
After Delta Lake and Apache Iceberg it's time to see the reading part of Apache Hudi. Despite an apparent similarity with the aforementioned table formats, Apache Hudi has an interesting reading specificity related to the different table types.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Read types
That's the first thing that you'll see when analyzing the reading logic. Besides different table types (Merge-On-Read and Copy-On-Write), Apache Hudi also has different query types. Both combined generate a pretty interesting data reading capability matrix where each scenario has a dedicated BaseRelation implementation to communicate with Apache Spark:
- Copy-On-Write table with snapshot or read-optimized query, Merge-On-Read table with read-optimized query. Here Apache Hudi creates a BaseFileOnlyRelation that eventually falls back into Spark's HadoopFsRelation.
- Merge-On-Read table with snapshot read. Here Hudi handles it with MergeOnReadSnapshotRelation.
- Bootstrap action. It applies to any table and query type but only when the query concerns bootstrapping an Apache Hudi table from existing data. This scenario is managed from HoodieBootstrapRelation.
- Copy-On-Write table with incremental query. In this case, Apache Hudi reads only new data since an instantTime. It uses the IncrementalRelation.
- Merge-On-Read table with incremental query. In that case, Apache Hudi creates an instance of MergeOnReadIncrementalRelation.
MergeOnReadSnapshotRelation
That's the implementation used for consistent reads of Merge-On-Read tables, i.e, it's the one reading the base (data) Parquet files and applying all the changes made to the records from the log Avro files (more on that here → ACID file formats - writing: Apache Hudi). You'll find this resolution complexity in the code reading the data, and more specifically in the HoodieMergeOnReadRDD.
But before Hudi creates this RDD, it does multiple metadata-based operations to prepare the reading context, such as:
- Creating a new instance of HoodieFileIndex with all files to read.
- Partition pruning. Apache Hudi classifies the query filters into data and partition filters, and applies the latter ones while listing the files to read in the query.
- Data skipping. Besides knowing the files to read, HoodieFileIndex also has access to the column stats index which enables data skipping. The feature requires turning the index.column.stats.enable and Metadata Table on.
- Schemas. Before reading the data, Apache Hudi also resolves the schema to apply on the input data. At this moment, it also detects if the table supports schema evolution.
After doing all this heavy work, Apache Hudi is finally ready to initialize the HoodieMergeOnReadRDD. In addition to the attributes resolved before, the constructor takes a merge type parameter from the hoodie.datasource.merge.type option. Is it important? Yes, and how much! It's one of the properties conditioning the physical files reading. Take a look at the HoodieMergeOnReadRDD's compute method:
class HoodieMergeOnReadRDD(@transient sc: SparkContext,
@transient config: Configuration, fileReaders: HoodieMergeOnReadBaseFileReaders,
tableSchema: HoodieTableSchema,
requiredSchema: HoodieTableSchema, tableState: HoodieTableState,
mergeType: String, @transient fileSplits: Seq[HoodieMergeOnReadFileSplit])
extends RDD[InternalRow](sc, Nil) with HoodieUnsafeRDD {
/// ...
override def compute(split: Partition, context: TaskContext): Iterator[InternalRow] = {
val mergeOnReadPartition = split.asInstanceOf[HoodieMergeOnReadPartition]
val iter = mergeOnReadPartition.split match {
case dataFileOnlySplit if dataFileOnlySplit.logFiles.isEmpty =>
// ...
case logFileOnlySplit if logFileOnlySplit.dataFile.isEmpty =>
// ..
case split if mergeType.equals(DataSourceReadOptions.REALTIME_SKIP_MERGE_OPT_VAL) =>
// ...
case split if mergeType.equals(DataSourceReadOptions.REALTIME_PAYLOAD_COMBINE_OPT_VAL) =>
// ...
As you can see, the data reading depends on the input files associated with the partition and the merge type:
- LogFileIterator is used when the files list contains the log files only. It simply iterates over all records present in the delta files.
- SkipMergeIterator extends the LogFileIterator to handle the scenario where the merge of data and delta log records is not necessary.
