
Apache Spark is infamous for its correctness issue for chained stateful operations. Fortunately things get improved in each release. The most recent one, the 3.4.0, also got some important changes on that field!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Watermarks
A watermark controls late data in streaming jobs. It tracks the oldest record possible that we can process and also determines when we can emit state-based outcomes, such as windowed aggregates. That's one of the simplest definitions. However, the definition is too simple when you analyze the watermark implementations in data processing sâce.
Let's start with our focus of this blog post, Apache Spark Structured Streaming. The watermark specificities, excluding the changes made in the 3.4.0 release, are:
- It's supported only for the aggregated queries that use the watermark column in the aggregation. I wrote about it 3 years ago in Watermarks and not grouped query - why they don't work.
- It relies on a global watermark. The watermark is global for all operators of the micro-batch. It's related to a so-called correctness issue and the error you may get if you launch the pipeline involving multiple chained stateful operations [note: it's not fully true in the 3.4.0 but we'll see that later]:
val errorMsg = "Detected pattern of possible 'correctness' issue " + "due to global watermark. " + "The query contains stateful operation which can emit rows older than " + "the current watermark plus allowed late record delay, which are \"late rows\"" + " in downstream stateful operations and these rows can be discarded. " + "Please refer the programming guide doc for more details. If you understand " + "the possible risk of correctness issue and still need to run the query, " + "you can disable this check by setting the config " + "`spark.sql.streaming.statefulOperator.checkCorrectness.enabled` to false."
- Watermark is fully managed by the framework. You don't have any access to it from the public API.
Apache Flink considers watermark a bit differently:
- There is no need to aggregate on the watermark column. The framework can track the progress even of a simple filter-map query and record the watermark. Immerok demonstrated that for Apache Flink in one of their great recipes.
- The recipe also shows a different thing. Late data is available to the users. Sure, it requires some coding effort to access it but it is relatively simple to write. Moreover, window-based processing provides native functions like sideOutputLateData to forward late data to a dedicated side output target. Besides, Apache Flink also has a dedicated component called watermark generator that can define a custom and often even very complex logic for the watermark values.
- Idleness management. The watermark has a built-in mechanism to deal with idle partitions. When used, a partition remaining idle for too long won't be involved in the watermark generation. The feature prevents stuck jobs due to empty partitions and not advancing watermark.
- Each parallel subtask of a source generates an independent watermark usually. This value later flows through the program and in some scenarios, such as key-based operations or unions, multiple watermarks from the upstream tasks transform into a single watermark defined as the minimum of the input watermarks. David Anderson explains that pretty clearly in one of his StackOverflow contributions:
Watermarks are, in a sense, "global," but with the following caveats:
1. each parallel instance of assignTimestampsAndWatermarks does its own watermarking
2. when an operator connects two streams (e.g., a CoProcessFunction), its watermark is the minimum of the incoming watermarks
3.with Kafka you can arrange for per-kafka-partition watermarking
To complete the picture, Apache Beam with the focus on the Dataflow runner, gives an excellent explication of the watermarks in a streaming job. The linked document introduces:
- A global watermark assigned to each distributed data collection (PCollection). The collection can emit an output watermark if it's gets processed.
- A local watermark assigned to each transform.
- A Garbage Collector watermark used for buffered data expiration, such as emitting windows results.
Correctness issue in Apache Spark
To understand the issue let's move back on time, to the Apache Spark 3.0. It's the version where Jungtaek Lim added a warning message for the queries using multiple stateful operations, such as chained stream-to-stream joins (SPARK-28074).
val errorMsg = "Detected pattern of possible 'correctness' issue " + "due to global watermark. " + "The query contains stateful operation which can emit rows older than " + "the current watermark plus allowed late record delay, which are \"late rows\"" + " in downstream stateful operations and these rows can be discarded. " + "Please refer the programming guide doc for more details. If you understand " + "the possible risk of correctness issue and still need to run the query, " + "you can disable this check by setting the config " + "`spark.sql.streaming.statefulOperator.checkCorrectness.enabled` to false."
More specifically, what does it mean, a correctness issue? Let's take a look at the following picture. As you can see, there is a join between 2 datasets and its result is the left side of another join. The problem with this double join is that the watermark invalidates the leftmost rows and this invalidation hides them from the 2nd join. Because of that the output for the Micro-batch 1 is empty even though the rows 1, 2 and 3 expired and should be returned as the left part of the left outer join without matching the right side.
