
It's only when I was preparing the 2nd blog post of the series that I realized how bad my initial plan was. The article you're currently reading had been initially planned as the 6th of the series. But indeed, how could we understand more advanced features without discovering the writing path first?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Apart from changing the plans, I'm also changing the formula. I'll write one blog post about one ACID file format from my list, instead of describing the 3 ones in the single article. I realized that it forced me to skip some details that don't lower the learning curve. To keep the sense of the series, I'll try to publish the related blog posts weekly.
Tables, types, and config
This section is a good way to introduce different types of tables and operations in this framework. Let's start with the tables:
- Copy-on-Write (CoW). It stores the data in Apache Parquet format. Each update creates a new version of the file. Consequently, this type is write-heavy but more optimized for reading.
- Merge-on-Read (MoR). It uses Apache Parquet and Apache Avro to store the data. Each update goes as an Avro row to a delta log file. As a result of this incremental approach, the writing is faster, but the reading might be slower. Slow reading is not a rule because the writers tend to optimize the process by executing compaction that moves delta log changes to the data files.
Regarding the operations:
- Insert. Adds new records to the table by keeping the most optimal size of the files. It might contain duplicates.
- Bulk insert. Has the same semantic as insert but instead of keeping input data in memory to determine the best file size, it performs a more scalable sorting. It's a recommended strategy to initially load the data to a new table, even though the file size semantic is only the best effort.
- Upsert. Similar to insert in terms of file sizing but different in terms of semantics. Upsert inserts new records or updates the existing ones. It leverages the index lookup to determine whether the row is already present.
- Insert overwrite.
- Delete. Removes a particular record with one of 2 available strategies. The first one nullifies all the columns but keeps the record's key, whereas the second deletes the record totally.
- Delete partition. A specification of delete removing all records of a single partition.
- Bootstrap. Creates an Apache Hudi table on top of the existing Apache Parquet dataset without rewriting the data. Instead, it only manages the metadata layer.
These operations don't live alone. Some of them tightly couple to the Hudi configuration properties. Let's start with the easy ones:
- hoodie.datasource.write.operation - here you define the type of the write operation. You'll find all supported keys in the WriteOperationType enum.
- hoodie.datasource.write.table.type - here you set the type (MoR or CoW) of the table. Again, Hudi defines then in an enum, this time it's HoodieTableType.
- hoodie.datasource.write.table.name - a string representing the name of the written table.
- hoodie.datasource.hive_sync.enable - a boolean flag to enable the synchronization of an Apache Hudi table with Hive metastore. Setting it to true won't probably enough because the configuration supports many other entries to set up the metastore address.
- hoodie.datasource.write.drop.partition.columns - a boolean property to enable dropping the partition column from the saved dataset.
- hoodie.datasource.write.reconcile.schema - a boolean flag to enable or disable the schema reconciliation. The reconciliation consists of adding missing columns with their default values, from the new schema to the written records. Otherwise, the writing operation will fail because of the lack of new columns in the written dataset.
And to complete the list, some of more advanced concepts:
- hoodie.datasource.write.recordkey.field - defines the recordKey property of the HoodieKey. Each Hudi row has some metadata associated. One of them is the HoodieKey composed of the recordKey and partition path, both being the properties you can see in the table displayed with Apache Spark's show() command, like in the snippet below:
+------------------+----------------------+---+------+-------+ |_hoodie_record_key|_hoodie_partition_path|id |amount|title | +------------------+----------------------+---+------+-------+ |3 | |3 |122.0 |Order#3| +------------------+----------------------+---+------+-------+
- hoodie.datasource.write.keygenerator.class - defines the class generating the record key. The implementation must respect the contract from the org.apache.hudi.keygen.KeyGenerator interface. By default, it'll get the key from Java's toString() method.
- hoodie.datasource.write.partitionpath.field - sets the path to the partition attribute.
- hoodie.datasource.write.hive_style_partitioning - a boolean flag to enable Hive-like partitioning mode where the partition path contains the partition attribute and value. If false, Hudi will use its own partitioning strategy where the path contains the partition value only.
- hoodie.datasource.write.precombine.field - defines the field used in the conflicts resolution. If 2 records share the same key, the writer choses the one having the larger precombine field.
