
Despite the recent critics (cf. "Serverless Computing: One Step Forward, Two Steps Back" link in the Read also section), serverless movement gains the popularity. Databricks proposes a serverless platform for running Apache Spark workflows, Google Cloud Platform comes with a similar service reserved to Dataflow pipelines and Amazon Web Services, ... In this post, I will summarize the good and bad sides of my recent experiences with AWS Lambda applied to the data processing.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I divided the post into multiple short sections. Each of them covers one specific point that is important from the data processing framework's point of view. The first part, however, will introduce you to the AWS Lambda functions and therefore, explain some basic points about them.
AWS Lambda basics
AWS Lambda is a code executed on a distributed environment. The execution has some constraints like the timeout and the available memory which in its turn impacts the allocated CPU. Both constraints define the overall price for each execution. To sum up, we can say that an AWS Lambda function is a piece of code executed remotely during some amount of time, using some amount of resources which together define the cost of the execution.
The function is pretty well integrated with AWS ecosystem. It's executed either by one of the available events, like Kinesis, S3, DynamoDB streams and so forth. We can also schedule it at a regular interval, a little bit like a CRON job. AWS Lambda also integrates well with modern deployment frameworks like Serverless Framework.
That's all to know before going into the details concerning the data processing.
Horizontal scalability
The horizontal scalability depends on the trigger. If the trigger is a Kinesis stream, then you will have as many functions as the number of shards. If you assign the S3 trigger, the Lambda will be invoked every time the file is touched. Hence, you can scale it pretty easily simply by resharding the stream or adding capacity to DynamoDB streams.
The scalability may be controlled too. If you think that the downstream data sources aren't sized to handle the scaled load, you can limit the number of concurrent invocations with reserved concurrent executions option.
The downside of the scaling part is that you can scale easily only with AWS services but after all, it's quite logical.
Regarding a data processing framework like Apache Spark, the principle of horizontal scalability is the same. Apache Spark also uses the partitions to distribute the load. However, it was not always correctly adapted to AWS services. The Kinesis receiver does not snapshot when shard completes bug is the proof. Also, at the time of writing, Structured Streaming which is one of the major Apache Spark components, still lacks of the support to AWS Kinesis.
Automatic retry
The automatic retry is useful when a task can't complete because of some temporary issues like an unavailable enrichment API. In such a case you will always want to retry to enrich the raw data instead of giving up and failing the whole processing. AWS Lambda handles the retries quite well for the stream-based triggers.
The things complicate for not streamable data sources like S3. In such a case, if the function doesn't succeed to process the event, it doesn't have the second chance (actually, it has 2 other attempts but it still may not be enough in certain temporary failures). But you can still use an intermediary streamable buffer between the processing code and the event to improve the fault-tolerance:
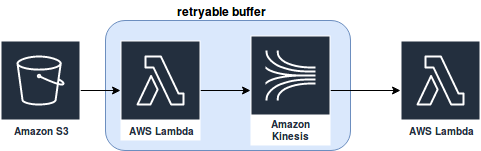
Classical data processing frameworks don't have the concept of streamable or not streamable data source. Instead, they reason about "tasks" that can be retried any number of times. Usually, the user configures the desired number of retries.
Local state
You should design AWS Lambda functions in the stateless spirit. Every time the function starts, AWS creates its execution context that may be reused between subsequent invocations. However, it's not the guarantee and the provider can decide to reconfigure this environment. You can read about this in the documentation:
"When you write your Lambda function code, do not assume that AWS Lambda automatically reuses the execution context for subsequent function invocations. Other factors may dictate a need for AWS Lambda to create a new execution context, which can lead to unexpected results, such as database connection failures."
Therefore, having an in-memory cache to accelerate some operations or buffering some data in the local disk before writing it elsewhere in batch mode will be hard. To handle that, you should use an external data store. For instance, a key-value database can be used to keep the state-based key like sessions. A distributed file system can be used to create a persistent data buffer. But both involve network communication and much more programming effort than in the case of traditional data processing where the local state can be kept simply in memory and from time to time backed up into some persistent storage for better fault-tolerance.