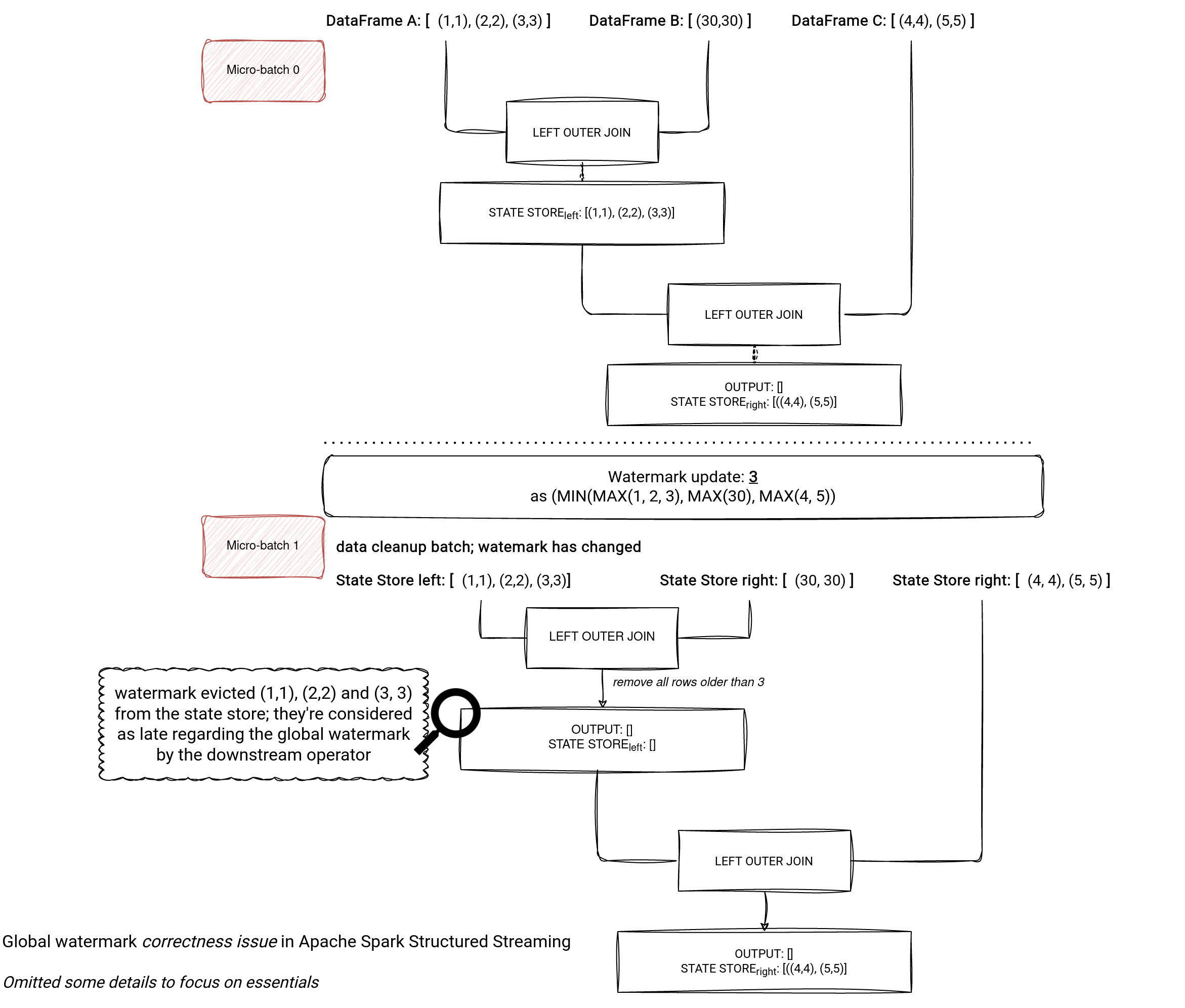
If we had only the first join, the data expiration step would return the expired rows because the watermark eviction precedes the output generation:
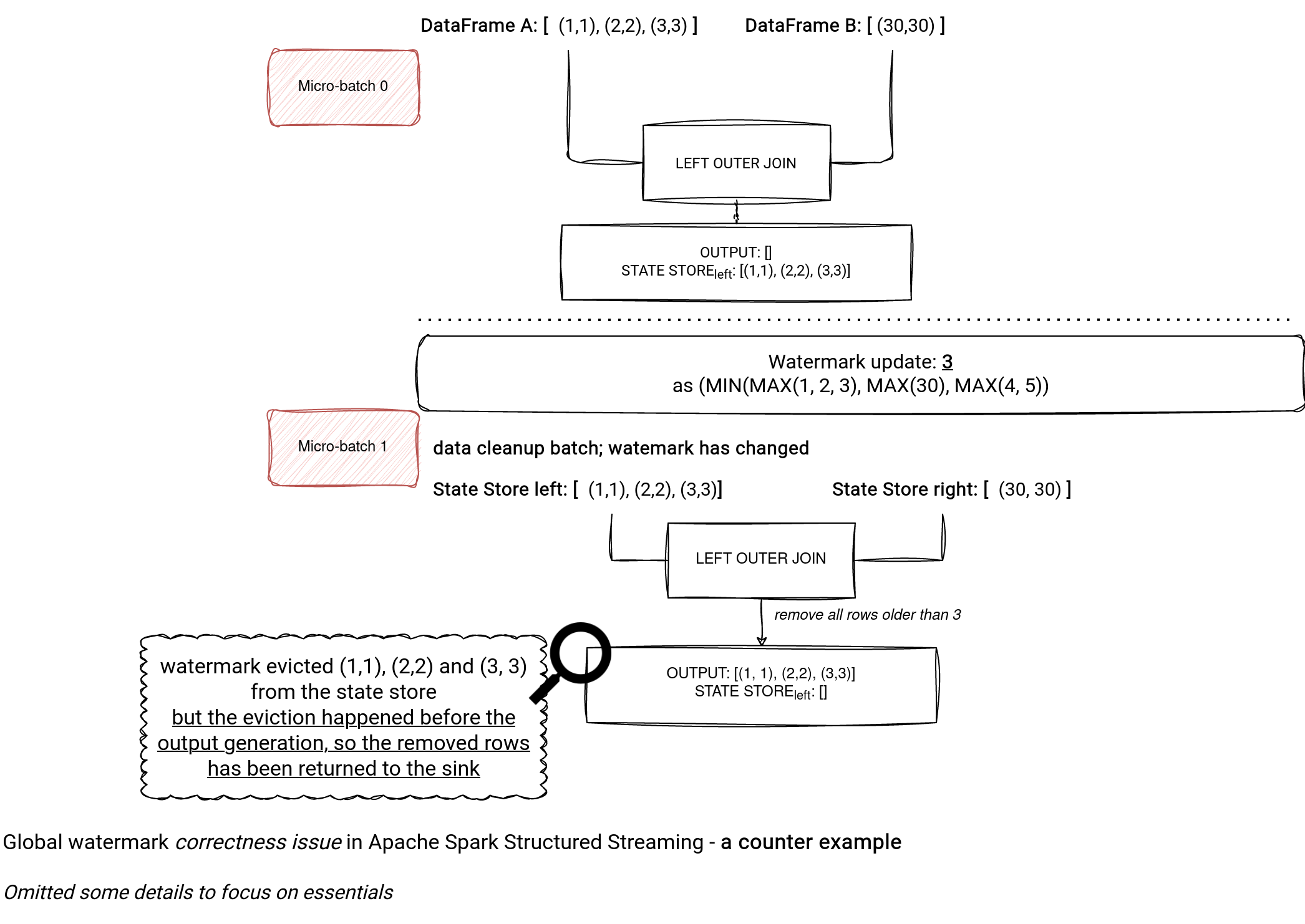
I also wrote some code for the issue that you can get from my Github repo.
Late record filtering fixes
So, what has changed recently? Alex Balikov proposed an improvement to allow chaining stateful operations not producing delayed records, such as a time-equality streaming join followed by an aggregation. Below you can find an example of that code working for the 3.4.0 release even with the spark.sql.streaming.statefulOperator.checkCorrectness.enabled enabled.
val memoryStream1 = MemoryStream[Int]
val memoryStream2 = MemoryStream[Int]
val data1 = memoryStream1.toDF.withColumn("event_time", $"value".cast(TimestampType))
.withWatermark("event_time", "0 seconds")
val data2 = memoryStream2.toDF.withColumn("event_time", $"value".cast(TimestampType))
.withWatermark("event_time", "0 seconds")
val join1 = data1.join(data2, Seq("value", "event_time"), "leftOuter")
.groupBy($"event_time").count()
memoryStream1.addData(Seq(1, 2, 3))
memoryStream2.addData(Seq(30))
val query = join1.writeStream.format("console").start()
query.processAllAvailable()
memoryStream1.addData(Seq(6))
memoryStream2.addData(Seq(6))
query.processAllAvailable()
The same code executed on Apache Spark 3.3.0 fails with the "correctness issue" exception.
