
The communication in distributed systems is an important element. The cluster members rarely share the hardware components and the single solution to communicate is the exchange of messages in the client-server model.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post explains how this kind of communication is implemented in Apache Spark. Its first part defines in the big picture what is the RPC. Next part shows how it's implemented in Apache Spark. The third section gives some configuration input while the last shows a sample communication between cluster members.
Definition
The RPC is an acronym for Remote Procedure Call. It's an protocol using client-server model. When the client executes a request, it's sent to the place called stub. The stub has the knowledge about the server able to execute the request as well as whole context needed by the server (e.g. parameters). When the request finally arrives to the appropriate server, it also reaches a stub in the server side. So captured request is later translated to the server-side executable procedure. After its physical execution, the result is sent back to the client.
An example of schema is represented in the following image:
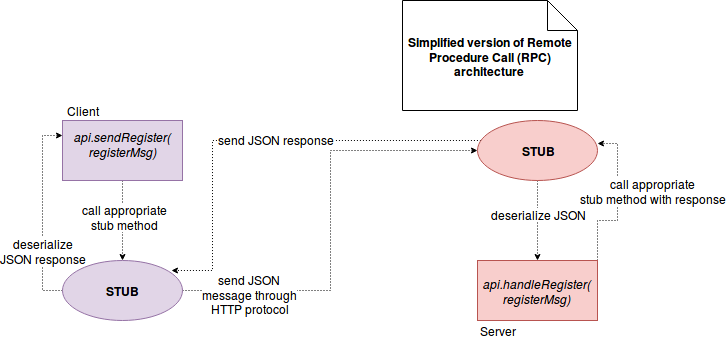
Implementation
The RPC in Apache Spark is implemented with the help of Netty client-server framework. The most of valuable RPC classes are stored in the org.apache.spark.rpc package but before describing them, let's explain how they interact together.
The object responsible for sending the messages to the appropriate endpoint (client stub) is represented by Dispatcher class. Via one of post* methods it prepares the instance of RPC message (RpcMessage class) and sends it to the expected endpoint.
The RPC endpoints are represented by 2 classes. The first one, RpcEndpoint is the physical representation that could be compared to the client's and server's stubs. This trait defines 3 different methods: onStart, receive and onStop. As these names let suppose, the first and the third ones are invoked when the endpoint starts and stops. The second method sends either requests or responses. The second class used with RPC is RpcEndpointRef. It's main role is to send the requests in one of available semantics: fire-and-forget (send(message: Any) method), synchronous request-response (askSync[T: ClassTag](message: Any): T) or asynchronous request-response (ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T]).
Among the implementations of RPC endpoints we can find the following classes:
- BlockManagerMasterEndpoint - it tracks the statuses of all slave's block managers. Concretely it's translated by handling the messages like: block manager (register, heartbeats, cache checks, block manager peers retrieval), block information (update), shuffle (removal), blocks locations retrieval, memory and storage statuses, RDD removal, broadcast removal, executor removal
- BlockManagerSlaveEndpoint - this endpoint is responsible for managing block managers on slave nodes. Among different messages it handles we can list the messages related to: block (removal, status retrieval, ids retrieval or block replication), RDD (removal), shuffle (removal), broadcast (removal), thread dump (triggering).
- ClientEndpoint - it's a proxy relaying the messages to the driver that seems to be used only in standalone cluster. Among its activity we can list driver starting and killing actions.
- CoarseGrainedExecutorBackend - the executor's endpoint in coarse grained mode (executors hold only during the duration of Spark job and destroyed at the end of it). It handles the following messages: register with driver (success and failure case), task lifecycle (launching and killing), executor lifecycle (stopping and shutdowning).
- DriverEndpoint - the driver's endpoint in coarse grained mode. It's responsible for the following messagess: task status updates, executors updates (resources available for given task, executor's killing on given host) and task killing.
- HeartbeatReceiver - as explained in the post about Spark failure detection - heartbeats, this class is responsible for heartbeat messages informing about liveness of the executor.
