
Is it possible to implement the MapReduce paradigm on top of cloud serverless functions? Technically yes and there are some reference architectures I'm gonna discuss in this blog post. Is it a good idea? It depends on the context and hopefully you'll be able to figure out the answer after reading my thoughts.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the blog post I'm considering 2 serverless MapReduce sources, the A framework and a performance assessment for serverless MapReduce on AWS Lambda and Ad Hoc Big Data Processing Made Simple with Serverless MapReduce. In the article I'll call them respectively, MARLA project and AWS architecture. Despite some differences, both solutions implement the pattern with similar components which you can easily identify in the schema just below:

Of course, both designs have some subtle differences, but to not overcomplicate the schema, I'll explain them in the next sections.
Triggering
To start, let's answer the question, how to start the job? There are 2 different ways presented in the quoted articles. MARLA project triggers the job when a new object is written to the input bucket. When it happens, a coordinator Lambda function gets invoked with the object information and prepares the number of mapper tasks, and starts the workload. This preparation step looks similar to how Apache Spark plans files processing. The function divides the object size into one or multiple chunks that the mapper functions will process in parallel.
The AWS architecture trigger starts the job from a configuration file describing the runtime environment, input dataset, mappers, and reducers. The data division logic is implemented in a driver program that triggers the corresponding number of mapper functions.
Mappers
Mappers are the functions responsible for the initial processing of the input data. Both solutions implement them as concurrently invoked Lambda functions working on separate chunks of the input data. As you can see from the triggering part, mappers don't share the same role in both solutions. AWS architecture limits their responsibility to processing data and writing reduce objects.
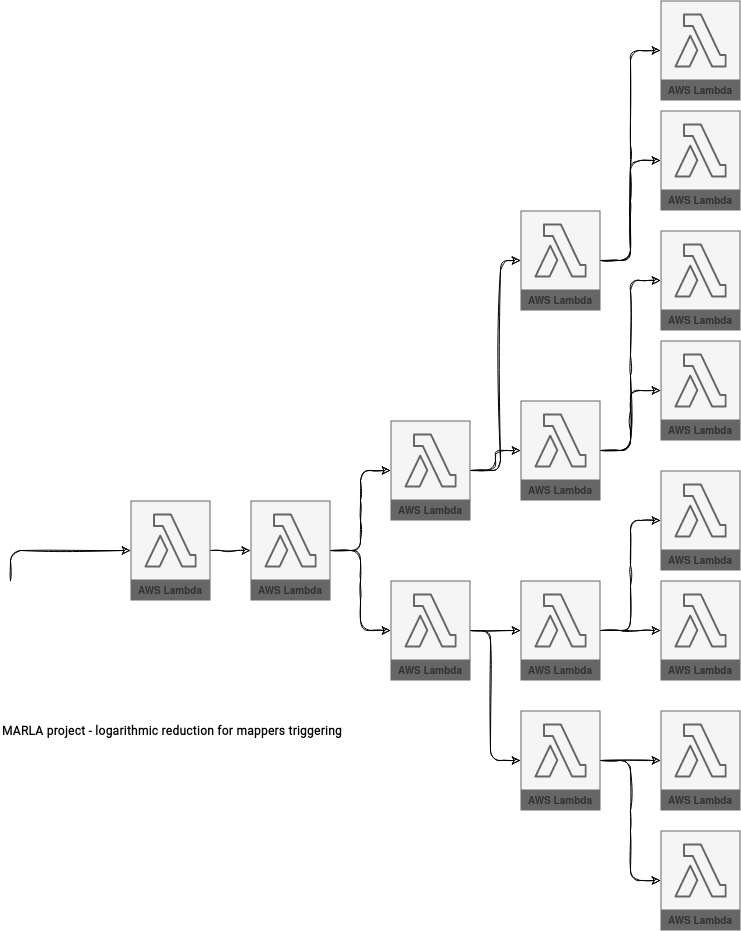
On the other hand, the MARLA project gives them the triggering responsibility. The first triggered mapper receives all chunk sizes and invokes the second mapper function. Later, they start 2 other functions, and so forth. The authors of the solution call this a logarithmic reduction and it's intended to reduce the functions invocation delays.