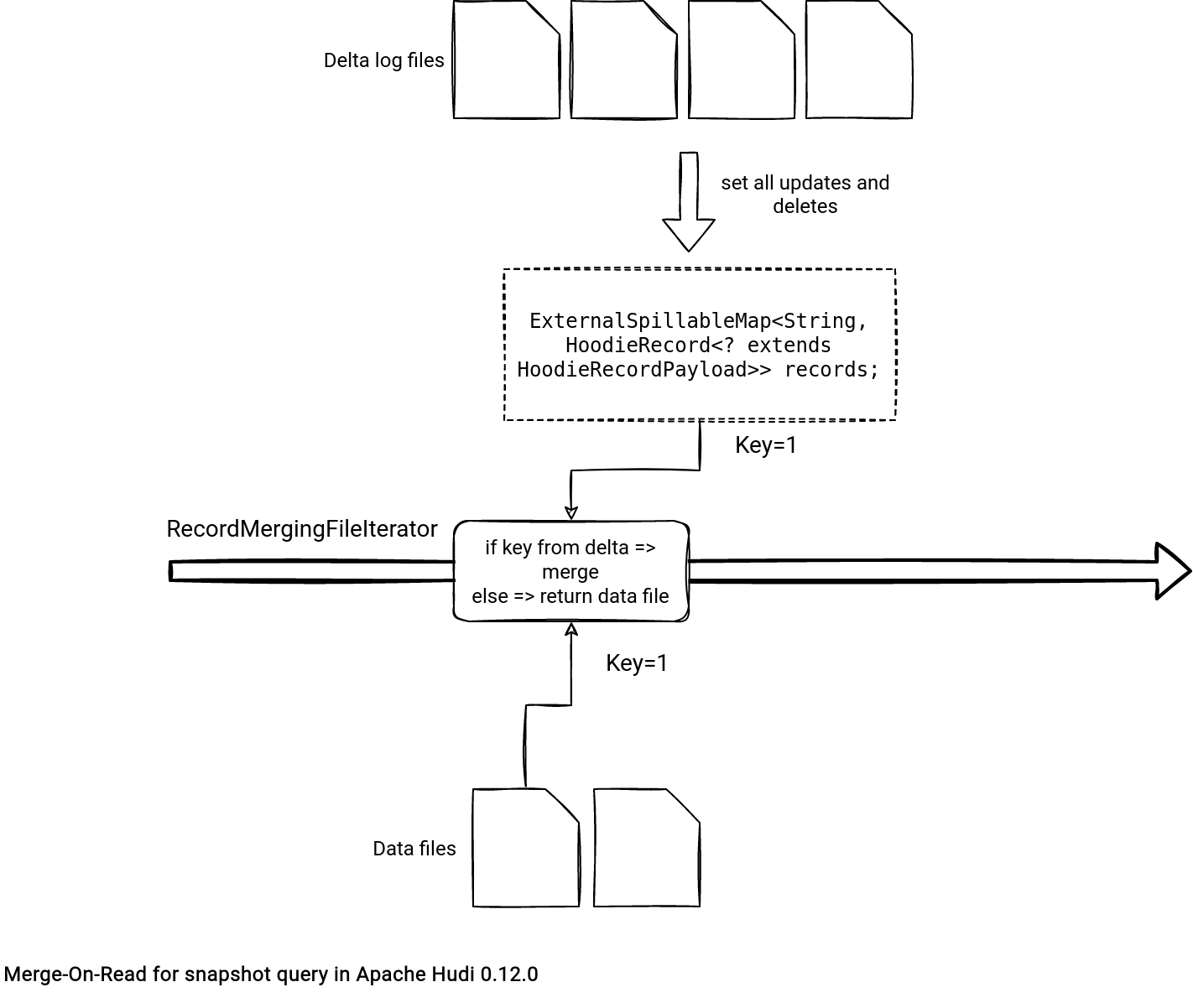
- RecordMergingFileIterator also extends the LogFileIterator. It handles the scenario where data and delta log files require merging.
The SkipMergeIterator is basically a LogFileIterator except that it defines an extra iterator for the data files that is invoked before the delta files, potentially leading to duplicates:
private class SkipMergeIterator(split: HoodieMergeOnReadFileSplit,
baseFileReader: BaseFileReader,
config: Configuration)
extends LogFileIterator(split, config) {
private val baseFileIterator = baseFileReader(split.dataFile.get)
override def hasNext: Boolean = {
if (baseFileIterator.hasNext) {
// No merge is required, simply load current row and project into required schema
recordToLoad = requiredSchemaUnsafeProjection(baseFileIterator.next())
true
} else {
super[LogFileIterator].hasNext
}
}
Even though the RecordMergingFileIterator also extends the LogFileIterator, it works differently. The LogFileIterator creates an instance of HoodieMergedLogRecordScanner that iterates over all the delta log files and builds a map storing the most recent entry for each key:
public class HoodieMergedLogRecordScanner extends AbstractHoodieLogRecordReader
implements Iterable<HoodieRecord<? extends HoodieRecordPayload>> {
// ...
protected final ExternalSpillableMap<String, HoodieRecord<? extends HoodieRecordPayload>> records;
protected void processNextRecord(HoodieRecord<? extends HoodieRecordPayload> hoodieRecord) throws IOException {
String key = hoodieRecord.getRecordKey();
if (records.containsKey(key)) {
// Merge and store the merged record. The HoodieRecordPayload implementation is free to decide what should be
// done when a DELETE (empty payload) is encountered before or after an insert/update.
