
Spark Connect is probably the most expected feature in Apache Spark 3.4.0. It was announced in the Data+AI Summit 2022 keynotes and has a lot of coverage in social media right now. I'll try to add my small contribution to this by showing some implementation details.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Why?
But as usual, it's good to start with the why. Martin Grund, who is leading the project and defined its initial design, gives some reasons in the SPARK-39375:
- Stability: in shared clusters, an OOM of one user can bring the whole cluster down.
- Upgradability: dependencies in the classpath introduce some challenges, such as dependency hell.
- Developer experience: connecting your local code to the clusters has been a long-time user's demand. Although multiple plugins, there is no standardized way to do so.
- Native remote connectivity: required 3rd party tools like Apache Livy.
To be honest with you, the most exciting point from the list for me is the Developer experience. It's great to run the job from your local machine, eventually with some extra debugging information without needing to install any 3rd party plugins or to configure the IDE specifically for that. In one of his recent presentations, Martin gave a pretty convincing example of how simple Spark Connect can be:
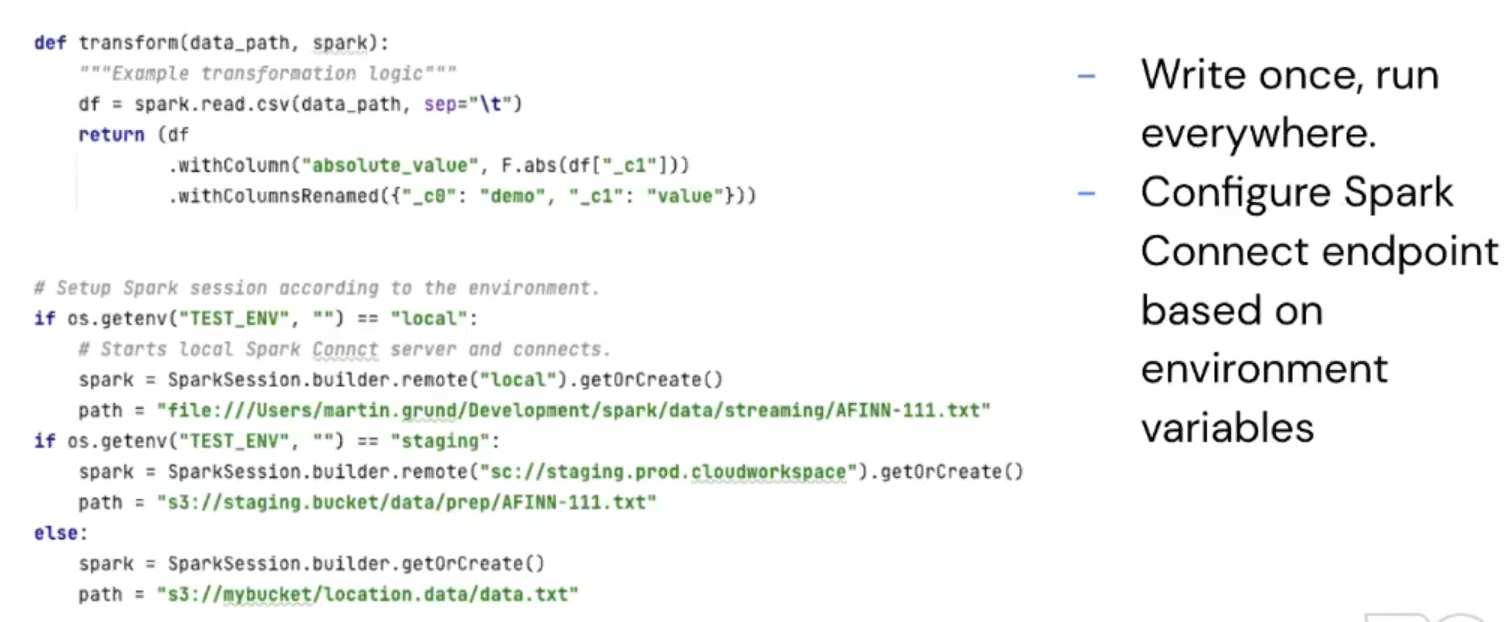
Behind this simplicity is hidden some complexity. Thankfully, you, as an end-user, won't see it that much!
