
In March I wrote a blog showing how to use accumulators to know the application of each filter statement. Turns out, the solution may not be perfect as mentioned by Aravind in one of the comments. I bet you already have an idea but if not, keep reading. Everything will be clear in the end!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Accumulators 101
An accumulator is a serializable data structure living on the executors those local results get merged into the final one on the driver after each task finishes. The summary below:
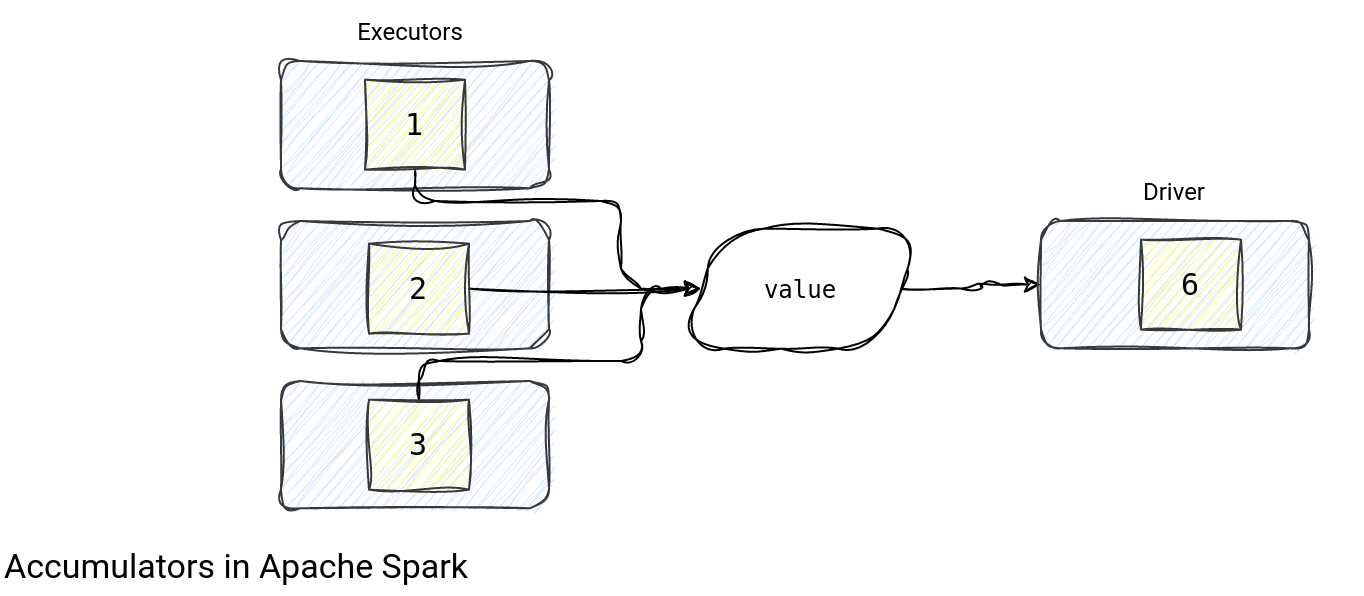
To be more specific:
- Accumulators are also typed, meaning they can work on one input type and generate a different output type: AccumulatorV2[IN, OUT].
- The driver registers the accumulators but the physical data accumulation, hence relying on the tasks data, happens at the tasks level.
- How do the accumulators go to the executors? They're part of the processing functions, therefore, they get serialized as a part of them.
- When one task finishes, it sends a CompletionEvent with all accumulated updates so far. The event also has an information about the task end reason (success, failure, ...).
- How does the driver know about the accumulator to update after each task completion? Each accumulator has a unique id and the driver simply loads its local instance containing all so far merged values, and merges it on its turn with the incoming accumulator:
val acc: AccumulatorV2[Any, Any] = AccumulatorContext.get(id) match { case Some(accum) => accum.asInstanceOf[AccumulatorV2[Any, Any]] case None => throw SparkCoreErrors.accessNonExistentAccumulatorError(id) } acc.merge(updates.asInstanceOf[AccumulatorV2[Any, Any]])
That's pretty much all of the introductory part. The CompletionEvent handling is the key in understanding accumulator reliability.
