
After introducing DataOps concepts, it's a good time to share my feelings on them ?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The goal of this post is twofold. First, I wanted to share what I liked and didn't like in the DataOps concept. Second, by sharing my personal opinion, I wanted to encourage you to share yours in the comments, hoping that it can help us get a better pragmatic understanding of the DataOps approach.
I like the concept...
I really liked the fact that DataOps puts a strong accent on data quality. Everybody knows that poor data quality means poor data insight and complex pipelines that try to get something interesting from there. Unfortunately, it's often a constant which is hard to improve. DataOps points out this danger and gives some guidelines on how to overcome and control data quality better thanks to the tests (code + pipeline) and monitoring layer.
Moreover, I appreciated the mentions of hope and heroism. IMO, it highlights the fact that working hard is easier than working smarter, but not necessarily better for the company and your private life. To see that, let's compare manual and automated tests. Manual tests are human-driven, and they tend to run less frequently. Whoever says "less frequently" and "human" also says an increased risk of bugs and less predictable delivery. After all, these tests will be executed rarely, probably at the end of the development cycle, and the eventually detected bugs can postpone the project release. On the other hand, automated, machine-driven tests don't have this limitation, and you can use them to discover the issues even after the first day of development! And that's just one of many examples of smart working vs. hard working, embracing fearless development.
Knowing that "smarter work" thing, it's easier to understand the importance of automation in the concept. Once again, manual deployments are much more error-prone than automated and parameterizable pipelines. Also, these manual operations lose time and "close" the competence since there will be a small bunch of people able to do them. It doesn't happen when you have a standard CI/CD pipeline to deploy a new version. You can even extend this idea and use it to perform some maintenance tasks. A great example of that is Apache Airflow's UI that provides a native way to reprocess your batch jobs in a few clicks! You can still do it differently with CLI by accessing the worker node, but that's a manual and more error-prone operation that it's better to avoid.
...but I'm not fully agree with it
But I'm not fully agree with all the presented concepts. The thing that caught my attention is the table from the page 104 describing the separation of roles in a DataOps team:
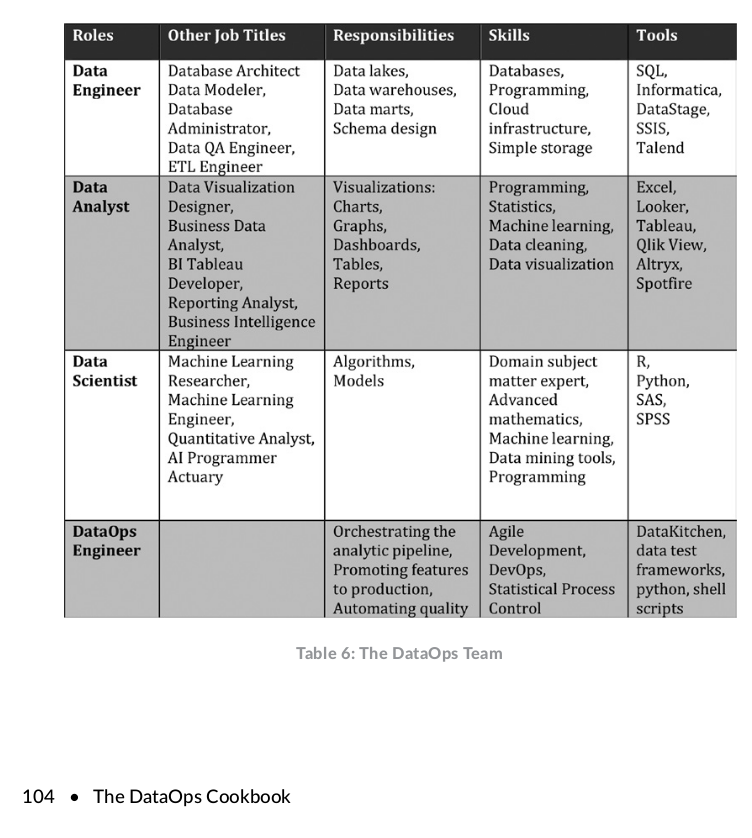
I have a feeling - maybe wrongly - that the data engineering role was reduced to data transformation. In my perception of a data engineering role, we shouldn't be limited to writing the SQL, Scala, or Python transformation code. We should be aware of how to orchestrate the code, so not only write "the Spark job" but also "put it on Airflow", maintain it at a daily basis, and "create the necessary infrastructure to run it" (a lot of us work with cloud and different computation paradigm than static on-premise clusters).
Also, "promoting features to production" is debatable. IMO, it can introduce a long feedback loop where a data engineer is unable to understand the deployment part. The capacity to understand and propose the deployment plan should also be a part of the data engineers' skillset. Of course, under the validation or with close collaboration with a DevOps.
Besides, knowing the production environment should help a data engineer write more maintainable pipelines. If you worked on the cloud with ops people, you undoubtedly noticed the importance of naming conventions to variabilize things. Or, if not, you are surely aware of how to query your infrastructure definition layer to get the information on the location or an id of a component you will want to work with. Why is it important? Let's imagine that we want to use a sensor in Apache Airflow and wait for some S3 data to be available for processing. How to do that? The first option, use Airflow variables and put the information from your bucket's deployment process. The second, and in my opinion, much more comfortable option, use naming conventions and, for example, prefix the bucket with the environment code (prod, dev, ...). So that everything you have to store in Airflow is the environment code.
For me, the "Automating quality" part also is in the wrong place. I can't imagine myself not writing unit or integration tests. Maybe because I came to the data world from software engineering where these 2 aspects were present every day, and it's not so evident for historical data departments like BI? I can't answer that, but anyway, this testing and "promote to production" points look like the separation between "developers" and "release engineers" from the pre-DevOps era, where ones write the code and the others do the rest (deployment, tests automation, ...). It's also possible that I had a completely different data engineering experience where I was involved in all development, CI/CD, IaC, testing, and production release stages, and that's why I couldn't understand this "data engineer" and "DataOps engineer" separation?
To summarize, some of the DataOps Manifesto points should still be in the scope of a data engineer's responsibilities. But despite this small difference of points of view, I firmly believe that formalizing the main data engineering pain points and proposing a solution will be beneficial for all of us. And if you have any input to confirm or contradict what I understood - maybe wrongly - feel free to leave a comment. I will be happy to discuss and learn more about DataOps!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
DataOps, did I get it right ? Today I published a follow-up post about this approach and shared my points of confusion ? https://t.co/dEfiMnlIcK
— Bartosz Konieczny (@waitingforcode) March 7, 2021