
In one of my previous posts, I described orchestration and coordination in the data context. At the end I promised to provide some code proofs to the theory and architecture described there. And that moment of truth is just coming.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is composed of 3 parts. The first describes the external trigger feature in Apache Airflow. The second one provides a code that will trigger the jobs based on a queue external to the orchestration framework. The final part shows assembled code.
External trigger
Apache Airflow DAG can be triggered at regular interval, with a classical CRON expression. But it can also be executed only on demand. In order to enable this feature, you must set the trigger property of your DAG to None. You can find an example in the following snippet that I will use later in the demo code:
dag = DAG(
dag_id='hello_world_a',
default_args={
"owner": "airflow",
'start_date': airflow.utils.dates.days_ago(1),
},
schedule_interval=None
)
def print_hello(**kwargs):
task_params = kwargs['dag_run'].conf['task_payload']
print('Hello world a with {}'.format(task_params))
PythonOperator(
task_id='hello_world_printer',
python_callable=print_hello,
provide_context=True,
dag=dag)
To trigger a DAG without schedule you have different choices. Either you can use the CLI "airflow trigger command or call the experimental API endpoint. For the sake of simplicity, in this introductory section I used the first version and its output looks like:
airflow@39042f105b22:~$ airflow trigger_dag -r test_run_06052019 hello_world
[2019-05-06 20:03:02,547] {{__init__.py:51}} INFO - Using executor SequentialExecutor
[2019-05-06 20:03:02,829] {{models.py:273}} INFO - Filling up the DagBag from /usr/local/a
irflow/dags
[2019-05-06 20:03:02,992] {{cli.py:240}} INFO - Created
If you want a more programmatical way, you can also use trigger_dag method from airflow.api.common.experimental.trigger_dag.trigger_dag. Please notice however that as of this writing, this method is exposed in an experimental package and you should think twice before using it in your production code. Of course, do not forget to activate the DAG. If you keep it in pause, it won't trigger even if you say it to do so.
Triggering DAG
In Data pipelines: orchestration, choreography or both? I gave you an example of AWS Lambda triggering Airflow DAGs. Since I always try to keep the examples replayables at home, I will simulate here the event-driven behavior of AWS architecture with RabbitMQ and a static data producer.
But before I show you this simulation code, let's talk a little about 3 different external triggering methods in Apache Airflow:
- using HTTP API endpoint - it's good thanks to its universality. HTTP protocol is widely implemented in a lot of SDKs so making such calls shouldn't be a big deal. So you can even do multi-cloud projects with a central orchestration point deployed in one of the cloud providers. Another benefit of this approach is scalability.
You can then have as many producers as you want - you only need to ensure that your Apache Airflow instance won't get stuck because of too many calls of that type. Also, you should take special care for monitoring. Now you have 1 + x points to monitor where x is the number of producers. Another point to consider is security. After all, you're exposing your orchestration layer to the world - even if you limit the callability to your VPC, you will still have a risk that one of the producers makes some damages. - using a long-running local process calling Airflow CLI - long time I thought using it for this demo post but I started to look how to monitor and ensure the longevity of this process and found that it was not an easy task. It's a good candidate for testing though since you simply need to continuously poll your source and execute DAGs accordingly to received events.
- using TriggerDagRunOperator - when I found trigger_dag method described above, I immediately checked its users. One of them was TriggerDagRunOperator which according to the documentation, is responsible for "Triggers a DAG run for a specified ``dag_id``" when a specific condition is met". And it fits perfectly for what I'm trying to do in this post. The single problem is that the check condition will be executed in CRON manner and not right after a triggering event. So unlike 2 previously discussed solutions, this one is less reactive. The second drawback is scalability. Since the operator returns the single DAG to run, you will need to poll 1 event at a time. That's why if latency is your high priority, you should think about other alternatives. Also, if you have a single message queue with DAGs to execute, you will end up with quite complicated DAG with probably a lot of branches.
On the other side, this solution centralizes all your orchestration logic in a single place. I want to say that you're using the same abstraction of DAGs everywhere, so it can be much simpler to understand by newcomers in your team. Another good thing is that you have 1 place to monitor.
In the following sections I will present 2 approaches of triggering a DAG externally in Apache Airflow. The first will use TriggerDagRunOperator. I think that it may fit to several high latency (= few external triggers) cases where even regenerating the triggers should be simple. In another part I will show you an example with HTTP call. I will focus there particularly on the reprocessing part and show you that even if you reprocess externally triggered DAGs, you will still keep the same input parameters.
