
Defining the universal workload and associating corresponding resources is always difficult. Even if most of time expected resources will support the load, there always will be some interval in the year when data activity will grow (e.g. Black Friday). One of Spark's mechanisms helping to prevent processing failures in such situations is dynamic resource allocation.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post focuses on the dynamic resource allocation feature. The first part explains it with special focus on scaling policy. The second part points out why the described feature needs external shuffle service. The last part contains a demo showing how resources are dynamically allocated.
Dynamic resource allocation
By default, resources in Spark are allocated statically. It can lead to some problematic cases. Above all, it's difficult to estimate the exact workload and thus define the corresponding number of executors . It can produce 2 situations: underuse and starvation of resources. The first one means that too many resources were reserved but only a small part of them is used. The second case means that one processing takes all available resources and prevents other applications to start.
Spark executors
An executor in Spark is a long running unit of processing (JVM) launched at the start of Spark application and killed at its end. It's composed of CPU and memory that can be defined, respectively, in spark.executor.cores and spark.executor.memory properties. This unit of processing is persisted, i.e. it's not destructed and recreated on every executed job.
The executors shouldn't be confounded with the idea of workers. In fact, two or more executors can be launched on the same worker.
Dynamic resource allocation is one of solutions for above problems. It adapts resources used in processing according to the workload. This feature is controlled by spark.dynamicAllocation.enabled configuration entry. And thanks to other parameters we can specify the initial/minimal/maximal number of executors (spark.dynamicAllocation.(initialExecutors|minExecutors|maxExecutors).
Beside parameters listed previously, Spark has some other configuration parameters helping to define scaling policy:
- scaling up - each Spark task can be executed immediately or not. In this second case, it goes to the pending state. If some of these task remain in pending state for more than the time defined in spark.dynamicAllocation.schedulerBacklogTimeout, a request for adding more executors will be sent (of course, only if dynamic allocation is enabled). After sending the first request of this type, the subsequent requests are sent every spark.dynamicAllocation.sustainedSchedulerBacklogTimeout. By default, this value is the same as in the case of schedulerBacklogTimeout. The number of added executors in each round of requests grows exponentially (1, 2, 4, 8...). The exponential growth is adapted for 2 situations: when there are not many needed executors (1, 2, 4) and when there are a lot of them (heavy workload, 8)
- scaling down - but the executors can also be given back to the cluster if the workload decreases. In this situation some of them won't treat any data, so they will pass to idle state. The parameter spark.dynamicAllocation.executorIdleTimeout defines the acceptable idle state for each executor. If there are executors remaining idle for more than this duration, they are removed. However, if the executor to remove stores some blocks in its cache, it won't be destroyed immediately but after the time specified in spark.dynamicAllocation.cachedExecutorIdleTimeout parameter (of course, only if it's still idle after this duration).
External shuffle service
However, it's not enough to enable dynamic resource allocation through the configuration described in the previous section. In additional, the external shuffle service must be activated (spark.shuffle.service.enabled configuration entry). org.apache.spark.ExecutorAllocationManager that is a class responsible for the dynamic resource allocation, tells explicitly why the external shuffle service is needed:
// Require external shuffle service for dynamic allocation
// Otherwise, we may lose shuffle files when killing executors
if (!conf.getBoolean("spark.shuffle.service.enabled", false) && !testing) {
throw new SparkException("Dynamic allocation of executors requires the external " +
"shuffle service. You may enable this through spark.shuffle.service.enabled.")
}
Thanks to the external shuffle service, shuffle data is exposed outside of executor, in separate server, and thus can survive after the removal of given executor. In consequence, executors fetch shuffle data from the service and not from each other.