- hoodie.datasource.write.row.writer.enable - writes the data with Apache Spark's Row format. To understand the feature, let's back to the 0.6 release. Before that version, while writing data in the columnar format, Apache Hudi was converting the data to Apache Avro, and only later to Apache Parquet. With the introduction of this configuration, the intermediary Avro step is no longer necessary.
Unfortunately, all the above are not the single writing-related options. These are the most important ones (subjectively speaking) I found in the DataSourceWriteOptions.
MoR vs. CoW tables
The difference between the CoW and MoR tables is where updated rows are going. CoW tables append these records to the data blocks while the MoR ones add them to the special delta log file.
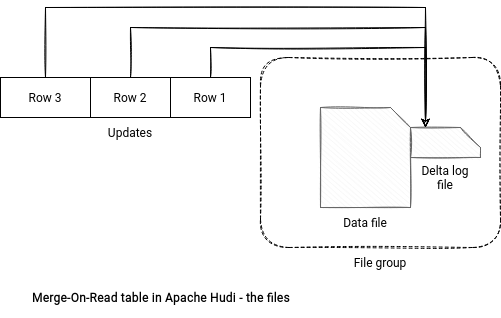
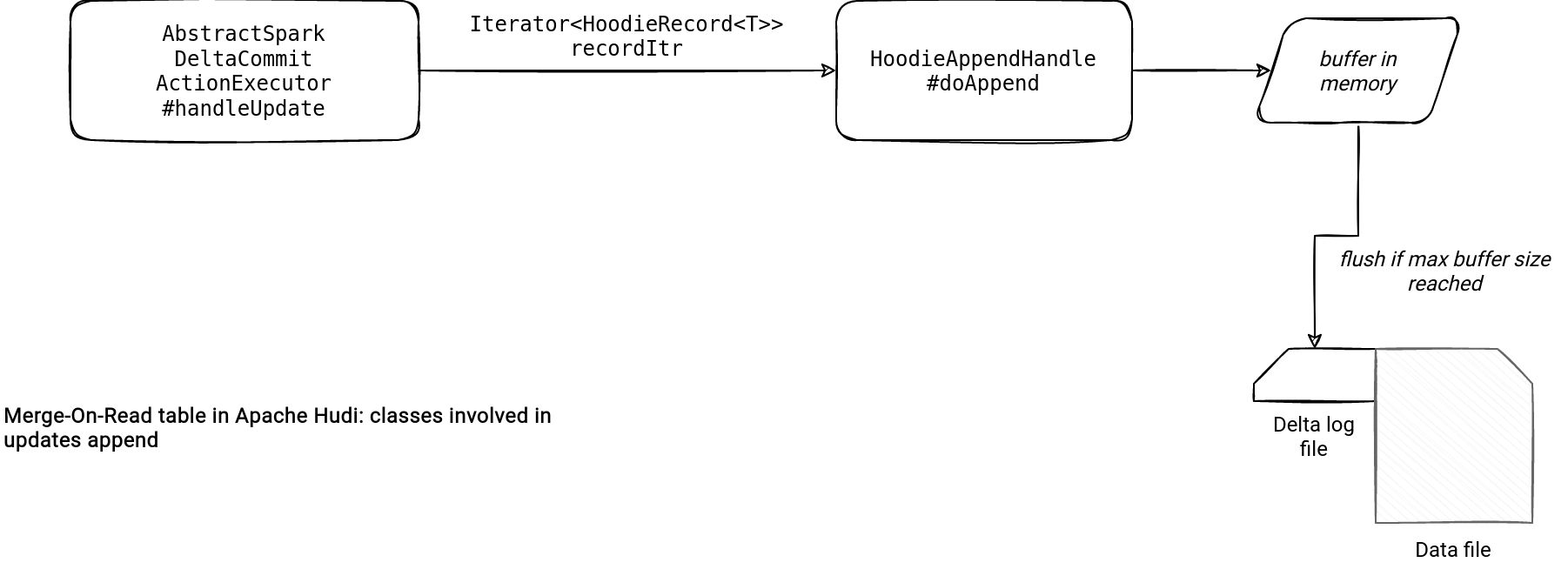
That's the info. Regarding the implementation details, the magic happens in the HoodieAppendHandle class:
public class HoodieAppendHandle<T extends HoodieRecordPayload, I, K, O> extends HoodieWriteHandle<T, I, K, O> {
private Writer createLogWriter(Option<FileSlice> fileSlice, String baseCommitTime)
throws IOException, InterruptedException {
Option<HoodieLogFile> latestLogFile = fileSlice.get().getLatestLogFile();
return HoodieLogFormat.newWriterBuilder()
.onParentPath(FSUtils.getPartitionPath(hoodieTable.getMetaClient().getBasePath(), partitionPath))
.withFileId(fileId).overBaseCommit(baseCommitTime)
.withLogVersion(latestLogFile.map(HoodieLogFile::getLogVersion).orElse(HoodieLogFile.LOGFILE_BASE_VERSION))
.withFileSize(latestLogFile.map(HoodieLogFile::getFileSize).orElse(0L))
.withSizeThreshold(config.getLogFileMaxSize()).withFs(fs)
.withRolloverLogWriteToken(writeToken)
.withLogWriteToken(latestLogFile.map(x -> FSUtils.getWriteTokenFromLogPath(x.getPath())).orElse(writeToken))
.withFileExtension(HoodieLogFile.DELTA_EXTENSION).build();
}
The class creates a log writer that adds a list of HoodieLogBlock to the file. The updates are buffered in memory and materialized whenever their size is bigger than the allowed block size specified in the hoodie.logfile.data.block.max.size configuration.