- LocalEndpoint - it has similar role to the DriverEndpoint, except the fact that it applies for local mode. Among the handled messages it doesn't kill executors.
- MapOutputTrackerMasterEndpoint - this endpoint is related to the MapOutputTrackerMaster. This class stores the information about where the map output of given stage is located on the master. These outputs are recorded from the shuffle-map tasks. The endpoint is in charge of getting map output locations for given shuffle step and stopping this endpoint.
- Master - represents master's node endpoint. It handles the messages like: workers lifecycle (registering new worker, killing unknown or terminated driver and executor processes on the worker, timeout verification, workers heartbeats handling), application lifecycle (registering, unregistering), driver (state changes), executor (state changes), leader (election or revoke, for the latter case the master is shut down), master recovery from failures.
- OutputCommitCoordinatorEndpoint - this endpoint represent the authority class that decides if given output can be committed to HDFS. This authority is present in both executors and driver. The difference between them is that the executors ones always sent the requests to the driver authority. Among the messages it's responsible only for the message telling to stop the endpoint.
- RpcEndpointVerifier - it checks the existence of other RPC endpoints.
- StateStoreCoordinator - coordinates the instances of org.apache.spark.sql.execution.streaming.state.StateStore stored remotely in the executors. As the name indicates, the StateStore is responsible for some of stateful streaming operations, as: FlatMapGroupsWithState, deduplicate or aggregations. It will be explained more in details in one of the next posts. The following messages are handled: active StateStore intances reporting for given executor, checking instance status (alive or not), getting location of specific StateStore, deactivating a StateStore or stopping the state store coordinatior.
- Worker - as the name makes it think, this endpoint represents a worker node that is globally responsible for all communication with the master node. More exactly, it handles the following messages: register status (success or failure), sending heartbeats, application directory cleaning, application termination event, master lifecycle (master node change, reconnection to the master node), executor lifecycle (starting, killing, state changing [see org.apache.spark.deploy.ExecutorState]), driver lifecycle (same as for executor)
- WorkerWatcher - it connects to the Worker in order to terminate the JVM for the interrupted connection. It's supposed to never receive the messages. Its only role is limited to handle: remote node connection, remote node disconnection and all network errors happened between the endpoint and any remote address.
Configuration
The RPC is not only about endpoints but also about the configuration. Spark accepts the following configuration properties:
- spark.rpc.message.maxSize - defines the max size of the message that can be exchanged in RPC. It applies for instance to map outputs and serialized tasks in coarse grained mode.
- spark.rpc.numRetries - tells how many times the connection will retry in case of failures.
- spark.rpc.retry.wait - defines the interval between subsequent connection retries.
- spark.rpc.askTimeout - represents the timeout for all RPC ask (query) operations
- spark.rpc.lookupTimeout - represents the timeout for the lookup operation. This operation happens for instance when coarse-grained executor is looking for the RPCEndpoint representation of the driver. At the moment of the lookup, the executor knows only the driver's URL.
