
Having data close to the computation has a lot of advantages. This idea called data locality is not new since it was popularized with Hadoop MapReduce. Despite of that, it's worth recalling some of its main points and trying to adapt it to modern data pipelines most of the time based on cloud services.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post is divided in 2 parts devoted to data locality concept. The first one describes it in a big picture and gives some use case examples. The second section explains through several examples, how the data locality can be thought in the context of modern, cloud-based data processing pipelines.
Data locality
The idea of data locality gained its popularity with Hadoop MapReduce and its HDFS storage system. In this context it consists on bringing computation process as close to the processed data as possible. It means that JobTracker allocates computation jobs to the nodes physically storing the processed data. This strategy is called local data locality. If the node with given data is overloaded, JobTracker tries to allocate the job inside the rack of data node (intra-rack data locality). If it's not possible, the strategy called inter-rack data locality is applied where the job is allocated in different rack.
If you carefully read previous paragraph you've certainly noticed one important thing - data and computation are stored on the same physical node. However often, especially nowadays with the use of storage services provided by different cloud providers (AWS's S3, GCP's GCS), it's not possible to allocate processing code on the same node. Does it mean that data locality is "has been" ? Not really. The difference is that it can be thought more in terms of data partitioning, since we aren't able to really put the computation code to the node storing the data.
Data processing locality nowadays
An advantage that data locality brings to the processing pipelines today is predictability. For instance, let's imagine a pipeline from the following picture where x AWS Lambda functions (x = number of Kinesis shards) update the information about users:
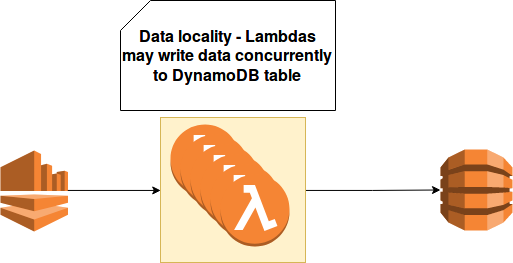
Each user is identified by an unique number and it can produce one or more events to process. If these events are unbalanced, i.e. the events belonging to one user are located on different shards, the logic responsible for writing to DynamoDB will be complicated. We'll need to deal with concurrent changes that it's not an easy task in distributed environments. However, if the information is correctly balanced, i.e. all events for a user are stored in one common shard, the concurrency issue goes away. The only one remaining aspect is unordered events. But since we know that the events are processed "locally", always by consumer reading the same shard, handling it is much easier.
Another interesting point of data locality is the optimization of resources use. Let's take similar example to the previous one. The difference is the use of Apache Spark instead of AWS Lambdas for processing and Apache Kafka instead of Kinesis for streaming:
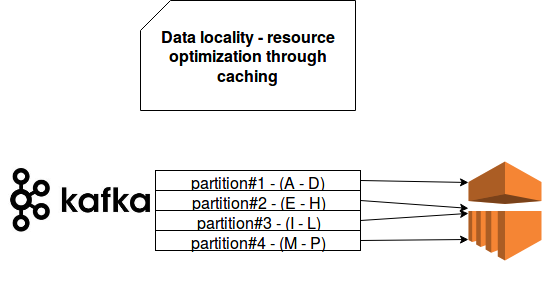
As you can see, our data is partitioned by different keys. In our imaginary context it means that, depending on the key, records are enriched differently. With an approach like that we can use cache feature pretty efficiently. Since the data will be read per partition by the executors, keeping consistent and efficient cache in memory is easy. With the data balanced randomly keeping an efficient cache would be difficult because we wouldn't have any guarantee that cached enrichment data will be used again. After all a random partitioning strategy can but the data of the same "key" into many different partitions.
The third important advantage of data processing locality is reduction of data movement across the network. Since the data is loaded directly into adequate parallelization unit, it's not required anymore to transfer it between nodes. And this, in the case of pipelines dealing with a lot of events, is pretty significant.
Initially thinking about data locality was simple. After all it tried to locate the processing code as close to the processed data as possible. However nowadays it's not so simple to put both of them in the same node. Hence, the concept of data locality can be rethought in terms of data processing locality. But we should keep in mind that poor partitioning key will lead to skewed partition and stragglers that will probably slow down the whole processing pipeline.
This "modernized" concept relies more on logical data partitioning and is more about bringing related data to the same computation process. Please notice that it's only a personal proposal to describe data locality concept in the cloud. If you've another idea, please share them in the tweet below the post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data processing locality and cloud-based data processing here:
Related blog posts:
Today on waitingforcode a proposal of reviewed data locality concept for cloud-based data processing pipelines https://t.co/1V5extvQiw
— bardev (@waitingforcode) September 9, 2018