Costs
There is nothing worse than a persistent cluster used, let's say, 12 hours a day. From one side, you cannot use a transient cluster because of the initialization time but from another, you would like to do so in order to save some money. AWS Lambda is an interesting alternative for that. For instance, if you're expecting to process the data during an hour, 12 twice a time, your price will begin with $0.000000208 and go up to $0.000004897 per 100ms of the execution.
But on the other side, if you think to process a big volume of streaming data, maybe you should reconsider using Lambdas. Let's take the execution price for 2432MB of memory which is $0.000003959 per 100ms. If we suppose that our processing takes 3 minutes (180000ms), we'll pay $0.0071262 for every call (180000/100 * 0.000003959). It's still not a lot but if we multiply this by 50 invocations per minute, we'll end up with a cost of $0.35631 which gives $513.0864 per day. For that price, you can probably afford to use a good EMR cluster.
Of course, that was only an estimation but you should keep this in mind when you're considering the use of AWS Lambda as the data processing layer, especially for the high load streaming pipelines.
Data problems
Thus, the lack of local state support complicates the use of the functions as a universal data processing tool. The functions will fit pretty good in stateless workloads, like for instance a filter-map pipeline, but won't be easy to use in the stateful ones, for instance, to solve the sessionization problems.
Nonetheless, that doesn't mean that it's impossible to solve stateful problems with AWS Lambda. It's feasible if you use another service to persist the state, as for instance DynamoDB. Unfortunately, it will have a negative impact on the costs since we'll accumulate the processing and the storage costs:
The traditional data processing frameworks deal with the state locally, in memory. Therefore, you could use the resources for which you have paid and, in consequence, have a stronger guarantee that they won't suddenly disappear.
Complexity vs isolation
The use of AWS Lambda in the context of data processing depends on the teams but often it won't stop with a single function. One of the practices is the use of one function for each data processing step. Therefore, even for a simple filter-aggregate use case, you can end up with one function for filtering and another one for the grouping.
This approach privileges the Single Responsibility Principle because it's isolated. However, it makes the overall architecture more complex. And it's only for a simple filter-aggregate task. You can imagine what happens for a longer task that would require to buffer some data and do something with it after some specified time.
But on the other side this complexity isolates the processes and improves their fault-tolerance. Let's add an output Lambda to our filter-aggregate pipeline. In the case of a failure of this last stage, with the traditional job-based approach (I suppose you read the data from the topic and later make filering and aggregating in the same app), you should regenerate all the data, starting from the data source reading. With Lambda-based pipeline,mainly because of its stateless constraint, most of the time you will use one intermediary storage between the 2 operations and therefore isolate them better. In the case of the aggregation failure, you can continue to filter the data and restart only the output part when it will be fixed:
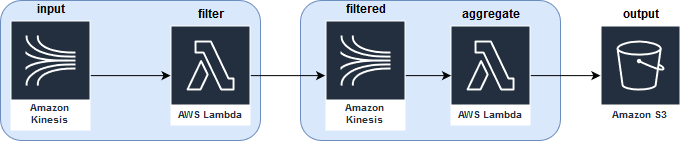
To sum-up, AWS Lambda can be considered as AWS serverless data processing alternative to the Databricks Apache Spark and GCP Dataflow services. However, sometimes it will require some extra work to provide the missing properties of data processing frameworks like state management. All of that can have a bad impact on the price and the architecture complexity. But on the other side, this complexity can bring better isolation of the steps and, therefore, increase fault-tolerance.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about AWS Lambda - does it fit in with data processing ? here:
- Managing Concurrency AWS Lambda Execution Context Kinesis support in Structured Streaming Serverless Computing: One Step Forward, Two Steps Back
Related blog posts:
- Don't sleep when you code...about sleep issue in KPL
- Kinesis sequence number is not an Apache Kafka offset
- Amazon Kinesis is not Apache Kafka
Does #AWS Lambda service can be considered as a serverless #data processing framework ? In today's post I explain the good and bad sides of the solution ⇒ https://t.co/iMQUtqrzvw
— Bartosz Konieczny (@waitingforcode) March 6, 2019