
Apache Spark is a special library for me because it helped me a lot at the beginning of my data engineering adventure to learn Scala and data-oriented concept. This "learn-from-existent-lib" approach helped me also to discover some tips & tricks about reading others code. Even though I used them mostly to discover Apache Spark, I believe that they are applicable to other JVM-based projects and will help you at least a little bit to understand other Open Source frameworks.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is divided into 4 sections. Each of them shows either a Scala or an IntelliJ feature that should help you to discover any Open Source project internals.
Packages visibility
I used this trick recently when I wanted to discover what is stored in state store files. Unfortunately, HDFSBackedStateStoreProvider was package private and the only way to use it was to simply create a package under org.apache.spark.sql.execution.streaming.state and define the code to decompress the state:
val provider = new HDFSBackedStateStoreProvider()
provider.init(
StateStoreId(
checkpointRootLocation = "file:///home/bartosz/workspace/spark-scala/src/test/resources/checkpoint-to-read-with-state-removal/state",
operatorId = 0L, partitionId = 0,
storeName = "default"
),
keySchema = StructType(Seq(StructField("value", LongType, false))),
valueSchema = StructType(Seq(
StructField("groupState", StructType(Seq(StructField("value", StringType, true))), true),
StructField("timeoutTimestamp", LongType, false)
)),
None,
storeConf = StateStoreConf(sparkConfig),
hadoopConf = new Configuration(true)
)
provider.getStore(2).iterator()
.foreach(rowPair => {
val key = rowPair.key.getLong(0)
val value = rowPair.value.getString(0)
val timeout = rowPair.value.getLong(1)
println(s"${key}=${value} expires at ${timeout}")
})
That's true for other Spark components. Recently I was also preparing a talk for Paris Spark Meetup about Apache Spark customization. One of the examples I gave was about User Defined Types that can be created only under org.apache.spark.sql.types package. And I played with packages visibility to make the example work.
AOP
When I was working with Spring ecosystem, few times I used an Aspect Oriented Programming. The idea is to wrap the execution of different methods with some custom code able to access input parameters or output results. I also used it with Apache Spark Structured Streaming. It helped me to see what items are added or removed from the state store.
To put an AOP in place, you must choose the library, add some parameters and write the decoration code. Below you can find an example with AspectJ:
org.aspectj
aspectjweaver
1.7.2
org.aspectj
aspectjrt
1.7.2
The decoration class must be annotated with @Aspect. It also has to contain interception methods annotated for instance with @Before (other lifecycle annotations exists):
@Aspect
class StateAspect {
@Before(value = "execution (* org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider.HDFSBackedStateStore.put(..))")
def interceptStatePut(joinpoint: JoinPoint): Unit = {
StateStoreKeysHandler.addId(joinpoint.getArgs.toSeq(0).asInstanceOf[UnsafeRow].getLong(0))
joinpoint.getTarget
}
}
object StateStoreKeysHandler {