TriggerDagRunOperator example
To demonstrate the use of TriggerDagRunOperator I will use these 2 Docker images:
version: '3.1'
services:
webserver:
image: puckel/docker-airflow:1.10.2
restart: always
environment:
# Loads DAG examples
- LOAD_EX=y
networks:
airflow-external-trigger-network:
ipv4_address: 111.18.0.20
volumes:
- ./dags:/usr/local/airflow/dags
- ./requirements.txt:/requirements.txt
- ./scripts:/tmp
ports:
- "8081:8080"
command: webserver & airflow scheduler
healthcheck:
test: ["CMD-SHELL", "[ -f /usr/local/airflow/airflow-webserver.pid ]"]
interval: 30s
timeout: 30s
retries: 3
rabbitmq:
image: rabbitmq:3.7-management
restart: always
networks:
airflow-external-trigger-network:
ipv4_address: 111.18.0.21
hostname: rabbitmqdocker
ports:
- "15672:15672"
networks:
airflow-external-trigger-network:
driver: bridge
ipam:
driver: default
config:
- subnet: 111.18.0.0/16
To push the messages to RabbitMQ I will use Pika library and the following code:
connection = pika.BlockingConnection(pika.ConnectionParameters('111.18.0.21'))
channel = connection.channel()
channel.queue_declare(queue='external_airflow_triggers', durable=True)
tasks = ['hello_world_a', 'hello_world_b', 'hello_world_c']
while True:
print('Producing messages at {}'.format(datetime.utcnow()))
task_to_trigger = choice(tasks)
event_time = str(datetime.utcnow())
message = json.dumps(
{'task': task_to_trigger, 'params': {'event_time': event_time, 'value': randint(0, 10000)}}
)
channel.basic_publish(exchange='', routing_key='external_airflow_triggers',
body=message)
print(" [x] Sent {}".format(message))
sleep(2)
connection.close()
The code responsible for routing the messages and triggering appropriated DAGs looks like:
dag = DAG(
dag_id='external_trigger',
default_args={
"owner": "airflow",
'start_date': airflow.utils.dates.days_ago(1),
},
schedule_interval='*/1 * * * *',
)
def consume_message(**kwargs):
connection = pika.BlockingConnection(pika.ConnectionParameters('111.18.0.21'))
channel = connection.channel()
channel.queue_declare(queue='external_airflow_triggers', durable=True)
method_frame, header_frame, body = channel.basic_get(queue='external_airflow_triggers')
json_params = json.loads(body)
kwargs['ti'].xcom_push(key='job_params', value=json.dumps(json_params['params']))
channel.basic_ack(delivery_tag=method_frame.delivery_tag)
connection.close()
print("Got message ? {}".format(body))
return json_params['task']
router = BranchPythonOperator(
