
Uneven load is one of problems in distributed data processing. How to ensure that the any of nodes becomes a straggler ? Apache Beam proposes a solution for that in the form of fanout mechanism applicable in Combine transform.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post we'll discover this technique. The first section explains the main principles behind it. The next one shows how it can be used in 2 simple transforms.
Combine with fanout
Combine with fanout is another of divide-and-conquer approaches applied in distributed data processing. It's based on a simple assumption that some data can have more load than the other. For instance if your e-commerce store launched a landing page with an exclusive promotional code, this page will probably have more visitors than the rest. In consequence, instead of have an even load on workers, the worker responsible for landing page processing will have more work to do.
Apache Beam enables to tune the processing of uneven distribution in 2 different manners. The first one consists on defining the number of intermediate workers. These workers will compute partial results that will be send later to the final node. This final node will be in charge of merging these results in a final combine step. This mechanism is defined by Combine.Globally#withFanout(int fanout) method where the fanout parameter represents the number of intermediary steps to do before the final computation.
The other mechanism applies for key-value elements and is defined through Combine.PerKey#withHotKeyFanout(org.apache.beam.sdk.transforms.SerializableFunction<? super K,java.lang.Integer>) or Combine.PerKey#withHotKeyFanout(final int hotKeyFanout) method. The difference is that, thanks to the first function, we can apply a different logic for really hot keys and keep the no-fanout logic for the rest. The SerializableFunction passed in parameter should implement the apply method returning a number. This number will represent the number of intermediary nodes used for the computation for one or more specific keys (if all keys are supposed to be splitted, then the second method is more appropriated - under-the-hood it's transformed to a SerializableFunction returning the int parameter defined in the input).
The image below shows how the combine for values associated to one key should be distributed with the invocation of withHotKeyFanout(2):
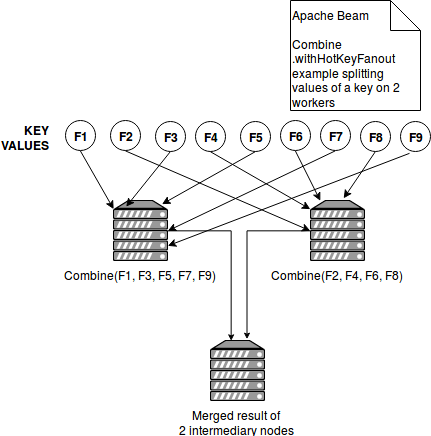
Combine fanouts examples
The following 2 tests show how the fanouts can be used in combine transforms:
private static final Instant NOW = new Instant(0);
private static final Instant SEC_1_DURATION = NOW.plus(Duration.standardSeconds(1));
@Test
public void should_apply_combine_with_fanout() {
Pipeline pipeline = BeamFunctions.createPipeline("Global combine with fanout", 2);
TestStream<String> letters = TestStream.create(StringUtf8Coder.of()).addElements(
TimestampedValue.of("a", SEC_1_DURATION), TimestampedValue.of("b", SEC_1_DURATION),
TimestampedValue.of("c", SEC_1_DURATION), TimestampedValue.of("d", SEC_1_DURATION),
TimestampedValue.of("e", SEC_1_DURATION), TimestampedValue.of("f", SEC_1_DURATION)
)
.advanceWatermarkToInfinity();
Duration windowDuration = Duration.standardSeconds(15);
Window<String> window = Window.into(FixedWindows.of(windowDuration));
PCollection<String> result = pipeline.apply(letters).apply(window)
.apply(Combine.globally(new SerializableFunction<Iterable<String>, String>() {
@Override
public String apply(Iterable<String> input) {
List<String> materializedInput = Lists.newArrayList(input);
Collections.sort(materializedInput);
String letters = String.join(",", materializedInput);
FanoutResultHolder.INSTANCE.addPartialResults(letters);
return letters;
}
}).withoutDefaults().withFanout(2));
IntervalWindow window1 = new IntervalWindow(NOW, NOW.plus(windowDuration));
PAssert.that(result).inFinalPane(window1).containsInAnyOrder("a,c,e,b,d,f");
pipeline.run().waitUntilFinish();
assertThat(FanoutResultHolder.INSTANCE.getPartialResults()).containsOnly("a,c,e", "b,d,f", "a,c,e,b,d,f");
}
@Test
public void should_apply_combine_with_hot_key_fanout() {
Pipeline pipeline = BeamFunctions.createPipeline("Combine per key with fanout");
Coder<String> utf8Coder = StringUtf8Coder.of();
KvCoder<String, String> keyValueCoder = KvCoder.of(utf8Coder, utf8Coder);
TestStream<KV<String, String>> letters = TestStream.create(keyValueCoder).addElements(
TimestampedValue.of(KV.of("a", "A"), SEC_1_DURATION), TimestampedValue.of(KV.of("a", "A"), SEC_1_DURATION),
TimestampedValue.of(KV.of("b", "B"), SEC_1_DURATION), TimestampedValue.of(KV.of("c", "C"), SEC_1_DURATION),