Dynamic resource allocation example
To test the dynamic resource allocation, the following code snippet will be used:
object Main {
@transient lazy val Logger = LoggerFactory.getLogger(this.getClass)
def main(args: Array[String]): Unit = {
// Activate speculative task
val conf = new SparkConf().setAppName("Spark dynamic allocation demo")
.set("spark.dynamicAllocation.enabled", "true")
.set("spark.shuffle.service.enabled", "true")
.set("spark.dynamicAllocation.initialExecutors", "1")
.set("spark.dynamicAllocation.executorIdleTimeout", "120s")
.set("spark.dynamicAllocation.schedulerBacklogTimeout", "1s")
val sparkContext = new SparkContext(conf)
Logger.info("Starting processing")
sparkContext.parallelize(0 to 5, 5)
.foreach(item => {
// for each number wait 3 seconds
Thread.sleep(3000)
})
Logger.info("Terminating processing")
}
}
As you can see, it blocks task executions for 3 seconds. According to the defined configuration, it should claim additional executors because of 1 second backlog timeout. The code was compiled with sbt package and deployed on my Dockerized Spark Yarn cluster composed of 3 workers. The application was launched with the following command:
spark-submit --deploy-mode cluster --master yarn --jars ./shared/spark-dynamic-resource-allocation_2.11-1.0.jar ./shared/spark-dynamic-resource-allocation_2.11-1.0.jar --class com.waitingforcode.Main
The allocation of additional executors can be observed in below image representing "Event timeline" part from Spark UI:
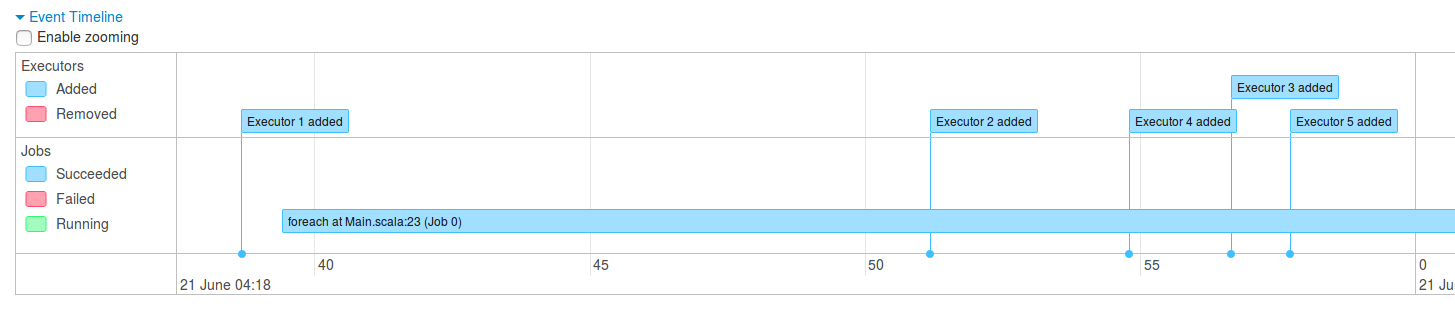
The activity of the dynamic allocation is also visible in the logs:
DEBUG ExecutorAllocationManager: Starting timer to add executors because pending tasks are building up (to expire in 1 seconds) DEBUG ExecutorAllocationManager: Clearing idle timer for 1 because it is now running a task INFO YarnAllocator: Driver requested a total number of 2 executor(s). DEBUG ApplicationMaster: Number of pending allocations is 0. Slept for 1472/3000 ms. INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2) DEBUG ApplicationMaster: Sending progress INFO YarnAllocator: Will request 1 executor container(s), each with 1 core(s) and 1408 MB memory (including 384 MB of overhead) DEBUG AMRMClientImpl: Added priority=1 DEBUG AMRMClientImpl: addResourceRequest: applicationId= priority=1 resourceName=* numContainers=1 #asks=1 INFO YarnAllocator: Submitted 1 unlocalized container requests. DEBUG ExecutorAllocationManager: Starting timer to add more executors (to expire in 1 seconds) INFO YarnAllocator: Launching container container_1498015239683_0008_01_000003 on host spark-slave-3 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
Spark offers the dynamic resource allocation as the solution for resources misuse. It helps to avoid the situation where the cluster composition doesn't fit to the workload. Thanks to the dynamic allocation, enabled with appropriated configuration entries, Spark asks for more resources when the workload increases and releases them once it decreases. As shown in the second section, one prerequisite is demanded. To use the dynamic resource allocation, the external shuffle service must be enabled. Thanks to it, shuffle files won't be lost after executor's decomission. The last part demonstrated the dynamic resource allocation in action. Based on simple thread sleep trick, we were able to see how ExecutorAllocationManager requested for more executors because of too many idle tasks.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Dynamic resource allocation in Spark here:
- Dynamically Allocate Cluster Resources to your Spark Application Investigation of Dynamic Allocation in Spark Job Scheduling
Related blog posts:
- RPC in Apache Spark
- Spark failure detection - heartbeats
- JARs split personality problem
- Code execution on driver and executors
- Tree aggregations in Spark