task_id='router',
python_callable=consume_message,
dag=dag,
provide_context=True,
depends_on_past=True
)
def trigger_dag_with_context(context, dag_run_obj):
ti = context['task_instance']
job_params = ti.xcom_pull(key='job_params', task_ids='router')
dag_run_obj.payload = {'task_payload': job_params}
return dag_run_obj
task_a = trigger = TriggerDagRunOperator(
task_id='hello_world_a',
trigger_dag_id="hello_world_a",
python_callable=trigger_dag_with_context,
params={'condition_param': True, 'task_payload': '{}'},
dag=dag,
provide_context=True,
)
task_b = TriggerDagRunOperator(
task_id='hello_world_b',
trigger_dag_id="hello_world_b",
python_callable=trigger_dag_with_context,
params={'condition_param': True, 'task_payload': '{}'},
dag=dag,
provide_context=True,
)
task_c = TriggerDagRunOperator(
task_id='hello_world_c',
trigger_dag_id="hello_world_c",
python_callable=trigger_dag_with_context,
params={'task_payload': '{}'},
dag=dag,
provide_context=True,
)
router >> task_a
router >> task_b
router >> task_c
In the following image you can see how the routing DAG behaved after executing the code:
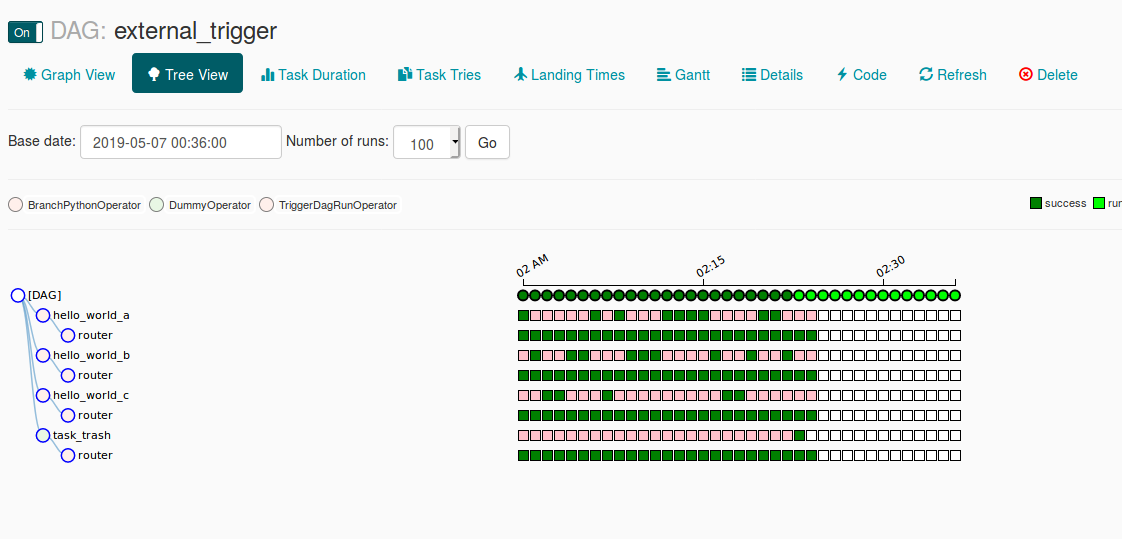
It works but as you can imagine, the frequency of publishing messages is much higher than consuming them. Hence, if you want to trigger the DAG in the response of the given event as soon as it happens, you may be a little bit deceived. That's why I will also try the solution with an external API call.
Aside from the scalability, there are some logical problems with this solution. First, our "router" DAG is not idempotent - the input always changes because of non-deterministic character of RabbitMQ queue. So, if you have some problems in your logic and restart the pipeline, you won't see already processed messages again - unless you will never retry the router tasks and only reprocess triggered DAGs which in this context could be an acceptable trade-off.
Another point to analyze related to replayability concerns externally triggered DAGs. Since they receive the parameters from an external source, will they keep the same parameters when they will be reprocessed? To check that, I cleaned the state of one of the executions of hello_world_a. The input parameters survived the retry, as shown in the following images:
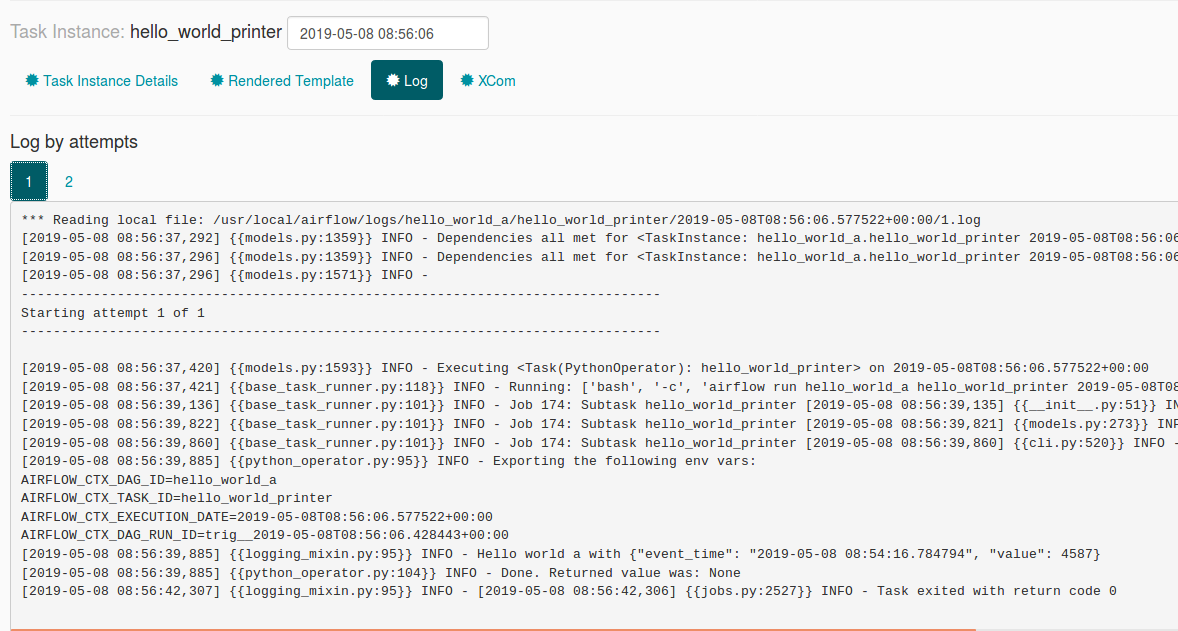
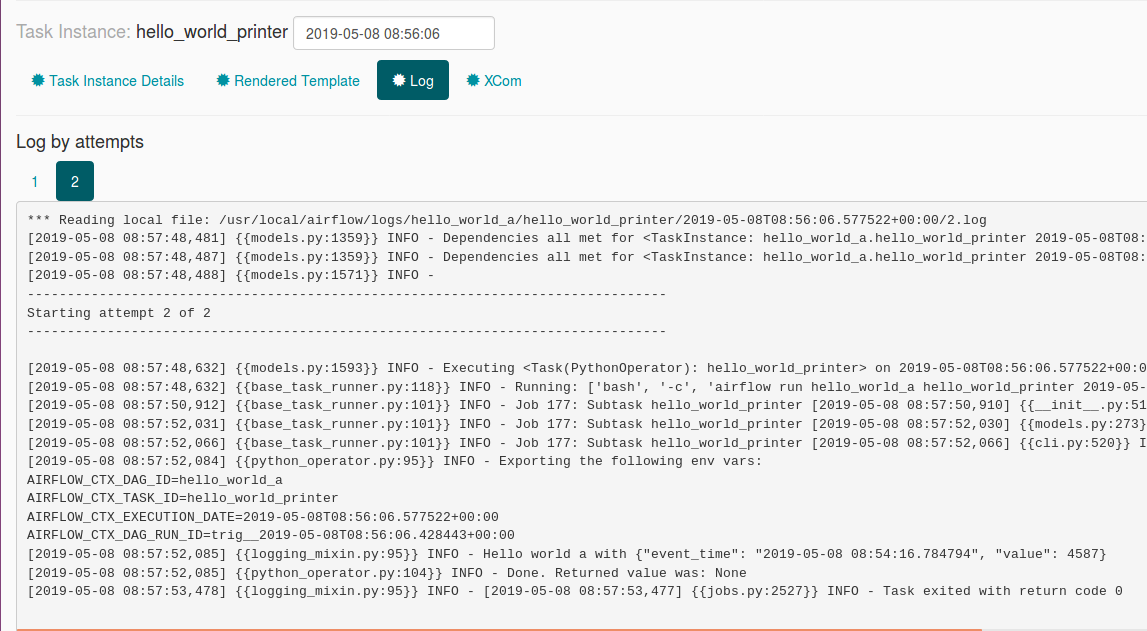
