
Previously we discovered inner stream-to-stream joins in Apache Spark but they aren't the single supported type. Another one are outer joins that let us to combine streams without matching rows.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is about outer joins in Structured Streaming module. Its first section presents some theoretical points about this kind of joins. The second one shows how it can be implemented through some Scala examples.
When matching is optional
Streaming outer joins aren't different from classical, batch-like ones. With them we always get all rows from one side, even if some of them don't have matches in the joining dataset. For bounded data sources like RDBMS, such no-matches are returned directly with null representing row in the other side. But the logic of unbounded sources is different. Because of different characteristics, such as network latency impact or offline device producing an event, we may not have all joining elements at given moment. Thus, we must be able to defer the physical join up to the moment we're sure that the most of rows to join will come. To do so, we need to store the rows of one side somewhere. And if you remember some notes from the post Inner joins between streams in Apache Spark Structured Streaming, Apache Spark uses state store for it. The following image shows that from a bird's-eve view:
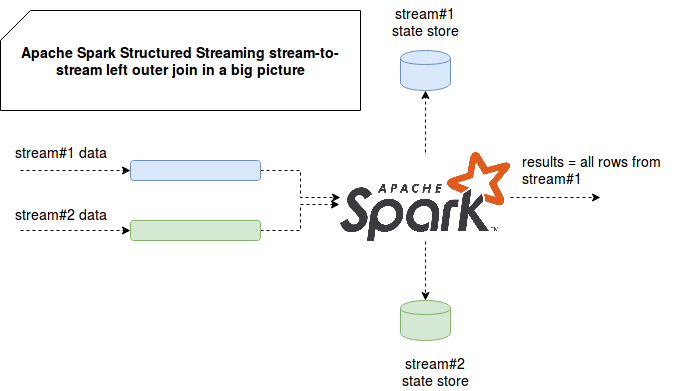
The image shows clearly that, as in the case of inner join with watermark, the rows are buffered in state store. And outer join also uses the idea of watermark and range query conditions to decide when given row is not supposed to receive any new matches in the second stream. It's why doing outer join without watermark is simply not possible:
it should "fail without watermark and range condition on watermark in the query" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") ,
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
it should "fail without watermark and only with range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
expr("joinedEventTimeWatermark < mainEventTimeWatermark + interval 2 seconds"),
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
Watermark and range queries
Let's see now what happens if, unlike above, we define a watermark on a column:
it should "emit rows before accepted watermark" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
// We send keys: 2, 3, 4, 5, 6 in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 5000L
while (query.isActive) {
if (key % 2 == 0) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
} else {
mainEventsStream.addData(MainEvent(s"key${key}", startingTime, new Timestamp(startingTime)))
}
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(keyAndValue => keyAndValue.key != "key1")
.groupBy(testedValues => testedValues.key)
groupedByKeys.keys shouldNot contain allOf("key2", "key3", "key4", "key5", "key6")
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
val firstRowWithoutMatch = values.find(joinResult => joinResult.joinedEventMillis.isEmpty)
firstRowWithoutMatch shouldBe defined
val firstRowWithMatch = values.find(joinResult => joinResult.joinedEventMillis.nonEmpty)
firstRowWithMatch shouldBe defined
values.foreach(joinResult => {
assertJoinResult(joinResult)
})
}
With outer join we could wonder which results are returned - only the ones in late regarding to watermark or all independently on the watermark value ? The following test shows that join results are conditioned by matching. That said, the matched rows are returned as soon as it's possible while not matched ones only after reaching watermark time:
it should "prove the joined rows are emitted at every batch and not after watermark expiration" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark",
current_timestamp.as("generationTime"))
.withWatermark("mainEventTimeWatermark", "30 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "30 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 60000L // 60 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query)
while (query.isActive) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(joinResult => joinResult.key != "key1")
.groupBy(testedValues => testedValues.key)
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
values.nonEmpty shouldBe true
values.foreach(joinResult => {
val diffProcessingEventTime = joinResult.processingTime - joinResult.rowCreationTime.get
// It clearly shows that matched rows are processed as soon as a match is found, with the next processing
// time window
(diffProcessingEventTime/1000 < 30) shouldBe true
})
}
Another point to consider in writing outer join queries is that this kind of join won't work when watermark is not a join key. If we want to check whether watermark of one side is greater or lower than the watermark of another side, we must define the range condition, as in the following test:
it should "fail if the watermark is not a join key and there is no range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().repartition(1).select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().repartition(1).select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
expr("joinedEventTimeWatermark >= mainEventTimeWatermark"),
"leftOuter")
val exception = intercept[AnalysisException] {
stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
}
exception.getMessage() should include("Stream-stream outer join between two streaming DataFrame/Datasets is not " +
"supported without a watermark in the join keys, or a watermark on the nullable side and an appropriate range condition")
}
it should "emit rows before accepted watermark with range condition" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().repartition(1).select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().repartition(1).select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
// Either equality criteria on watermark or not equality criteria on watermark with range conditions are required for outer joins
expr("joinedEventTimeWatermark >= mainEventTimeWatermark") &&
expr("joinedEventTimeWatermark < mainEventTimeWatermark + interval 4 seconds"),
"leftOuter")
val query = stream.writeStream.foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
// We send keys: 2, 3, 4, in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 4000L
stateManagementHelper.sendPairedKeysWithSleep(s"key2", startingTime)
stateManagementHelper.sendPairedKeysWithSleep(s"key3", startingTime + 1000)
stateManagementHelper.sendPairedKeysWithSleep(s"key4", startingTime + 2000)
key = 5
startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) + 1000L
while (query.isActive) {
val keyName = s"key${key}"
val flushed = if (key % 4 == 0) {
// here we sent the events breaking range condition query
val joinedEventTime = startingTime + 6000
stateManagementHelper.collectAndSend(keyName, startingTime, Some(joinedEventTime), withJoinedEvent = true)
} else if (key % 3 == 0) {
// Here we send only main key
stateManagementHelper.collectAndSend(keyName, startingTime, None, withJoinedEvent = false)
} else {
// Here we sent an "in-time event"
stateManagementHelper.collectAndSend(keyName, startingTime, Some(startingTime+1000), withJoinedEvent = true)
}
if (key >= 12) {
startingTime += 1000L
}
key += 1
if (flushed) {
Thread.sleep(1000L)
}
}
}
}).start()
query.awaitTermination(120000)
val groupedByKeys = TestedValuesContainer.values.filter(joinResult => joinResult.key != "key1").
