
Last time I wrote about sending Apache Kafka data to batch layer. This time I would like to do the same but with AWS technologies, namely Kinesis, Firehose and S3.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
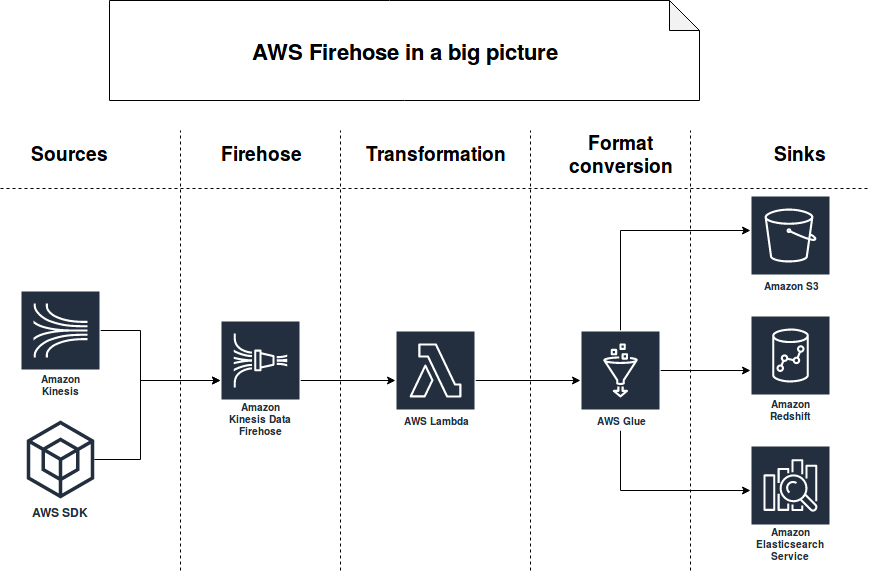
The post starts by a short presentation of Firehose service which is quite similar to the Kafka Connector's - except some subtle differences. In the next parts of the post, I will show how to use it to copy batches of data from Kinesis to S3.
Firehose 101
Shortly speaking, AWS Kinesis Firehose is the service responsible for buffering the data and writing it into other AWS services. As of this writing, the buffered data can be saved to S3, Redshift, Elasticsearch (ES) or Splunk. In this post, I will focus only on the first sink.
Exactly like Kafka Connectors, Firehose uses bufferization based on the data volume or bufferization time. That means that the records are written to the sink after accumulated size reaches a threshold or the bufferization timeout expires. Like a lot of things on the cloud, the bufferization thresholds are limited. The current limits are 5 minutes and between 100 and 128 MiB of size, depending on the sink (128 for S3, 100 for Elasticsearch service).
Firehose can, if configured, encrypt and compress the written data. It can also transform it with a Lambda function and/or write it in another format with the help of Glue service. As you can notice, Firehose covers pretty well AWS data services but using it with other sinks is much harder than using Kafka Connectors simply because it requires an important coding effort.
Firehose SDK
As I mentioned, Firehose has a possibility to define the transformation logic inside a Lambda function. To do that, the Lambda must handle com.amazonaws.services.lambda.runtime.events.KinesisFirehoseEvent event, transform the records inside it and return a sequence of triplets (record id, transformation result, transformation data). The sequence must be included in a map's key called records.
Although the SDK is not complicated, that doesn't mean that the integration is easy. One of the most common mistakes made at the beginning is the lack of newline character. If you don't specify one, the transformation Lambda will return all transformed records in a single line which may be wrong if you're using the formats like JSON Lines.
A sample transformation Lambda function can look like this:
import scala.collection.JavaConverters.collectionAsScalaIterableConverter
class NormalizationLambda extends RequestHandler[KinesisFirehoseEvent, TransformationResult] {
override def handleRequest(input: KinesisFirehoseEvent, context: Context): TransformationResult = {
val transformedRecords = input.getRecords().asScala.map(record => {
TransformedRecord(record.getRecordId, "Ok", normalizeRecord(record.getData))
})
TransformationResult(transformedRecords.toSeq)
}
def normalizeRecord(record: ByteBuffer): String = ???
}
case class TransformationResult(records: Seq[TransformedRecord])
case class TransformedRecord(recordId: String, result: String, data: String)
Custom partitioning
Firehose is an interesting service when you need to transform your data in motion into data at rest. However, it doesn't solve all use cases because Firehose uses processing time to group the events. And actually configuring a custom field, like it was the case for Kafka Connectors, this is not possible. That's the reason why you will need to make some gymnastics.
I was not talking about Lambda transformation by accident. One of advised solutions uses the transformation Lambda to dispatch grouped data to appropriate partition. The following schema illustrates that:
Obviously, it will work quite well only if your data source (Kinesis stream in my case) generates homogeneous data from the partitioning point of view. For instance, if you take the partitioning by event time and you're sure that 90% of your input data processed by Firehose will concern one partition, this solution may be a good fit. On the other side, if your input is more heterogeneous, there is a big risk that you will end up with a lot of small files. Probably these files won't be as small as they could be if you wouldn't use Firehose, but still, it may have a negative impact on your batch layer.
The second solution uses one Firehose stream per partition. Therefore, instead of using a staging bucket and a transformation Lambda, you can directly write the data to your target place (of course, if it's a sink supported by Firehose). To do all of this properly, you will need to create Firehose streams in advance. For instance, every day you can create 24 streams for the next day's hours. As you can see, it adds some operational effort and also brings a question about late data. By default, you can only have 50 Firehose streams in your AWS account. So you can't keep hourly streams indefinitely. One of the solutions to handle the problem of very late data could be the use of a separate Firehose stream for the case when hourly stream doesn't exist. After you can add a transformation Lambda and add the data to correct partition:
And finally you can also use Firehose to write data partitioned by processing time and do the partitioning in batch:
Firehose by itself couples you to AWS service and it's understandable. If you can pay that price for your architecture, with a little bit of extra effort, you can use Firehose to create micro-batches and write them into one of the available sinks. On the other side, if you're using some of not implemented sinks, you will, of course, get rid of operational cost through AWS infrastructure, but you will still need to implement what you want. It's not the case of Kafka connectors which go outside of the scope of some specific storage or cloud provider.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about AWS Kinesis Firehose, event time and batch layer here:
- Firehose to S3 - Custom Partitioning Pattern How to build an Event Pipeline Part 2: Transforming records using Lambda Functions Amazon Kinesis Data Firehose Data Transformation
Related blog posts:
- Don't sleep when you code...about sleep issue in KPL
- Kinesis sequence number is not an Apache Kafka offset
- Amazon Kinesis is not Apache Kafka
In another post of this week I covered 3 approaches to deal with event time partitioning in #AWS Kinesis Firehose service: https://t.co/hW8NFgZWeG
— Bartosz Konieczny (@waitingforcode) May 29, 2019