
I presented in my previous posts how to use a file sink in Structured Streaming. I focused there on the internal execution and its use in the context of data reprocessing. In this post I will address a few of the previously described points.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post I will first present the problem that, depending on your trade-offs, may not be necessarily a problem. Later on, I will propose 2 possible solutions. The first one handles it without altering Apache Spark codebase whereas the second one introduces a small change in the compression part.
Problem statement
The problem with the current implementation, or rather not a problem but the trade-off that you have to make, is to decide whether you allow some latency in retrieving small metadata files or not. If you do and can, for instance, set the number of not compacted files to a very big number satisfying your reprocessing needs, you don't need to worry. But what if you don't want to keep a lot of small files?
Backup copy
The first idea that comes to my mind is to use a backup pipeline that will copy the files to another, long-term storage not monitored by Apache Spark and use them for the reprocessing if needed. The whole idea is represented in the following schema:
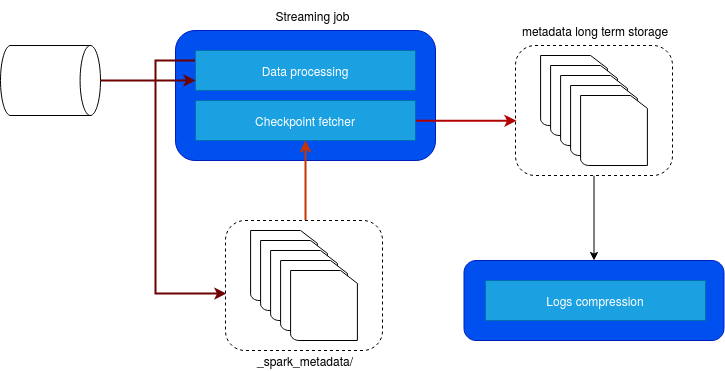
So, the code is running in the background, on the driver. I used that approach for the demo simplicity but it could also be a Dockerized container managed by Kubernetes, deployed at the same time as the streaming job.
A nice thing is that you can do whatever you want with these "backup" files. You can store them in a compressed format or put them into another storage to not penalize Apache Spark with too many small metadata files. On the other hand, this approach has also some drawbacks:
- The process of backup is decoupled from the streaming job. It means that if the backup process fails during the weekend and the streaming job executes correctly, and in consequence, compresses the files in _metadata, you will need some manual work to put the things back together.
- The data is physically copied - even though the metadata files are smaller than the data files, it's always an extra overhead.
- Finally, to make your job fully recoverable, you will need to do the same copy for all files, so for the checkpoint and state as well.
Overall, that's a lot of things to do. That's why there is another solution that requires some changes in Apache Spark codebase.
Batch number in the compressed file - prototype
To recall, the content of the compressed manifest file created by every micro-batch looks like that:
{"path":"file:///tmp/files_sink_manifest/output/part-00000-3346647b-f488-4860-bc44-41a57e42802c-c000.json","size":78,"isDir":false,"modificationTime":1587220544000,"blockReplication":1,"blockSize":33554432,"action":"add"}
{"path":"file:///tmp/files_sink_manifest/output/part-00001-4475d324-4546-4597-beca-5a58235c78de-c000.json","size":52,"isDir":false,"modificationTime":1587220544000,"blockReplication":1,"blockSize":33554432,"action":"add"}
What's the problem? Let's imagine that I want to reprocess the data from the micro-batch 101. I invalidated all checkpoint location files to restart my processing from the correct Apache Kafka offset. But some files between 101 and the last micro-batch version (let's say 300) were compressed to the files number 100, 150, 200, 250, and 300, and at the same time, the not compressed ones were deleted. I have then no way to know what files between 100 and 150 I have to clean up before restarting my pipeline. Even though I would like to start from 100, I don't know what files were created by the batch 100. Normally that should be the files from the first X lines but it's rather a conventional approach.
To address this issue, we could refactor the CompactibleFileStreamLog#compact method and add the batch number for every line that way:
case class CompactedLogs(batchId: Long, logs: Array[T])
private def compact(batchId: Long, logs: Array[T]): Boolean = {
val validBatches = getValidBatchesBeforeCompactionBatch(batchId, compactInterval)
val allLogs = validBatches.map { id =>
val logsInTheBatch = super.get(id).getOrElse {
throw new IllegalStateException(
s"${batchIdToPath(id)} doesn't exist when compacting batch $batchId " +
s"(compactInterval: $compactInterval)")
}
CompactedLogs(id, logsInTheBatch)
}.flatten :+ CompactedLogs(batchId, logs)
// Return false as there is another writer.
super.add(batchId, compactLogs(allLogs).toArray)
}
After the compression, we should receive the compressed file with this content:
{"batchId": 1, "files": [...]}
{"batchId": 2, "files": [...]}
{"batchId": 3, "files": [...]}
Now, to clean up the resources, we could have something like:
case class CompactedLogs(batchId: Long, files: Array[SinkFileStatus])
val maxMicroBatchToKeep = 100
FileUtils.readFileToString(new File("100.compress")).lines
// Drop the first line, it's only the version flag
.drop(1)
.foreach(jsonLine => {
val log = CompactedLogs(0, Seq.empty) // convert back with JsonMapper or any other way
if (log.batchId > maxMicroBatchToKeep) {
log.files.foreach(fileStreamSinkLog => {
// delete the {{fileStreamSinkLog.path}} with an appropriate API (HDFS, S3, GCS,...)
})
}
})
A nice thing about the change is that it doesn't involve any extra cost of fetching the data. The single drawback is the few extra bytes written by the JSON schema but it can be the trade-off to accept to keep the granularity. It's only a proposal, I've never experienced it in real life but maybe it can be used as a discussion base to make our pipelines more resilient and easily replayable.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- File sink and Out-Of-Memory risk
- File sink and manifest compaction
- File sink in Apache Spark Structured Streaming
The last post about #ApacheSpark #StructuredStreaming file sink is online. This time I proposed a prototype to enhance the format and persist batch number alongside the written files https://t.co/BvLZKpsGba
— Bartosz Konieczny (@waitingforcode) June 14, 2020