
If you know it, lucky you. If not, I bet you'll spend some time on getting the reason why two - apparently the same rows - don't match in your full outer join statement.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
After all these years, I found an easy way to test regressions in jobs as long as the query layer supporting SQL is available. I shortly blogged about that in Regression tests with Apache Spark SQL joins so I'll omit that part. Instead, I'll focus on one subtlety that after 5 years has seized me again! Joining the null columns.
To understand the issue, let's create an in-memory DataFrame with PySpark:
letters_1 = spark.createDataFrame([{'id': 1, 'letter': 'a'}, {'id': None, 'letter': 'b'}, {'id': 3, 'letter': 'c'}],
'id INT, letter STRING')
letters_2 = spark.createDataFrame([{'id': 1, 'letter': 'A'}, {'id': None, 'letter': 'B'}, {'id': 4, 'letter': 'D'}],
'id INT, letter STRING')
letters_1.join(letters_2, on=['id'], how='full_outer').show()
If you are expecting to see four rows, surprise, surprise, there are five!
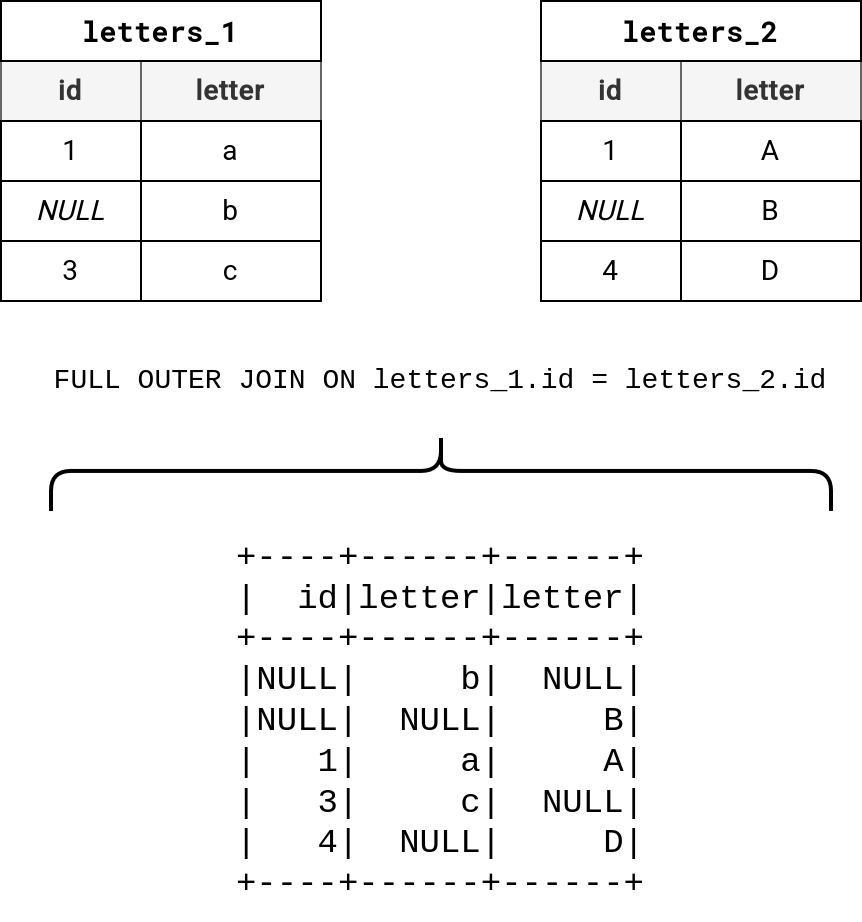
Why?
A NULL is a special value; in fact, it's a marker to represent an unknown value. For that reason, you cannot consider it the same way as you would consider ids 1, 3, or 4 from the previous code snippet. Since NULL's value is unknown, it seems now obvious that joining null columns returns an unknown result, so you can't really say that rows with letters b and B from our example should be combined.
If my first example doesn't convince you, let's take an opposite approach and see what would happen if the databases were considering NULLs as real values. To see the impact we have a dataset like this
letters_1 = spark.createDataFrame([{'id': 1, 'letter': 'a'}, {'id': None, 'letter': 'b'}, {'id': 3, 'letter': 'c'}],
'id INT, letter STRING')
letters_2 = spark.createDataFrame([{'id': 1, 'letter': 'A'}, {'id': None, 'letter': 'B'}, {'id': 4, 'letter': 'D'},
{'id': None, 'letter': 'E'}, {'id': None, 'letter': 'F'}], 'id INT, letter STRING')
letters_1.join(letters_2, on=['id'], how='full_outer').show()
Assuming the NULLs would be real values - you know it, they are not, but this opposite example helps show output inconsistency - let's take a look what would be the outcome of the previous code snippet:

As you can notice, the join that generates b-B does make sense but it also generates b-E and b-F that from our letter-to-letter matching don't make any sense.
Handling NULLs in joins explicitly
However, if for whatever reason you would like to join on the NULLs, so to reproduce the outcome from the previous schema, you could either add an extra condition to the join clause:
SELECT letters_1.id, letters_1.letter AS letter1, letters_2.letter AS letter2 FROM letters_1 FULL OUTER JOIN letters_2 ON letters_1.id = letters_2.id OR (letters_1.id IS NULL AND letters_2.id IS NULL)
Or eventually, you could use COALESCE to replace NULLs by some default value. An important point to keep in mind, though. You must be sure the default value doesn't exist for real. Otherwise, you might get inconsistent joins:
SELECT letters_1.id, letters_1.letter AS letter1, letters_2.letter AS letter2 FROM letters_1 FULL OUTER JOIN letters_2 ON COALESCE(letters_1.id, "not_existing_id") = COALESCE(letters_2.id, "not_existing_id")
Both will return the results you saw in the previous schema:
Version with IS NULL +----+-------+-------+ | id|letter1|letter2| +----+-------+-------+ | 1| a| A| |NULL| b| B| |NULL| b| E| |NULL| b| F| | 3| c| NULL| |NULL| NULL| D| +----+-------+-------+ Version with COALESCE # the id is NULL for D because the query reads letters_1.id +----+-------+-------+ | id|letter1|letter2| +----+-------+-------+ | 1| a| A| | 3| c| NULL| |NULL| NULL| D| |NULL| b| B| |NULL| b| E| |NULL| b| F| +----+-------+-------+
An alternative null-safe comparator
🙏 Thank you Daniel and Raki for bringing this up in your comment!
There might be chances your database supports a null-safe equality comparator which is <=>. It considers NULLs on both sides as true instead of unknown. This Apache Spark page, Databricks page, this MySQL page, or this Snowflake page explain it more in detail.
Having this null-sensitive check is also known as two-valued logic (or boolean logic) where there are only two possible outcomes: true or false. The extension is the three-valued logic where possible outcomes are: true, false, or unknown. You can learn more on that here or here. Thank you, Carsten, for mentioning this in your comment!
Before I let you go, I have bad news. JOINs with NULLs are not the single tricky and nullable place. There are some others that you're going to discover in next blog posts!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