
Some time ago I found an interesting article describing 2 faces of synchronizing the data pipelines - orchestration and choreography. The article ended with an interesting proposal to use both of them as a hybrid solution. In this post, I will try to implement that idea.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is composed of 3 parts. The first one reminds the basics from the article quoted in the "Read also" section. The second part focuses more on the hybrid approach explanation whereas the last one shows a sample implementation.
Orchestration vs choreography
Before we go to the main topic of this post, let's recall some basics. The first is the definition of orchestration. In the data pipelines, an orchestrator is a component responsible for managing the processes. It's the only one who knows which pipeline should be executed at a given moment and it's the single component able to trigger that execution.
On the other side, the choreography relies on the separate microservices architecture where every service knows what to do at a given moment of the day. The services don't communicate directly. Instead, they communicate indirectly with an event-based architecture. Every service knows then how to react at each of subscribed events.
Both approaches have their pros and cons. The orchestrator provides a unified view of the system but it's less flexible than the choreography. But the choreography uses loose coupling and sometimes the shared-nothing pipelines can be more difficult to manage than the highly coupled one. Especially when the context becomes more and more complex with every new added service and event.
The orchestration approach can be presented with DAG abstraction used by Apache Airflow to define data processing workflows. For instance, you can have the a data pipeline composed of the steps integrating the data coming from our different partners and one final DAG to make some final computation on them:
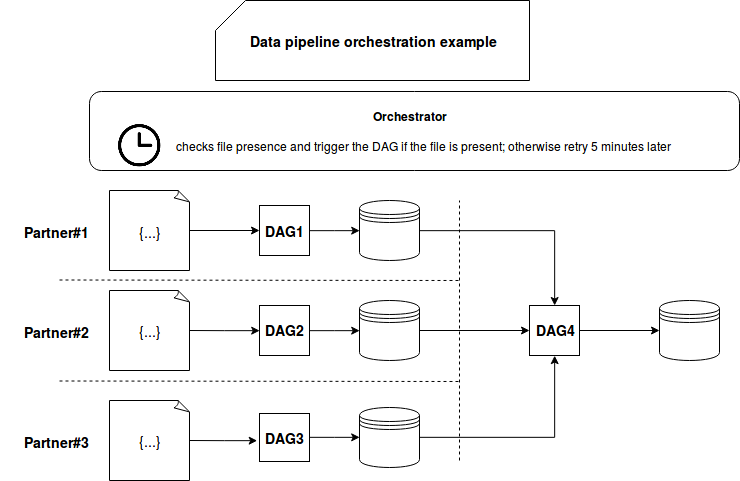
To illustrate the choreography pattern we could use the AWS event-driven architecture to integrate the data of our partners and trigger the final aggregation job:
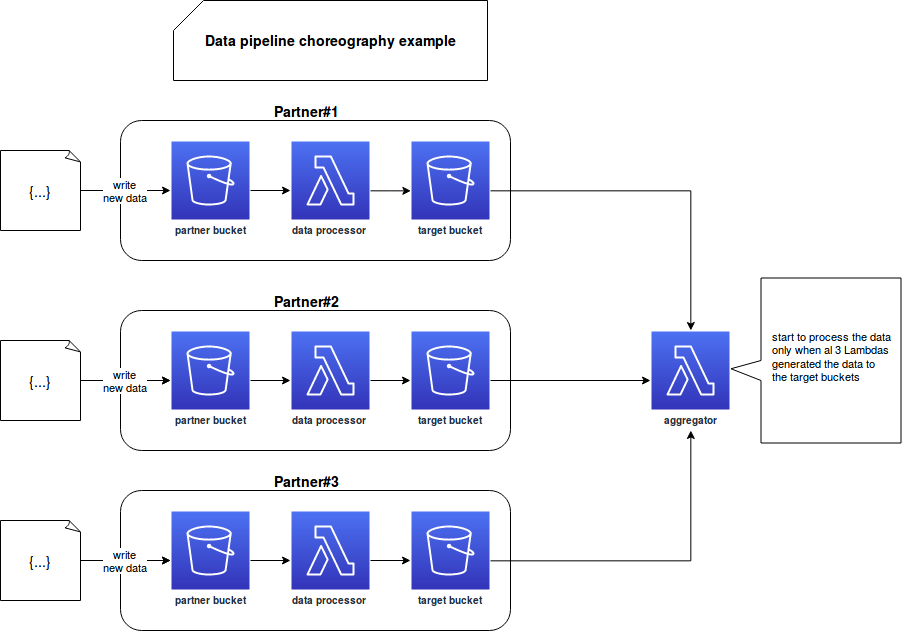
Maybe the schemas don't show it clearly but both approaches are slightly different. In the orchestration-based architecture, the orchestrator checks at regular interval whether it can start the partner's processing. With choreography, every partner has its dedicated data pipeline and the logic to start it is managed internally by the data processor Lambda function.