Architecture - high-level
In a high-level view, Spark Connect is a client-server architecture with the gRPC-based communication:
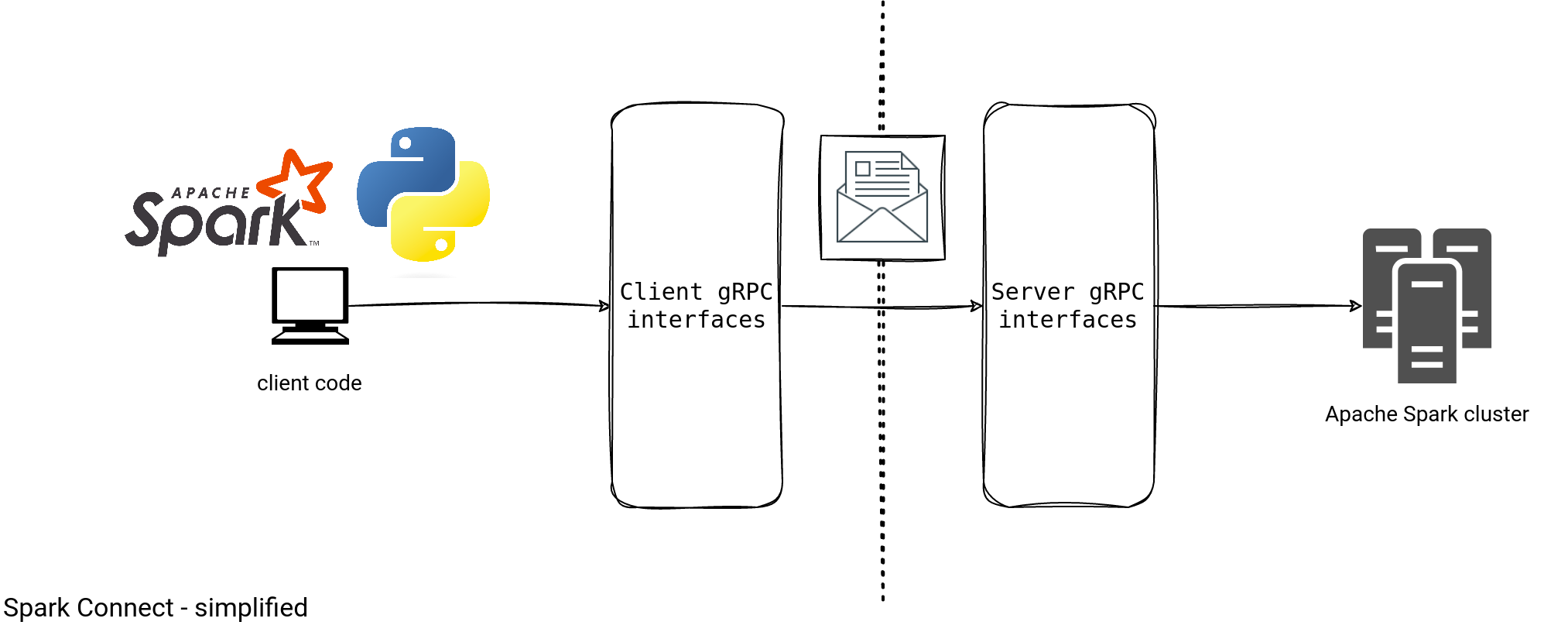
It looks simple, doesn't it? If you want to use Spark Connect, this picture should be enough. But if you want to know more, let's zoom at the schema and see some nitty-gritty details:
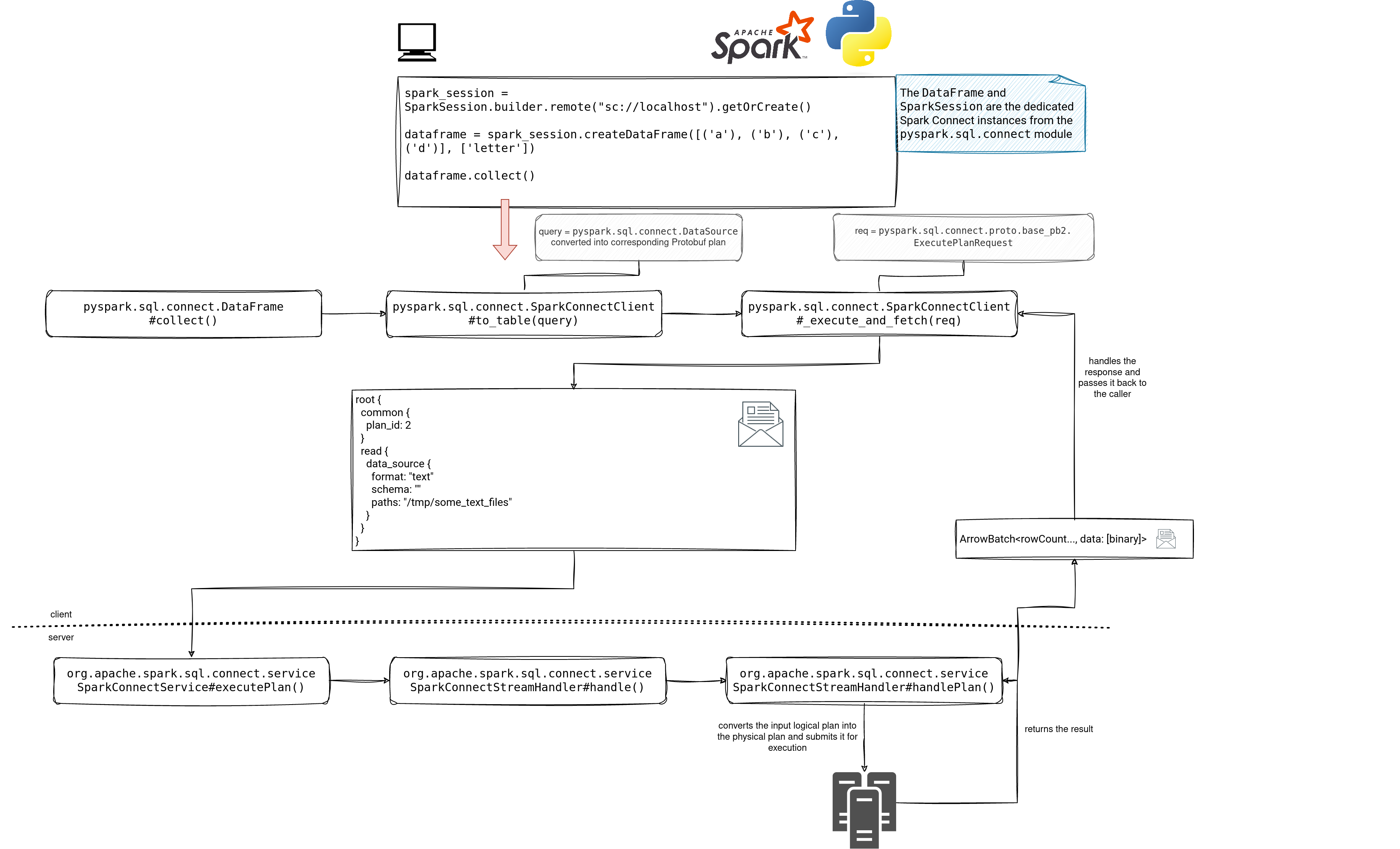
Low-level details
I must admit, the schema is complex but I couldn't remove any other steps to give the sense of the Spark Connect implementation visually. Hopefully, with the following details, you'll be able to understand the under-the-hood part a bit better!
To start, when you create a Spark Connect SparkSession, you call the SparkSession.builder.remote("...") method. Internally it resolves into a SparkSession located in the pyspark.sql.connect module. This Spark Connect-dedicated session shares the API contract with the SparkSession but provides a slightly different implementation. Instead of communicating with the Spark physical nodes directly, it does it via gRPC calls.
In our example, when we call the collect() method, in fact we do a gRPC call of execute plan type. At this point it's worth mentioning that the plan is logical and local, i.e. it has nothing to do with the Catalyst plan. It's a part of the request with the Protobuf-based payload and the Spark Connect server knows how to handle it.
The handling step happens after the initial request interception in the SparkConnectService#executePlan endpoint. After that, the handlePlan() method invokes this processAsArrowBatch function:
processAsArrowBatches(