How?
The fix adds 2 new watermarks to the stateful operators, the eventTimeWatermarkForEviction and eventTimeWatermarkForLateEvents. The former provides the event time for states eviction while the latter for the late events filtering. In other words, Apache Spark now clearly distinguishes between late data and Garbage Collector watermarks!
How does it work? Let's analyze the IncrementalExecution. The class holds the definition for both types of watermarks:
class IncrementalExecution(
// ...
val eventTimeWatermarkForEviction = offsetSeqMetadata.batchWatermarkMs
val eventTimeWatermarkForLateEvents =
if (sparkSession.conf.get(SQLConf.STATEFUL_OPERATOR_ALLOW_MULTIPLE)) {
prevOffsetSeqMetadata.getOrElse(offsetSeqMetadata).batchWatermarkMs
} else {
eventTimeWatermarkForEviction
}
As you can see, the GC watermark is based on the current's micro-batch watermark. The late data one uses the previous micro-batch watermark or the current one if the spark.sql.streaming.statefulOperator.allowMultiple is disabled (enabled by default).
The IncrementalExecution passes both watermarks to the stateful operations during their physical execution, like for example here with the StreamingDeduplicateExec operator:
override def apply(plan: SparkPlan): SparkPlan = plan transform {
// ...
case StreamingDeduplicateExec(keys, child, None, None, None) =>
StreamingDeduplicateExec(
keys,
child,
Some(nextStatefulOperationStateInfo),
eventTimeWatermarkForLateEvents = Some(eventTimeWatermarkForLateEvents),
eventTimeWatermarkForEviction = Some(eventTimeWatermarkForEviction))
Why splitting the single watermark into 2 separate ones helps? Let's take an example. Below you can find the code of a window-based aggregation:
val memoryStream1 = MemoryStream[Int]
val query = memoryStream1.toDF.withColumn("event_time", $"value".cast(TimestampType))
.withWatermark("event_time", "0 seconds")
.groupBy(functions.window($"event_time", "2 seconds").as("first_window"))
.count()
.groupBy(functions.window($"first_window", "5 seconds").as("second_window"))
.agg(functions.count("*"), functions.sum("count").as("sum_of_counts"))
val writeQuery = query.writeStream.format("console").option("truncate", false).start()
memoryStream1.addData(Seq(1, 2, 3))
writeQuery.processAllAvailable()
memoryStream1.addData(Seq(6))
writeQuery.processAllAvailable()
memoryStream1.addData(Seq(14))
writeQuery.processAllAvailable()
I executed it with the spark.sql.streaming.statefulOperator.allowMultiple flag enabled and disabled. Below you can find a table summarizing the actions made by Apache Spark watermark:
spark.sql.streaming.statefulOperator.allowMultiple enabled
| Input | Late data watermark | GC watermark | Output | Comment |
|---|---|---|---|---|
| 1, 2, 3 | 0 | 0 | ∅ | The first window for {0, 5} is created and persisted to the state store. |
| ∅ | 0 | 3 | ∅ | No data, state cannot be evicted (watermark lower than the end of the window). |
| 6 | 3 | 3 | ∅ | The first window for {6, 10} is created and persisted to the state store. |
| ∅ | 3 | 6 | window for {0, 5} | The first window can be emitted and removed from the state store (GC watermark). |
| 14; | 6 | 6 | ∅ | The first window for {10, 15} is created and persisted to the state store. |
| ∅ | 6 | 14 | window for {5, 10} | The second window can be emitted and removed from the state store. |
spark.sql.streaming.statefulOperator.allowMultiple disabled
| Input | Late data watermark | GC watermark | Output | Comment |
|---|---|---|---|---|
| 1, 2, 3 | 0 | 0 | ∅ | The first window for {0, 5} is created and persisted to the state store. |
| ∅ | 3 | 3 | ∅ | No data, state cannot be evicted (watermark lower than the end of the window). |
| 6 | 3 | 3 | ∅ | The first window for {6, 10} is created and persisted to the state store. |
| ∅ | 6 | 6 | window for {0, 5} | The first window can be emitted and removed from the state store (GC watermark). |
| 14; | 6 | 6 | ∅ | The first window for {10, 15} is created and persisted to the state store. |
| ∅ | 14 | 14 | ∅ | The second window is considered as late regarding the watermark and won't be returned. |
When we talk about windows. Alex also added a new function window_time to extract the event_time from each window. The function is automatically used by the window aggregation node:
== Optimized Logical Plan ==
Aggregate [window#167-T0ms], [window#167-T0ms AS second_window#16-T0ms, count(1) AS count(1)#23L, sum(count#11L) AS sum_of_counts#22L]
