
The Structured Streaming guarantees end-to-end exactly-once delivery (in micro-batch mode) through the semantics applied to state management, data source and data sink. The state was more covered in the post about the state store but 2 other parts still remain to discover.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is divided in 2 main parts. The first part focuses on data sources and explains how they contribute in the end-2-end exactly once delivery in the case of micro-batch processing. The second part is about the sinks while the last summarizes all theoretical points in an example.
Data sources
In terms of exactly-once processing the source must be replayable. That said it must allow to track the current read position and also to start the reprocessing from the last failure position. Both properties help to recover the processing state after any arbitrary failure (driver or executor included). A good examples of replayable sources are Apache Kafka or its cloud-based collegue, Amazon Kinesis. Both are able to track the currently read elements - Kafka with offsets and Kinesis with sequence numbers. A good example of not replayable sources is org.apache.spark.sql.execution.streaming.MemoryStream that can't be restored after closing the application because the data is stored in volatile memory.
The processed offsets are tracked thanks to the checkpoint mechanism. In Structured Streaming the items stored in checkpoint files are mainly the metadata about the offsets processed in the current batch. The checkpoint are stored in the location specified in checkpointLocation option or spark.sql.streaming.checkpointLocation configuration entry.
In the case of micro-batch execution the checkpoint integrates in the following schema:
- the checkpoint location is passed from DataStreamWriter#startQuery() method to StreamExecution abstract class through StreamingQueryManager's startQuery and createQuery methods.
- StreamExecution initializes the object org.apache.spark.sql.execution.streaming.OffsetSeqLog. This object represents the WAL log recording the offsets present in each of processed batches.
This field represents the logic of handling offsets in data sources. The offsets for the current micro-batch (let's call it N) are always written before the processing is done. This fact assumes also that all data from the previous micro-batch (N-1) are correctly written to the output sink. It's represented in the following code snippet coming from org.apache.spark.sql.execution.streaming.MicroBatchExecution#constructNextBatch():updateStatusMessage("Writing offsets to log") reportTimeTaken("walCommit") { assert(offsetLog.add( currentBatchId, availableOffsets.toOffsetSeq(sources, offsetSeqMetadata)), s"Concurrent update to the log. Multiple streaming jobs detected for $currentBatchId") logInfo(s"Committed offsets for batch $currentBatchId. " + s"Metadata ${offsetSeqMetadata.toString}") // NOTE: The following code is correct because runStream() processes exactly one // batch at a time. If we add pipeline parallelism (multiple batches in flight at // the same time), this cleanup logic will need to change. // Now that we've updated the scheduler's persistent checkpoint, it is safe for the // sources to discard data from the previous batch. if (currentBatchId != 0) { val prevBatchOff = offsetLog.get(currentBatchId - 1) if (prevBatchOff.isDefined) { prevBatchOff.get.toStreamProgress(sources).foreach { case (src: Source, off) => src.commit(off) case (reader: MicroBatchReader, off) => reader.commit(reader.deserializeOffset(off.json)) } } else { throw new IllegalStateException(s"batch $currentBatchId doesn't exist") } } // It is now safe to discard the metadata beyond the minimum number to retain. // Note that purge is exclusive, i.e. it purges everything before the target ID. if (minLogEntriesToMaintain < currentBatchId) { offsetLog.purge(currentBatchId - minLogEntriesToMaintain) commitLog.purge(currentBatchId - minLogEntriesToMaintain) } } - if the offset checkpoint file already exist when the streaming query starts, the engine tries to retrieve previously processed offsets in populateStartOffsets(sparkSessionToRunBatches: SparkSession). The resolution algorithm is done in the following steps:
- resolve the id of the current batch, the offsets to process (from Nth checkpoint file) and the offsets committed in N-1 batch. At this moment the offsets from Nth batch are considered as available to the processing and the ones from N-1 batch as already committed
- identify the real current batch. When batch id of the Nth offsets is the same as the last batch id written in the commit logs, the engine sets the offsets offsets as committed ones and increments the batch id by 1. A new micro-batch is then recomputed by querying the sink for new offsets to process.
Otherwise the resolved micro-batch is considered as the real current batch and the processing starts from offsets to process.
To fully understand this process it's important to also know what the commit log is. Since it's more related to the sink it'll detailed in the next part.
Data sinks
The commit log is a WAL recording the ids of completed batches. It's used to check if given batch was fully processed, i.e. if all offsets were read and if the output was committed to the sink. Internally it's represented as org.apache.spark.sql.execution.streaming.CommitLog and it's executed immediately before the processing of the next trigger, as in the following schema:
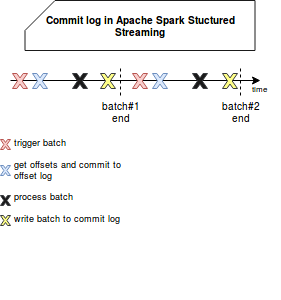
Indeed, neither the replayable source nor commit log don't guarantee exactly-once processing itself. What if the batch commit fails ? As told previously, the engine will detect the last committed offsets as offsets to reprocess and output once again the processed data to the sink. It'll obviously lead to a duplicated output. But it'd be the case only when the writes and the sink aren't idempotent.