sessionId: String,
dataframe: DataFrame,
responseObserver: StreamObserver[ExecutePlanResponse]): Unit = {
val spark = dataframe.sparkSession
// ...
SQLExecution.withNewExecutionId(dataframe.queryExecution, Some("collectArrow")) {
val rows = dataframe.queryExecution.executedPlan.execute()
val numPartitions = rows.getNumPartitions
var numSent = 0
if (numPartitions > 0) {
type Batch = (Array[Byte], Long)
val batches = rows.mapPartitionsInternal(
SparkConnectStreamHandler
.rowToArrowConverter(schema, maxRecordsPerBatch, maxBatchSize, timeZoneId))
// ...
partition.foreach { case (bytes, count) =>
val response = proto.ExecutePlanResponse.newBuilder().setSessionId(sessionId)
val batch = proto.ExecutePlanResponse.ArrowBatch
.newBuilder()
.setRowCount(count)
.setData(ByteString.copyFrom(bytes))
.build()
response.setArrowBatch(batch)
responseObserver.onNext(response.build())
numSent += 1
}
currentPartitionId += 1
}
}
As you can read from the snippet, there is another - this time the physical - SparkSession that after converting the Spark Connect logical plan into the physical representation, works directly on the data and returns it in batches, to the client.
Extensibility
On top of all of that, Spark Connect is extensible. You can implement your own extensions for Relations, Commands, and Expressions as a part of the Spark Server Libraries. All you have to do in that case is to:
- Define a plugin. It must implement one of these interfaces: CommandPlugin, ExpressionPlugin, or RelationPlugin. The plugin converts the Protobuf logical plan received from the client into its Catalyst equivalent.