Reducers
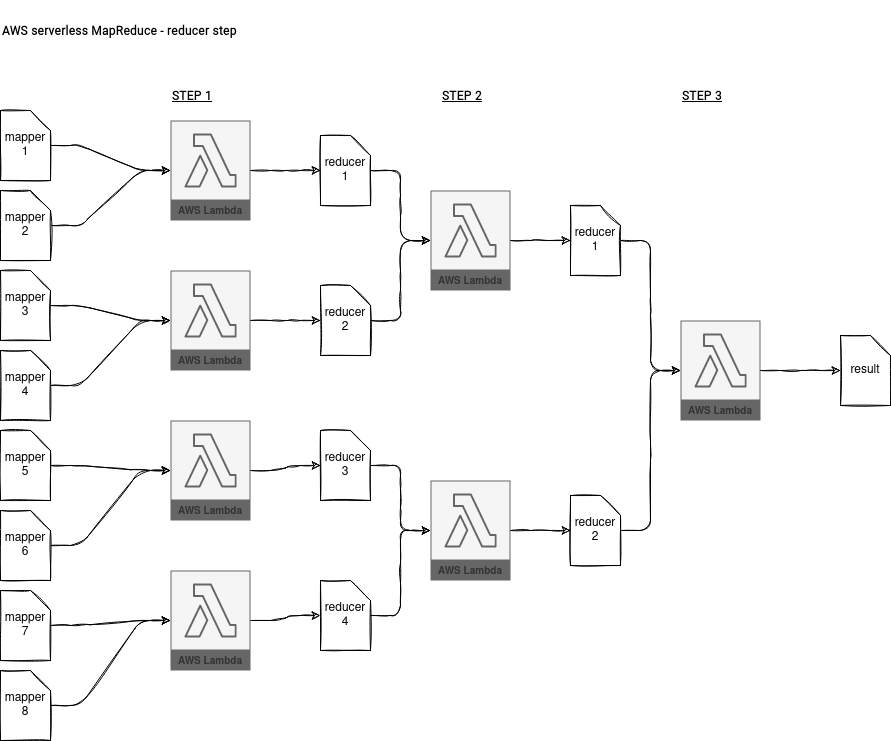
The reduce stage in the AWS architecture relies on a coordinator function that triggers whenever a new object is written to the bucket by the mappers. Every time it compares the number of files generated in the mapper stage with the number of scheduled mapper tasks. If they're different, the coordinator simply terminates. If not, it triggers the reducer functions by dividing the mappers' output by the targeted number of reducers. After the first look I didn't find any logic implemented for by key operations but it was wrong. The reduce is an iterative step. It first works on the mapper files and generates the first version of the reducer files. Each reducer function takes at least 2 mapper files:
def get_reducer_batch_size(keys):
#TODO: Paramertize memory size
batch_size = lambdautils.compute_batch_size(keys, 1536, 1000)
return max(batch_size, 2) # At least 2 in a batch - Condition for termination
So it'll generate 2x less files. In the next step, it'll run again, but this time on the files generated by the previous reducer, and it'll continue that until processing 2 reducer files. In consequence, it'll produce the final result file with all aggregations in this last step.
def compute_batch_size(keys, lambda_memory, concurrent_lambdas):
max_mem_for_data = 0.6 * lambda_memory * 1000 * 1000;
size = 0.0
for key in keys:
if isinstance(key, dict):
size += key['Size']
else:
size += key.size
avg_object_size = size/len(keys)
print "Dataset size: %s, nKeys: %s, avg: %s" %(size, len(keys), avg_object_size)
if avg_object_size < max_mem_for_data and len(keys) < concurrent_lambdas:
b_size = 1
else:
b_size = int(round(max_mem_for_data/avg_object_size))
return b_size
Where the keys are all the input objects to process, lambda_memory is the memory allocated to a lambda function, whereas concurrent_lambdas is the number of functions that can be running simultaneously. The first attribute is resolved at runtime by the driver whereas 2 latter ones come from the configuration properties.
MARLA project doesn't have this iterative character because its mapper step generates key/value pairs that are later reduced in a single reducer function. The mappers generate the intermediary objects with the following hashed prefix:
ASCIIinterval = (130-32)/NREDUCERS
ASCIIlimit = ASCIIinterval+32
ASCIInumInterval = 0 # Actual interval
partialKey = PREFIX + "/" + FileName + "/"
# Upload results
resultsKey = partialKey + str(ASCIInumInterval) + "_" + str(NodeNumber)
# Add a prefix with his hash to maximize
# S3 pefrormance.
resultsKey = str(hashlib.md5(resultsKey.encode()).hexdigest()) + "/" + resultsKey
The partialKey is a static representation of the processing bucket. The ASCIInumInterval is a number incremented at every new written result group. It's Apache Spark's shuffle partition number. The final NodeNumber is the number of the mapper generating this file. The reducers use this naming pattern to get the corresponding related files to process together:
def downloadPairs(filesSize,usedMemory, maxUsedMemory, actualPartition, TotalNodes, BUCKETOUT, PREFIX, FileName, ReducerNumber, s3_client):
chunk = ""
init = actualPartition
for j in range(init, TotalNodes):
#download partition file
bucket = BUCKETOUT
key = PREFIX + "/" + FileName + "/" + str(ReducerNumber) + "_" + str(j)
The "serverless map-reduce" topic has been on my backlog for almost a year and I'm very happy I finally could work on it. IMHO, it's still a limited alternative to Apache Spark or Apache Flink frameworks lacking some connectivity (only S3 supported), monitoring (custom), and streaming (batch example given, seems to be hard to implement for an unbounded data source).
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Serverless MapReduce? here:
- A framework and a performance assessment for serverless MapReduce on AWS Lambda Ad Hoc Big Data Processing Made Simple with Serverless MapReduce
Related blog posts:
- Don't sleep when you code...about sleep issue in KPL
- Kinesis sequence number is not an Apache Kafka offset
- Amazon Kinesis is not Apache Kafka
Is serverless compatible with the MapReduce programming model? Some effort has been made to prove that. Although it doesn't seem to replace data processing frameworks (yet?), you can read a short analysis of it today ? https://t.co/4OThDvzKpM
— Bartosz Konieczny (@waitingforcode) January 16, 2022