groupBy(testedValues => testedValues.key)
// Ensure that rows with event time before new watermark (00:00:08) were not processed
groupedByKeys.keys shouldNot contain allOf("key2", "key3", "key4")
// Some checks on values
val values = groupedByKeys.flatMap(keyAndValue => keyAndValue._2)
// For the joined rows violating range condition query we shouldn't see the event time of
// nullable side
val lateJoinEvents = values
.filter(joinResult => joinResult.key.substring(3).toInt % 4 == 0 && joinResult.joinedEventMillis.isEmpty)
lateJoinEvents.nonEmpty shouldBe true
// Here we check whether for the case of "only main keys" the rows are returned
val noMatchEvents = values
.find(joinResult => joinResult.key.substring(3).toInt % 3 == 0 && joinResult.joinedEventMillis.isEmpty)
noMatchEvents.nonEmpty shouldBe true
// Here we validate if some subset of fully joined rows were returned
val matchedEvents = values.find(joinResult => joinResult.joinedEventMillis.nonEmpty)
matchedEvents.nonEmpty shouldBe true
values.filter(joinResult => joinResult.joinedEventMillis.nonEmpty).foreach(joinResult => {
// joined row has always event time 1 second bigger than the main side's row
(joinResult.joinedEventMillis.get - joinResult.mainEventMillis) shouldEqual 1000L
})
}
And obviously, even if we're working on streams, the outer join follows the same rules as for bounded data sources. It means that if we've a non watermark condition in ON clause, it'll automatically discard all events - independently if they've matching row in other side or not:
it should "return no rows because of mismatched condition on join query" in {
val mainEventsStream = new MemoryStream[MainEvent](1, sparkSession.sqlContext)
val joinedEventsStream = new MemoryStream[JoinedEvent](2, sparkSession.sqlContext)
val mainEventsDataset = mainEventsStream.toDS().select($"mainKey", $"mainEventTime", $"mainEventTimeWatermark")
.withWatermark("mainEventTimeWatermark", "2 seconds")
val joinedEventsDataset = joinedEventsStream.toDS().select($"joinedKey", $"joinedEventTime", $"joinedEventTimeWatermark")
.withWatermark("joinedEventTimeWatermark", "2 seconds")
val stream = mainEventsDataset.join(joinedEventsDataset, mainEventsDataset("mainKey") === joinedEventsDataset("joinedKey") &&
mainEventsDataset("mainEventTimeWatermark") === joinedEventsDataset("joinedEventTimeWatermark") &&
// This condition invalidates every row
joinedEventsDataset("joinedEventTime") <= 0,
"leftOuter")
val query = stream.writeStream.trigger(Trigger.ProcessingTime(5000L)).foreach(RowProcessor).start()
while (!query.isActive) {}
new Thread(new Runnable() {
override def run(): Unit = {
val stateManagementHelper = new StateManagementHelper(mainEventsStream, joinedEventsStream)
var key = 0
val processingTimeFrom1970 = 10000L // 10 sec
stateManagementHelper.waitForWatermarkToChange(query, processingTimeFrom1970)
println("progress changed, got watermark" + query.lastProgress.eventTime.get("watermark"))
key = 2
// We send keys: 2, 3, 4, 5, 7 in late to see watermark applied
var startingTime = stateManagementHelper.getCurrentWatermarkMillisInUtc(query) - 5000L
while (query.isActive) {
if (key % 2 == 0) {
stateManagementHelper.sendPairedKeysWithSleep(s"key${key}", startingTime)
} else {
mainEventsStream.addData(MainEvent(s"key${key}", startingTime, new Timestamp(startingTime)))
}
startingTime += 1000L
key += 1
}
}
}).start()
query.awaitTermination(120000)
// As you can see, since the extra JOIN condition invalidates every output. For the ones without match on joined
// side it's normal since joinedEventTime is null. For the ones with matching it's also normal since the value
// of this column is never lower than 0.
TestedValuesContainer.values shouldBe empty
}
Throughout the examples presented in this post we could learn some specificites about streaming outer joins in Apache Spark Structured Streaming. As shortly described in the first section, they let us to make joins with streams potentially missing joined values. It's a real use case since we don't always observe a reaction (human, mechanical, ...) on emitted event. But as proven in the code snippets, outer joins won't work without watermark as join key or a range query condition.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Stream-to-stream joins internals
- Stream-to-stream state management
- Inner joins between streams in Apache Spark Structured Streaming
The series about joins in #ApacheSpark #StructuredStreaming continues. This time the post is about outer joins mechanism https://t.co/f8DCr3cwEq
— bardev (@waitingforcode) September 2, 2018