+- Project [named_struct(start, knownnullable(precisetimestampconversion(((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - CASE WHEN (((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) < 0) THEN (((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) + 5000000) ELSE ((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) END) - 0), LongType, TimestampType)), end, knownnullable(precisetimestampconversion((((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - CASE WHEN (((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) < 0) THEN (((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) + 5000000) ELSE ((precisetimestampconversion(window_time(first_window)#166-T0ms, TimestampType, LongType) - 0) % 5000000) END) - 0) + 5000000), LongType, TimestampType))) AS window#167-T0ms, count#11L]
+- Aggregate [window#12-T0ms], [precisetimestampconversion((precisetimestampconversion(window#12-T0ms.end, TimestampType, LongType) - 1), LongType, TimestampType) AS window_time(first_window)#166-T0ms, count(1) AS count#11L]
+- Project [named_struct(start, knownnullable(precisetimestampconversion(((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - CASE WHEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) < 0) THEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) + 2000000) ELSE ((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) END) - 0), LongType, TimestampType)), end, knownnullable(precisetimestampconversion((((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - CASE WHEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) < 0) THEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) + 2000000) ELSE ((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) END) - 0) + 2000000), LongType, TimestampType))) AS window#12-T0ms]
+- Filter isnotnull(precisetimestampconversion((precisetimestampconversion(knownnullable(precisetimestampconversion((((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - CASE WHEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) < 0) THEN (((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) + 2000000) ELSE ((precisetimestampconversion(event_time#3-T0ms, TimestampType, LongType) - 0) % 2000000) END) - 0) + 2000000), LongType, TimestampType)), TimestampType, LongType) - 1), LongType, TimestampType))
+- EventTimeWatermark event_time#3: timestamp, 0 seconds
+- Project [cast(value#1 as timestamp) AS event_time#3]
+- StreamingRelationV2 org.apache.spark.sql.execution.streaming.MemoryStreamTableProvider$@7e0f9528, memory, org.apache.spark.sql.execution.streaming.MemoryStreamTable@448cdb47, [], [value#1]
Despite these improvements, you may still encounter the correctness issue errors for the rest of unsupported operations. Below you can find the evaluation function from UnsupportedOperationChecker:
private def ifCannotBeFollowedByStatefulOperation(
p: LogicalPlan, outputMode: OutputMode): Boolean = p match {
case ExtractEquiJoinKeys(_, _, _, otherCondition, _, left, right, _) =>
left.isStreaming && right.isStreaming &&
otherCondition.isDefined && hasRangeExprAgainstEventTimeCol(otherCondition.get)
// FlatMapGroupsWithState configured with event time
case f @ FlatMapGroupsWithState(_, _, _, _, _, _, _, _, _, timeout, _, _, _, _, _, _)
if f.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
case p @ FlatMapGroupsInPandasWithState(_, _, _, _, _, timeout, _)
if p.isStreaming && timeout == GroupStateTimeout.EventTimeTimeout => true
case a: Aggregate if a.isStreaming && outputMode != InternalOutputModes.Append => true
// Since the Distinct node will be replaced to Aggregate in the optimizer rule
// [[ReplaceDistinctWithAggregate]], here we also need to check all Distinct node by
// assuming it as Aggregate.
case d @ Distinct(_: LogicalPlan) if d.isStreaming
&& outputMode != InternalOutputModes.Append => true
case _ => false
}
The check shows the room for improvement but when you compare this part with the previous release, you'll certainly notice a huge benefit for the correctness of your pipelines!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.4.0 - Structured Streaming and correctness issue here:
- Introduce window_time function to extract event time from the window column Fix late record filtering to support chaining of steteful operators
Related blog posts:
- What's new in Apache Spark 3.4.0 - shuffle changes
- What's new in Apache Spark 3.4.0 - Structured Streaming
- What's new in Apache Spark 3.4.0 - Async progress tracking for Structured Streaming
Writing this #ApacheSpark 3.4.0 blog post has taken me the most time so far ? But it helped understand the global watermark issue and the fixes reducing its impact added in the recent release ? https://t.co/RrcXrJZHTR pic.twitter.com/Iz5Rt5JNCE
— Bartosz Konieczny (@waitingforcode) May 25, 2023