HoodieRecord<? extends HoodieRecordPayload> oldRecord = records.get(key);
HoodieRecordPayload oldValue = oldRecord.getData();
HoodieRecordPayload combinedValue = hoodieRecord.getData().preCombine(oldValue);
// If combinedValue is oldValue, no need rePut oldRecord
if (combinedValue != oldValue) {
HoodieOperation operation = hoodieRecord.getOperation();
records.put(key, new HoodieAvroRecord<>(new HoodieKey(key, hoodieRecord.getPartitionPath()), combinedValue, operation));
}
} else {
// Put the record as is
records.put(key, hoodieRecord);
}
}
During the merge, the RecordMergingFileIterator iterates over all records from the data files and calls the remove(...) method of the records map. If the call returns something, it means there is a merge action to do (skip the row if removed or get the value from the delta file). Otherwise, Hudi returns the version from the data file:
BaseFileOnlyRelation
The BaseFileOnlyRelation ignores the changes from delta files. Logically then, its reading logic should be easier than for MergeOnReadSnapshot. Indeed, it is, but there are also some gotchas!
First, the results. Since the BaseFileOnlyRelation is present for the Merge-On-Read table or read-optimized queries, it might generate different results than the snapshot query for Merge-On-Read tables. And that's quite normal since the reader doesn't perform any merge step with the log data.
Second, the BaseFileOnlyRelation might not be the final class communicating with Apache Spark! Why? The answer comes from HUDI-3896:
After migrating to Hudi's own Relation impls, we unfortunately broke off some of the optimizations that Spark apply exclusively for `HadoopFsRelation`.
While these optimizations could be perfectly implemented for any `FileRelation`, Spark is unfortunately predicating them on usage of HadoopFsRelation, therefore making them non-applicable to any of the Hudi's relations.
Proper longterm solutions would be fixing this in Spark and could be either of:
1. Generalizing such optimizations to any `FileRelation`
2. Making `HadoopFsRelation` extensible (making it non-case class)
One example of this is Spark's `SchemaPrunning` optimization rule (HUDI-3891): Spark 3.2.x is able to effectively reduce amount of data read via schema pruning (projecting read data) even for nested structs, however this optimization is predicated on the usage of `HadoopFsRelation`:
That's the reason why for all but one scenario, the reading falls back to the HadoopFsRelation. What is this particular scenario? When this method returns true:
abstract class HoodieBaseRelation(val sqlContext: SQLContext, val metaClient: HoodieTableMetaClient,
val optParams: Map[String, String],
schemaSpec: Option[StructType]) {
// ..
def hasSchemaOnRead: Boolean = internalSchemaOpt.isDefined
// ...
This schema-on-read flag is the schema evolution flag of the table represented by the hoodie.schema.on.read.enable property. Although, the schema evolution will be the topic of another blog post, it's good to know why only the BaseFileOnlyRelation can handle it. This Hudi-specific relation creates a reader capable of merging the files schema to the schema required by the reader:
object HoodieBaseRelation extends SparkAdapterSupport {
// ...
def projectReader(reader: BaseFileReader, requiredSchema: StructType): BaseFileReader = {
checkState(reader.schema.fields.toSet.intersect(requiredSchema.fields.toSet).size == requiredSchema.size)
if (reader.schema == requiredSchema) {
reader
} else {
val read = reader.apply(_)
val projectedRead: PartitionedFile => Iterator[InternalRow] = (file: PartitionedFile) => {
// NOTE: Projection is not a serializable object, hence it creation should only happen w/in
// the executor process
val unsafeProjection = generateUnsafeProjection(reader.schema, requiredSchema)
read(file).map(unsafeProjection)
}
BaseFileReader(projectedRead, requiredSchema)
}
// ...
}
class BaseFileOnlyRelation(sqlContext: SQLContext,
metaClient: HoodieTableMetaClient,
optParams: Map[String, String],
userSchema: Option[StructType],
globPaths: Seq[Path])
extends HoodieBaseRelation(sqlContext, metaClient, optParams, userSchema) with SparkAdapterSupport {
// ...
protected override def composeRDD(fileSplits: Seq[HoodieBaseFileSplit],
tableSchema: HoodieTableSchema,
requiredSchema: HoodieTableSchema,
requestedColumns: Array[String],
filters: Array[Filter]): RDD[InternalRow] = {
val (partitionSchema, dataSchema, requiredDataSchema) =
tryPrunePartitionColumns(tableSchema, requiredSchema)
// ...
val projectedReader = projectReader(baseFileReader, requiredSchema.structTypeSchema)
// SPARK-37273 FileScanRDD constructor changed in SPARK 3.3
sparkAdapter.createHoodieFileScanRDD(sparkSession, projectedReader.apply, fileSplits.map(_.filePartition), requiredSchema.structTypeSchema)
.asInstanceOf[HoodieUnsafeRDD]
// ...
That was the last part of the series about table file formats readers. But as you saw, it introduced several other interesting features, such as schema evolution. I haven't picked the theme for the next part of the series, though!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Apache Hudi supports Merge-On-Read and Copy-On-Write tables. They behave differently at writing but also at reading where Hudi performs some extra steps for the MoR type. If you want to discover which ones, the answer is in the new blog post ? https://t.co/hwIouA8oYO
— Bartosz Konieczny (@waitingforcode) October 2, 2022