- Register the command, expression, and relation plugins in, respectively, spark.connect.extensions.command.classes, spark.connect.extensions.expression.classes, and spark.connect.extensions.relation.classes configuration entries. So registered classes will be loaded by SparkConnectPluginRegistry and transformed during the Protobuf-to-Catalyst plan conversion stage, e.g. below for the relations:
private def transformRelationPlugin(extension: ProtoAny): LogicalPlan = { SparkConnectPluginRegistry.relationRegistry // Lazily traverse the collection. .view // Apply the transformation. .map(p => p.transform(extension, this)) // Find the first non-empty transformation or throw. .find(_.nonEmpty) .flatten .getOrElse(throw InvalidPlanInput("No handler found for extension")) } - Define the client part. It should be able to encode the Protobuf message used to describe the plugin on the server side.
Summary from Martin's presentation quoted previously:
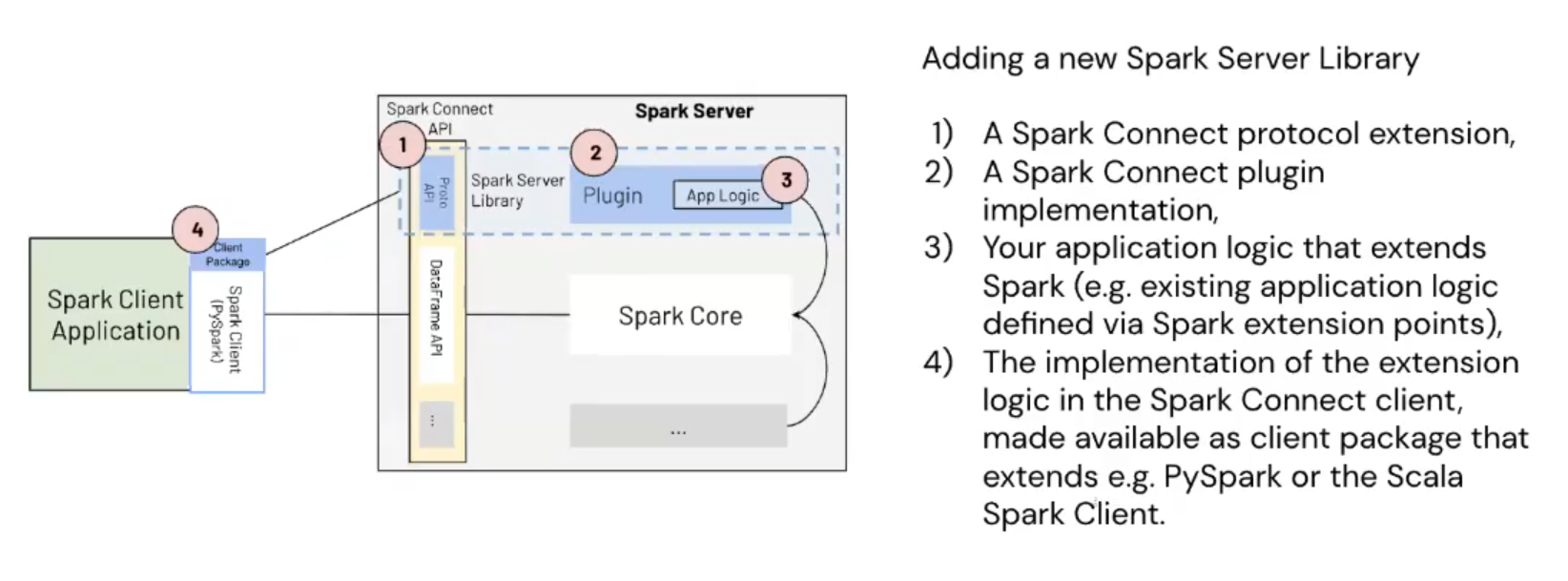
To complete the picture, another contribution from Martin's talk that shows the greatness of the Protobuf-based implementation of Spark Connect:
You can use it [plugin] on the client side in any language you want. And that's another key piece. If you build your server library, you can use it from Rust, from Go, from anywhere, as long as you know how to encode your Protobuf message in there.
https://www.linkedin.com/video/live/urn:li:ugcPost:7067167937702346754/
That's all for Spark Connect in the Apache Spark 3.4.0 context but it's only the beginning for the Apache Spark history. Recent activity in the subdirectory on Github shows the Spark Connect may become a regular position in my "What's new in Apache Spark" series!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.4.0 - Spark Connect here:
Related blog posts:
- Rolling history logs in Spark History UI
- What's new in Apache Spark 3.4.0 - shuffle changes
- Introduction to Apache Spark History
If you tell me Spark Connect, I'll think about the most expected feature in #ApacheSpark 3.4.0. Announced last year in the Data+AI Summit, it's finally there! To learn more about the high- and low-level details, you can take a look at the new blog post ? https://t.co/KwtMMdesbn
— Bartosz Konieczny (@waitingforcode) June 15, 2023