}
private def createSparkSession(broadcastThreshold: Int, defaultSizeInBytes: Long = Long.MaxValue): SparkSession = {
SparkSession.builder()
.appName("Spark shuffle join").master("local[*]")
.config("spark.sql.autoBroadcastJoinThreshold", s"${broadcastThreshold}")
.config("spark.sql.defaultSizeInBytes", s"${defaultSizeInBytes}")
.config("spark.sql.join.preferSortMergeJoin", "false")
.getOrCreate()
}
When we want to perform a join of a small dataset with a much bigger one, the broadcast join can be a good solution. As proved in this post, it uses the well known aspect of broadcast variables because the joined dataset is sent once to all executors and merged there with already stored data. Except this broadcasting there are no shuffle operation. But, as we could see that in the second section, even with appropriated configuration of broadcast join threshold, in some cases other join types can be used (e.g. sort-merge). It occurs especially when Spark doesn't know a lot about the data to join and it prefers to overestimate in order to guarantee the best performances.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Broadcast join in Spark SQL here:
Related blog posts:
- Hints on Databricks
- ASOF Join in Apache Spark SQL
- Broadcast join - complementary notes for local shuffle reader
- Regression tests with Apache Spark SQL joins
- Sort-merge join in Spark SQL
#BroadcastJoin in #Spark SQL explained https://t.co/rQzgHU8mF5
— bardev (@waitingforcode) August 6, 2017