So to sum-up, a good point here is that there is still a single place to monitor. On the other side this approach doesn't do what Apache Airflow is supposed to do since it simulates a streaming processing. Let's then check another solution, the one with external API.
External API call
As I explained before, the good point of an external API call is that it scales pretty well. If you have plenty of S3 objects created that must trigger different DAGs, you won't wait 1 minute before triggering every execution for them. On the other side, this distributed (coordinated) approach will require a little bit more monitoring effort because of multiple potential sources of failure.
To test external triggering you can make simple curl calls:
bartosz:~/workspace/airflow-trigger/docker$ curl -X POST http://localhost:8081/api/experimental/dags/hello_world_a/dag_runs -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -d '{"conf":"{\"task_payload\":\"payload1\"}"}'
{
"message": "Created "
}
bartosz:~/workspace/airflow-trigger/docker$ curl -X POST http://localhost:8081/api/experimental/dags/hello_world_a/dag_runs -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -d '{"conf":"{\"task_payload\":\"payload2\"}"}'
{
"message": "Created "
}
bartosz:~/workspace/airflow-trigger/docker$ curl -X POST http://localhost:8081/api/experimental/dags/hello_world_a/dag_runs -H 'Cache-Control: no-cache' -H 'Content-Type: application/json' -d '{"conf":"{\"task_payload\":\"payload3\"}"}'
{
"message": "Created "
}
As you can see, all DAGs were correctly triggered - of course, I omit the authentication only for the sake of simplicity. Since these DAGs are triggered externally, I must also check whether the configuration passed as "task_payload" parameter is kept between retried executions. In the following video you can see that it's the case:
External triggers are a good way to simulate hybrid orchestration solution using external coordination system. They scale pretty good, help to write the processing logic more responsible than static CRON expressions. But there are not only benefits. As shown in this post, you will either have multiple extra places to monitor, gain some latency or longevity issues to overcome.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
In the second post of this week I illustrate an implementation of hybrid orchestration and choreography approach applied to #data pipelines with #ApacheAirflow https://t.co/RZnZoBxADU
— Bartosz Konieczny (@waitingforcode) July 11, 2019