
As every library, Spark has methods than are used more often than the others. As often used methods we could certainly define map or filter. In the other side of less popular transformations we could place, among others, tree-like methods that will be presented in this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The first section presents available tree-like methods. The second part shows how to use them in data processing with Spark batch module.
Spark tree* actions
Spark's RDD defines 2 actions operating on trees: treeReduce(f: (T, T) => T, depth: Int = 2) and treeAggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U, depth: Int = 2). The comment explaining them tells that these operations are executed in a multi-level tree pattern. Google doesn't tell a lot about this term, so to understand it better, some code digging is inevitable.
But before doing that, let's go back to Spark 1.1 because this version brought tree aggregations. At that moment, the problem main related to classical aggregations (reduce, aggregate) was the performances. The time spent by driver on making these 2 operations was growing linearly with the number of partitions. And if each of them contained a lot of data, the final aggregation took a lot of time. BTW, it was proven in pull request adding tree aggregations to Spark that the time needed to shuffle data from executors to driver (for the final aggregation) is quite important and that thanks to tree aggregations it can be decreased even 3 times for partitions larger than 100MB.
So then, where is the magic ? If you are familiar with fork-join model (if not, you can read the post about Divide and conquer with fork/join framework), the analogy between tree aggregations seems obvious. Both divide one big computation on more smaller computation units until reaching some defined depth level. After reaching it, the results are computed from the smallest units and aggregated in bigger ones, as in following schema:
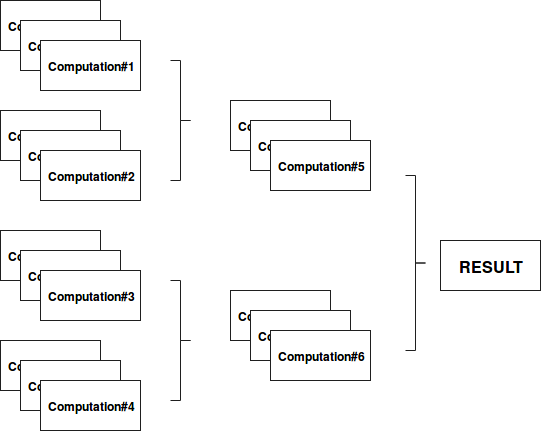
Tree aggregation example schema
Finally, tree aggregations don't differ a lot from normal aggregations (reduce, aggregate). The difference is that tree aggregations move less final results to the driver and that they have more intermediary stages because of the computational tree depth. Concretely in Spark, let's imagine a simple sum aggregation of a RDD having 10 partitions. The computational schema with the depth of 2 could look like:
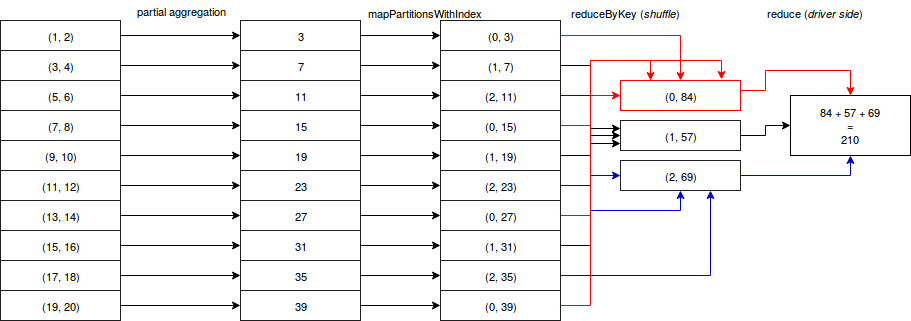
Above schema illustrates the algorithm of org.apache.spark.rdd.RDD#treeAggregate((U, T) => U, (U, U) => U, Int) method that is internally used by the 2 of tree aggregations: treeAggregate and treeReduce. The algorithm itself is presented in following snippet with comments matching image's labels (source comments were removed):
val cleanSeqOp = context.clean(seqOp)
val cleanCombOp = context.clean(combOp)
val aggregatePartition =
(it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
// "partial aggregation"
var partiallyAggregated = mapPartitions(it => Iterator(aggregatePartition(it)))
var numPartitions = partiallyAggregated.partitions.length
val scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2)
while (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) {
numPartitions /= scale
val curNumPartitions = numPartitions
// mapPartitionsWithIndex
partiallyAggregated = partiallyAggregated.mapPartitionsWithIndex {
(i, iter) => iter.map((i % curNumPartitions, _))
}.
// reduceByKey
reduceByKey(new HashPartitioner(curNumPartitions), cleanCombOp).values
}
// reduce
partiallyAggregated.reduce(cleanCombOp)
Example of tree* actions
To see exactly how define tree aggregations, let's write some learning tests:
"treeReduce" should "compute sum of numbers" in {
val numbersRdd = sparkContext.parallelize(1 to 20, 10)
val sumComputation = (v1: Int, v2: Int) => v1 + v2
val treeSum = numbersRdd.treeReduce(sumComputation, 2)
treeSum shouldEqual(210)
val reducedSum = numbersRdd.reduce(sumComputation)
reducedSum shouldEqual(treeSum)
}
"treeAggregate" should "compute sum of numbers" in {
val numbersRdd = sparkContext.parallelize(1 to 20, 10)
val sumComputation = (v1: Int, v2: Int) => v1 + v2
val treeSum = numbersRdd.treeAggregate(0)(sumComputation, sumComputation, 2)
treeSum shouldEqual(210)
val aggregatedSum = numbersRdd.aggregate(0)(sumComputation, sumComputation)
aggregatedSum shouldEqual(treeSum)
}
As you can see, tree aggregations don't differ a lot from classical aggregations. Methods signatures are the same and returned results also. But under-the-hood the amount of data moved to driver is smaller. As told in the introduction, it can be very helpful when RDD has a lot of partitions (in such case, the processing time increases linearly with the number of partitions).
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Tree aggregations in Spark here:
- [SPARK-2174][MLLIB] treeReduce and treeAggregate #1110 Apache Spark 1.1: MLlib Performance Improvements Implement treeReduce and treeAggregate
Related blog posts:
- Fanouts in Apache Beam's combine transform
- ParDo transformation in Apache Beam
- Data transformations in Apache Beam
- Dynamic resource allocation in Spark
- Per-partition operations in Spark
Misknown tree aggregations explained https://t.co/V18KCvWTpj #ApacheSpark
— bardev (@waitingforcode) May 14, 2017