Hybrid solution theory
The choreography has the advantage of being based on specific events. Therefore, when some input data is not present, there won't be any processing action on top of it. On the other side, having an overall view of such a system may be complicated. Especially if you would like to know what part was executed and when. The hybrid solution discussed in "Big Data Pipeline - Orchestration or Choreography" post overcomes that shortcoming.
The hybrid approach still uses choreography to execute the processing logic but with an extension of a central events manager. The events manager is an application continuously consuming new events and triggering appropriate DAGs. The information about their execution is persisted in Apache Airflow metadata store automatically, since the physical execution of the task is delegated to the Apache Airflow engine.It provides a centralized way to visualize what happens with the data pipelines.
Hybrid solution implementation
The theory seems quite simple but mixing both words in a concrete manner is more complex. It's still should be possible though, especially with our natively event-driven example of an AWS data processing and the Apache Airflow orchestrator. Let me show it to you in the following schema:
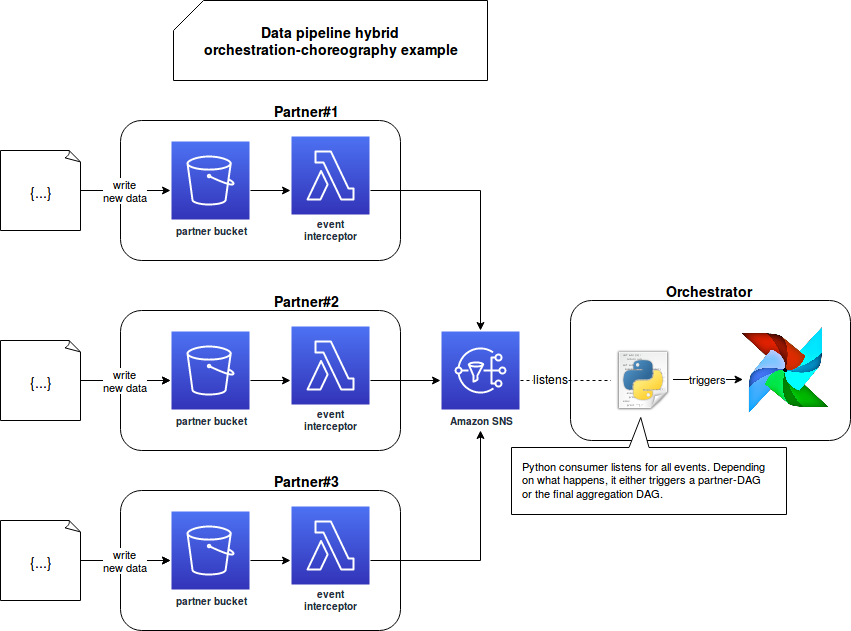
In the schema the Lambda function behaves only as an interceptor for produced event. It doesn't contain the processing logic. Instead, it catches the event and sends it to some streaming broker. On the Airflow's side, I added a simple consumer of the stream which, depending on the read event, may trigger a DAG. The triggered DAG hasn't the schedule and therefore can only be started with the external trigger. The consumer passes all the configuration specific to the given execution as the -c CONF parameter.
The orchestration and choreography are quite opposite concepts. The former one uses a single controller to manage jobs execution whereas the latter ones gives much more freedom to that execution. However, both can be mixed in order to mitigate their respective drawbacks. The orchestration provides a visibility and a better control whereas the orchestration more reactive behavior. In the post, I showed how I would implement that mix with the help of AWS event-driven services and Apache Airflow for, respectively, choreography and orchestration parts. During next weeks I will try to implement such hybrid solution and share m feedback of it.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data pipelines: orchestration, choreography or both? here:
Related blog posts:
In the first post in May I focus on the question about orchestrating vs coordinating #data pipelines. After the presentation of both approaches the post terminates with an architecture of hybrid #AWS and #ApacheAirflow based solution https://t.co/QmhtRYsm5b
— Bartosz Konieczny (@waitingforcode) May 2, 2019