An idempotent write is the one that generates the same written data for given input. The idempotent sink is the one that writes given generated row only once, even if it's sent multiple times. A good example of such sink are key-value data stores. Now, if the writer is idempotent, obviously it generates the same keys every time and since the row identification is key-based, the whole process is idempotent. Together with replayable source it guarantees exactly-once end-2-end processing.
Exactly-once processing example
To see how exactly-once end-to-end processing works, we'll take a simple example of files that are transformed and written back as another files in different directory. To illustrate a failure and thus fault tolerance, the first processing of one entry will fail:
override def beforeAll(): Unit = {
Path(TestConfiguration.TestDirInput).createDirectory()
Path(TestConfiguration.TestDirOutput).createDirectory()
for (i <- 1 to 10) {
val file = s"file${i}"
val content =
s"""
|{"id": 1, "name": "content1=${i}"}
|{"id": 2, "name": "content2=${i}"}
""".stripMargin
File(s"${TestConfiguration.TestDirInput}/${file}").writeAll(content)
}
}
override def afterAll(): Unit = {
Path(TestConfiguration.TestDirInput).deleteRecursively()
Path(TestConfiguration.TestDirOutput).deleteRecursively()
}
"after one failure" should "all rows should be processed and output in idempotent manner" in {
for (i <- 0 until 2) {
val sparkSession: SparkSession = SparkSession.builder()
.appName("Spark Structured Streaming fault tolerance example")
.master("local[2]").getOrCreate()
import sparkSession.implicits._
try {
val schema = StructType(StructField("id", LongType, nullable = false) ::
StructField("name", StringType, nullable = false) :: Nil)
val idNameInputStream = sparkSession.readStream.format("json").schema(schema).option("maxFilesPerTrigger", 1)
.load(TestConfiguration.TestDirInput)
.toDF("id", "name")
.map(row => {
val fieldName = row.getAs[String]("name")
if (fieldName == "content1=7" && !GlobalFailureFlag.alreadyFailed.get() && GlobalFailureFlag.mustFail.get()) {
GlobalFailureFlag.alreadyFailed.set(true)
GlobalFailureFlag.mustFail.set(false)
throw new RuntimeException("Something went wrong")
}
fieldName
})
val query = idNameInputStream.writeStream.outputMode("update").foreach(new ForeachWriter[String] {
override def process(value: String): Unit = {
val fileName = value.replace("=", "_")
File(s"${TestConfiguration.TestDirOutput}/${fileName}").writeAll(value)
}
override def close(errorOrNull: Throwable): Unit = {}
override def open(partitionId: Long, version: Long): Boolean = true
}).start()
query.awaitTermination(15000)
} catch {
case re: StreamingQueryException => {
println("As expected, RuntimeException was thrown")
}
}
}
val outputFiles = Path(TestConfiguration.TestDirOutput).toDirectory.files.toSeq
outputFiles should have size 20
val filesContent = outputFiles.map(file => Source.fromFile(file.path).getLines.mkString(""))
val expected = (1 to 2).flatMap(id => {
(1 to 10).map(nr => s"content${id}=${nr}")
})
filesContent should contain allElementsOf expected
}
object TestConfiguration {
val TestDirInput = "/tmp/spark-fault-tolerance"
val TestDirOutput = s"${TestDirInput}-output"
}
object GlobalFailureFlag {
var mustFail = new AtomicBoolean(true)
var alreadyFailed = new AtomicBoolean(false)
}
Apache Spark Structured Streaming, through replayable sources, fault-tolerant state management, idempotent sinks guarantees exactly-once delivery semantic. As shown in this post, it achieves that thanks to checkpointing. For the sources the engine checkpoints the available offsets that can be later converted to already processed ones. In the case of sinks, the fault-tolerance is provided by commit log when, after the data processing, are submitted the ids of successful batches. And the final third part shown how both parts can work together to provide exactly once processing.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Fault tolerance in Apache Spark Structured Streaming here:
- Apache Spark 2.0: A Deep Dive Into Structured Streaming - by Tathagata Das Spark structured steaming from kafka - last message processed again after resume from checkpoint
Related blog posts:
Today on waitingforcode the focus on the fault tolerance mechanism in #ApacheSparkStructuredStreaming micro-batch processing https://t.co/BUk5olSjn4
— bardev (@waitingforcode) March 31, 2018