Reliability
To check the reliability, I'm using a slightly modified example of my accumulator-based filters:
val partitions = 5
val sparkSession = SparkSession.builder().master(s"local[${partitions}, 3]")
.config("spark.task.maxFailures", 3)
.getOrCreate()
val dataset = (0 to 100).map(nr => UserToTest(nr, s"user${nr}")).toDS.repartition(partitions)
val idFilterAccumulator = sparkSession.sparkContext.longAccumulator("idFilterAccumulator")
val evenIdFilterAccumulator = sparkSession.sparkContext.longAccumulator("lowerUpperCaseFilterAccumulator")
val idFilter = new FilterWithAccumulatedResultWithFailure(
(user) => user.id > 0, idFilterAccumulator
)
val evenIdFilter = new FilterWithAccumulatedResultWithFailure(
(user) => user.id % 2 == 0, evenIdFilterAccumulator
)
val filteredInput = dataset.filter(idFilter.filter _).filter(evenIdFilter.filter _)
filteredInput.show(false)
println(s"idFilterAccumulator=${idFilterAccumulator.count}")
println(s"evenIdFilterAccumulator=${evenIdFilterAccumulator.count}")
The filtering logic should fail twice for the user id number 11:
class FilterWithAccumulatedResultWithFailure(filterMethod: (UserToTest) => Boolean, resultAccumulator: LongAccumulator) extends Serializable {
def filter(userToTest: UserToTest): Boolean = {
val result = filterMethod(userToTest)
if (!result) resultAccumulator.add(1L)
if (!result && userToTest.id == 11 && FailureFlagHolder.isFailed.incrementAndGet() < 3) {
throw new RuntimeException("temporary error")
}
result
}
}
object FailureFlagHolder {
val isFailed = new AtomicInteger(0)
}
After running the code, the results are pretty convincing:
+---+-------+ |id |login | +---+-------+ |28 |user28 | |44 |user44 | ... |2 |user2 | |30 |user30 | +---+-------+ only showing top 20 rows idFilterAccumulator=1 evenIdFilterAccumulator=50
The id filter filtered out only 1 row while the even id filter removed a half of the records. If the accumulators weren't reliable, the even id filter should have removed more than 50 records. What is the code proving that reliability actually? Remember the CompletionEvent. It stores a task end reason. Different supported statuses are:
case object Success extends TaskEndReason sealed trait TaskFailedReason extends TaskEndReason case object Resubmitted extends TaskFailedReason case class FetchFailed(...) extends TaskFailedReason case class ExceptionFailure(...) extends TaskFailedReason case object TaskResultLost extends TaskFailedReason case class TaskKilled(...) extends TaskFailedReason
Whenever a CompletionEvent is sent, DAGScheduler handles it in private[scheduler] def handleTaskCompletion(event: CompletionEvent). Depending on the status, i.e. either the failure is fatal or not (retryable), the DAGScheduler updates the accumulators:
event.reason match {
case Success =>
task match {
case rt: ResultTask[_, _] =>
val resultStage = stage.asInstanceOf[ResultStage]
resultStage.activeJob match {
case Some(job) =>
// Only update the accumulator once for each result task.
if (!job.finished(rt.outputId)) {
updateAccumulators(event)
}
case None => // Ignore update if task's job has finished.
}
case _ =>
updateAccumulators(event)
}
case _: ExceptionFailure | _: TaskKilled => updateAccumulators(event)
case _ =>
}
The point is, if there is an exception, the task end reason is the ExceptionFailure, so logically, we should see the counters doubled, shouldn't we? No, we shouldn't and the magic is hidden inside AccumulatorMetadata's countFailedValues property which defaults to false:
abstract class AccumulatorV2[IN, OUT] extends Serializable {
private[spark] var metadata: AccumulatorMetadata = _
private[this] var atDriverSide = true
private[spark] def register(
sc: SparkContext, name: Option[String] = None,
countFailedValues: Boolean = false): Unit = {
if (this.metadata != null) {
throw new IllegalStateException("Cannot register an Accumulator twice.")
}
this.metadata = AccumulatorMetadata(AccumulatorContext.newId(), name, countFailedValues)
AccumulatorContext.register(this)
Now, when Spark creates the CompletionEvent with the accumulators, it doesn't include the user-defined accumulators and value-sensitive internal accumulators for a failed task:
private[spark] abstract class Task[T](
// ...
def collectAccumulatorUpdates(taskFailed: Boolean = false): Seq[AccumulatorV2[_, _]] = {
if (context != null) {
// Note: internal accumulators representing task metrics always count failed values
context.taskMetrics.nonZeroInternalAccums() ++
// zero value external accumulators may still be useful, e.g. SQLMetrics, we should not
// filter them out.
context.taskMetrics.externalAccums.filter(a => !taskFailed || a.countFailedValues)
} else {
Seq.empty
}
}
Turns out, I also badly judged the accumulator's reliability. At first glance, this countFailedValues flag is hidden and we may have an impression that the accumulators are not resilient but except a few internal accumulators, Apache Spark takes care of updating only the accumulators of the successfully completed tasks.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