TimestampedValue.of(KV.of("d", "D"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E1"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F1"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E2"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F2"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E3"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F3"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E4"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F4"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E5"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F5"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E6"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F6"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E7"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F7"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E8"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F8"), SEC_1_DURATION), TimestampedValue.of(KV.of("e", "E9"), SEC_1_DURATION),
TimestampedValue.of(KV.of("f", "F9"), SEC_1_DURATION)
)
.advanceWatermarkToInfinity();
Duration windowDuration = Duration.standardSeconds(15);
Window<KV<String, String>> window = Window.into(FixedWindows.of(windowDuration));
SerializableFunction<String, Integer> fanoutFunction = new SerializableFunction<String, Integer>() {
@Override
public Integer apply(String key) {
// For the key f 2 intermediate nodes will be created
// Since we've 9 values belonging to this key, one possible configuration
// could be 5 and 4 entries per node
return key.equals("f") ? 2 : 1;
}
};
Combine.PerKeyWithHotKeyFanout<String, String, String> combineFunction =
Combine.<String, String, String>perKey(new Combiner()).withHotKeyFanout(fanoutFunction);
PCollection<KV<String, String>> lettersPCollection = pipeline.apply(letters).apply(window);
PCollection<KV<String, String>> result = lettersPCollection.apply(combineFunction);
IntervalWindow window1 = new IntervalWindow(NOW, NOW.plus(windowDuration));
PAssert.that(result).inFinalPane(window1).containsInAnyOrder(KV.of("a", "A, A"), KV.of("b", "B"), KV.of("c", "C"),
KV.of("d", "D"), KV.of("e", "E1, E2, E3, E4, E5, E6, E7, E8, E9"),
KV.of("f", "F1, F2, F3, F4, F5, F6, F7, F8, F9"));
pipeline.run().waitUntilFinish();
assertThat(FanoutWithKeyResultHolder.INSTANCE.getValuesInCombiners()).containsOnly(
"(empty)---(empty)---F2, F4, F6, F8", "(empty)---(empty)---F1, F3, F5, F7, F9",
"(empty)---F1, F3, F5, F7, F9", "(empty)---F2, F4, F6, F8",
"(empty)---(empty)---F1, F3, F5, F7, F9---F2, F4, F6, F8",
"(empty)---(empty)---D", "(empty)---(empty)---B",
"(empty)---(empty)---C", "(empty)---(empty)---A, A",
"(empty)---(empty)---E1, E2, E3, E4, E5, E6, E7, E8, E9"
);
}
public static class Combiner extends Combine.CombineFn<String, List<String>, String> {
@Override
public List<String> createAccumulator() {
return new ArrayList<>();
}
@Override
public List<String> addInput(List<String> accumulator, String input) {
accumulator.add(input);
Collections.sort(accumulator);
return accumulator;
}
@Override
public List<String> mergeAccumulators(Iterable<List<String>> accumulators) {
List<String> mergedAccumulator = new ArrayList<>();
accumulators.forEach(accumulatorToMerge -> mergedAccumulator.addAll(accumulatorToMerge));
String valuesToMerge = Lists.newArrayList(accumulators).stream()
.flatMap(listOfLetters -> {
Collections.sort(listOfLetters);
if (listOfLetters.isEmpty()) {
return Stream.of("(empty)");
} else {
return Stream.of(String.join(", ", listOfLetters));
}
})
.sorted()
.collect(Collectors.joining("---"));
FanoutWithKeyResultHolder.INSTANCE.addValues(valuesToMerge);
return mergedAccumulator;
}
@Override
public String extractOutput(List<String> accumulator) {
Collections.sort(accumulator);
return String.join(", ", accumulator);
}
}
enum FanoutResultHolder {
INSTANCE;
private Set<String> partialResults = new HashSet<>();
public Set<String> getPartialResults() {
return partialResults;
}
public void addPartialResults(String partialResult) {
partialResults.add(partialResult);
}
}
enum FanoutWithKeyResultHolder {
INSTANCE;
private List<String> valuesInCombiners = new ArrayList<>();
public void addValues(String values) {
valuesInCombiners.add(values);
}
public List<String> getValuesInCombiners() {
return valuesInCombiners;
}
}
Fanout is a small change that could widely improve the performance of the pipeline - especially when it processes unbalanced data where some keys require more load than the others. As explained in the first section, the fanouts in combine transform consist on adding some additional workers. They will compute partial results and send them to the final worker. Its role will consist on merging all of partial results into a final result. The fanouts behaves similarly to the tree aggregations in Spark.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Fanouts in Apache Beam's combine transform here:
Related blog posts:
Two last posts for the introduction to #ApacheBeam - fanout https://t.co/YNm6mpDBXV and joins https://t.co/5axy6EwoqI presented
— bardev (@waitingforcode) February 4, 2018