Spark RPC example
In order to discover what happens with RPC we'll do a small trick and override the mentioned Dispatcher object by this one:
package org.apache.spark.rpc.netty
import org.apache.spark.network.client.RpcResponseCallback
import org.apache.spark.rpc.{RpcEndpoint, RpcEndpointRef}
import scala.concurrent.Promise
class LoggingDispatcher(delegate: Dispatcher, nettyEnv: NettyRpcEnv) extends Dispatcher(nettyEnv) {
var endpoints: Seq[RpcEndpointRef] = Seq.empty
var messageTypes: Seq[String] = Seq.empty
override def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef =
delegate.registerRpcEndpoint(name, endpoint)
override def getRpcEndpointRef(endpoint: RpcEndpoint): RpcEndpointRef = delegate.getRpcEndpointRef(endpoint)
override def removeRpcEndpointRef(endpoint: RpcEndpoint): Unit = delegate.removeRpcEndpointRef(endpoint)
override def stop(rpcEndpointRef: RpcEndpointRef): Unit = {
endpoints = endpoints :+ rpcEndpointRef
delegate.stop(rpcEndpointRef)
}
override def postToAll(message: InboxMessage): Unit = delegate.postToAll(message)
override def postRemoteMessage(message: RequestMessage, callback: RpcResponseCallback): Unit = {
delegate.postRemoteMessage(message, callback)
handleMessage(message)
}
override def postLocalMessage(message: RequestMessage, p: Promise[Any]): Unit = {
delegate.postLocalMessage(message, p)
handleMessage(message)
}
override def postOneWayMessage(message: RequestMessage): Unit = {
handleMessage(message)
delegate.postOneWayMessage(message)
}
private def handleMessage(message: RequestMessage) = messageTypes = messageTypes :+ message.content.getClass.toString
override def stop(): Unit = delegate.stop()
override def awaitTermination(): Unit = delegate.awaitTermination()
override def verify(name: String): Boolean = delegate.verify(name)
}
As you can see, it doesn't nothing more than memorizing the handled messages and stopped endpoints. Both properties are check in the learning test using a simple sum action:
"custom logging RPC dispatcher" should "show what messages are sent between nodes" in {
val envField = ReflectUtil.getDeclaredField(classOf[SparkContext], "org$apache$spark$SparkContext$$_env")
val sparkEnv: SparkEnv = envField.get(sparkContext).asInstanceOf[SparkEnv]
val rpcEnvField = ReflectUtil.getDeclaredField(classOf[SparkEnv], "rpcEnv")
val rpcEnv = rpcEnvField.get(sparkEnv).asInstanceOf[NettyRpcEnv]
val dispatcherField = ReflectUtil.getDeclaredField(classOf[NettyRpcEnv], "dispatcher")
val dispatcher = dispatcherField.get(rpcEnv).asInstanceOf[Dispatcher]
val loggingDispatcher = new LoggingDispatcher(dispatcher, rpcEnv)
// Finally override the dispatcher
dispatcherField.set(rpcEnv, loggingDispatcher)
val numbersRdd = sparkContext.parallelize(1 to 100, 2)
val sum = numbersRdd.sum()
sparkContext.stop()
sum shouldEqual 5050
val endpointNames = loggingDispatcher.endpoints.map(endpoint => endpoint.name)
endpointNames should contain allOf("HeartbeatReceiver", "MapOutputTracker", "BlockManagerEndpoint1",
"BlockManagerMaster", "OutputCommitCoordinator")
loggingDispatcher.messageTypes should contain allOf(
"class org.apache.spark.storage.BlockManagerMessages$UpdateBlockInfo",
"class org.apache.spark.scheduler.local.ReviveOffers$", "class org.apache.spark.scheduler.local.StatusUpdate",
"class org.apache.spark.scheduler.local.StopExecutor$",
"class org.apache.spark.StopMapOutputTracker$",
"class org.apache.spark.storage.BlockManagerMessages$StopBlockManagerMaster$",
"class org.apache.spark.scheduler.StopCoordinator$")
}
// While the getDeclaredField method is a simple getter for Spark's private fields:
def getDeclaredField[T](fieldClass: Class[T], fieldName: String): Field = {
val searchedField = fieldClass.getDeclaredField(fieldName)
searchedField.setAccessible(true)
searchedField
}
RPC is used in the communication between 2 remote nodes. As shown in this post, it's also used in Apache Spark - mainly for the driver-executor and master-slave synchronization. But, as we could discover in the 2nd section, the RPC is also about block management, heartbeats and streaming aggregations. This protocol is not neglected as prooven in the third part. Incorrectly configured it can have a negative impact on the performance.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about RPC in Apache Spark here:
Related blog posts:
- Spark failure detection - heartbeats
- Dynamic resource allocation in Spark
- JARs split personality problem
- Code execution on driver and executors
- Configuration of Spark architecture members
Zoom on the use of the RPC in #ApacheSpark https://t.co/9DjFssyK80
— bardev (@waitingforcode) February 18, 2018