private var allIds = Seq.empty[Long]
def addId(id: Long) = {
allIds = allIds :+ id
}
def getIds = allIds
}
To see it working, you must execute your code with the follwing JVM parameter -javaagent:~/.m2/repository/org/aspectj/aspectjweaver/1.7.2/aspectjweaver-1.7.2.jar.
The good thing here is that the aspects execute without stopping the real execution, so you can log everything you want and analyze the results at the end. On the other hand, you have to bring an extra dependency and launch your code in a specific manner. If it seems to complicated, you can check next 2 points that should provide a serious alternative with debugging.
Breakpoints debug
I will switch now to the 2 tips related to IntelliJ. The first one uses breakpoints and debug execution. Adding breakpoints is quite easy. You simply click on the space between the line number and the code editor:
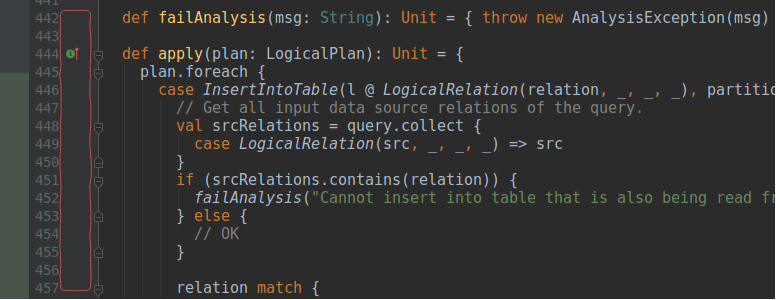
Later you simply run your program in debug mode:
A nice thing here is that you can simply track the calling sequence and observe how some parameters are computed:
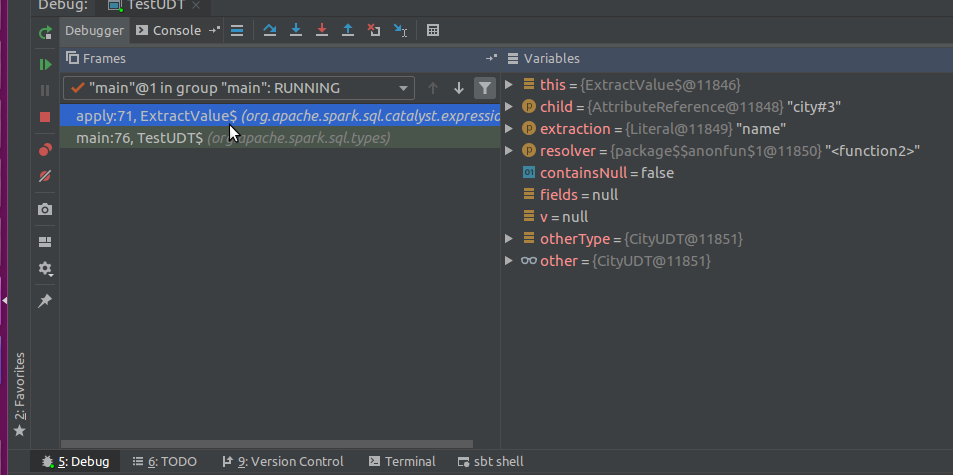
The drawback of this approach is that every time you want to investigate, you have to stop the program's execution. This is why debugging a program processing a lot of data can be painful. To reduce the pain you can use a conditional debugging and define a stop condition on the breakpoint after right-clicking on it:
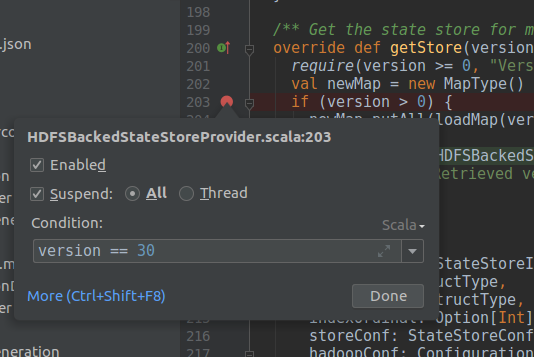
Another useful debugging option to know configures the stop condition. In the above screenshot, you can see that All is checked. It means that when the breakpoint is hit, all threads will stop. Otherwise, only the thread of the hit breakpoint would be stopped. It's important in the context of multi-threading applications (Apache Spark in local mode is one of them) because without "All" suspension, you will probably miss the debugging from other threads.
Log and evaluate
Another debugging technique that doesn't block the code execution uses "Evaluate and log" debugging mode. You can enable it only when the "Suspend" checkbox is disabled, so as you can deduce, the program's execution won't stop during the debugging:
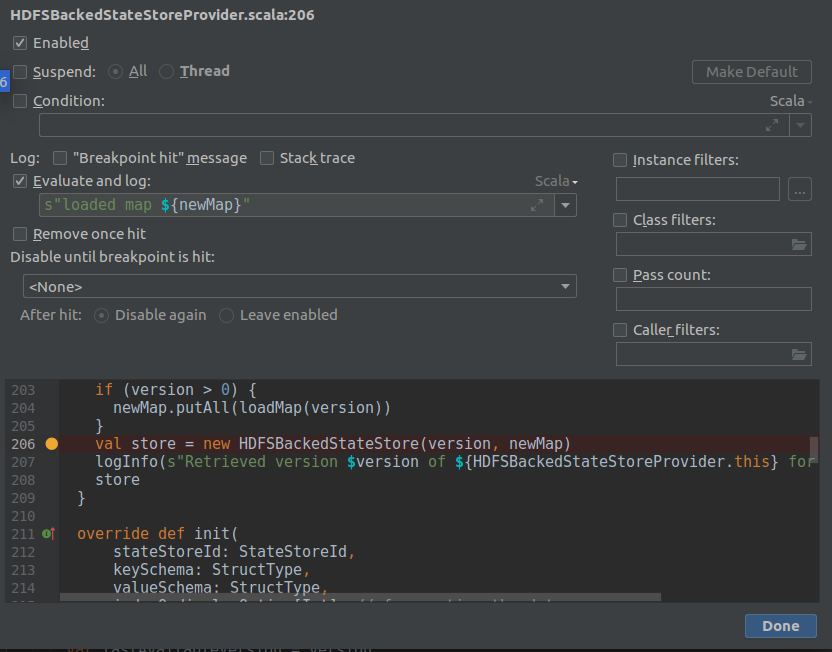
The code will behave very similarly to AOP-annotated code. The differences are that you don't need to add any extra dependency and that you can investigate any line of the method, not only the input or output:
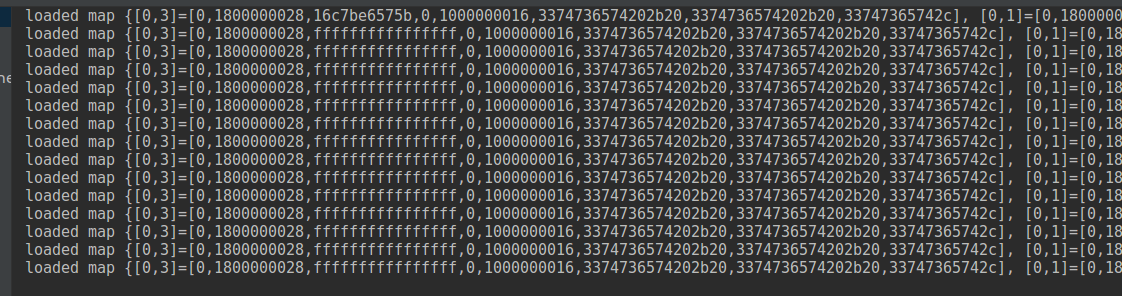
If you want to learn a new library or understand any other Open Source project, it's always interesting to deep dive into the internals. They will not only help you to see how the project is organized but they will likely show you some new coding techniques. By using some of the tips proposed in this post, you should be able to accelerate your learning curve and, who knows, maybe share your learning with the community?
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Trunk-based development and data engineering
- DAMP, aka Descriptive And Meaningful Phrases
- Let it crash model
Curious about things I use to analyze Open Source frameworks? I shared some of them in today's post https://t.co/eIPSOOnAMB
— Bartosz Konieczny (@waitingforcode) September 22, 2019