Row writer
The CoW vs. MoR difference is not the single Hudi writing specificity, though. Another one is the Row-based writer mentioned in the configuration section. When you perform a bulk insert with this optimization enabled, Apache Hudi will bypass the usual writing path and use this shortcut:
object HoodieSparkSqlWriter {
// ...
def bulkInsertAsRow(// ...
{
val hoodieDF = if (populateMetaFields) {
HoodieDatasetBulkInsertHelper.prepareHoodieDatasetForBulkInsert(sqlContext, writeConfig, df, structName, nameSpace,
bulkInsertPartitionerRows, isGlobalIndex, dropPartitionColumns)
} else {
HoodieDatasetBulkInsertHelper.prepareHoodieDatasetForBulkInsertWithoutMetaFields(df)
}
if (SPARK_VERSION.startsWith("2.")) {
hoodieDF.write.format("org.apache.hudi.internal")
.option(DataSourceInternalWriterHelper.INSTANT_TIME_OPT_KEY, instantTime)
.options(params)
.mode(SaveMode.Append)
.save()
} else if (SPARK_VERSION.startsWith("3.")) {
hoodieDF.write.format("org.apache.hudi.spark3.internal")
.option(DataSourceInternalWriterHelper.INSTANT_TIME_OPT_KEY, instantTime)
.option(HoodieInternalConfig.BULKINSERT_INPUT_DATA_SCHEMA_DDL.key, hoodieDF.schema.toDDL)
.options(params)
.mode(SaveMode.Append)
.save()
Wait, is it a shortcut and not a usual writing path? Yes, it is. Usually, Hudi writes the records with extra conversion steps:
- For each input row create an Apache Avro GenericRecord. In the end, it returns an RDD[GenericRecord].
- Map the GenericRecords to HoodieRecords. This step includes an optional deduplication (combination, hence the combine parameter in the config).
- Writes the record to the data files with one of the supported HoodieFileWriters (Parquet, ORC, HFile).
As you can notice, having these 3 steps for a bulk insert which is meant to be a big volume data ingestion, would be inefficient. According to the AWS benchmark, using Row-based bulk insert is 3 times faster than the classical writing path.
Balanced writes
The last thing that caught my attention is the files sizing. Apache Hudi tries to create balanced files to avoid bad input layout situations like data skew or small files. How? With a special construct called WorkloadProfile.
A WorkloadProfile is a class storing the load for each partition (number of insert and updates) and created directly before writing the input rows to the data blocks, here:
public abstract class BaseSparkCommitActionExecutor<T extends HoodieRecordPayload> // ...
{
@Override
public HoodieWriteMetadata> execute(JavaRDD> inputRecordsRDD) {
// ...
WorkloadProfile profile = null;
if (isWorkloadProfileNeeded()) {
context.setJobStatus(this.getClass().getSimpleName(), "Building workload profile");
profile = new WorkloadProfile(buildProfile(inputRecordsRDD), operationType);
LOG.info("Workload profile :" + profile);
saveWorkloadProfileMetadataToInflight(profile, instantTime);
}
// ...
The isWorkloadProfileNeeded conditional is a bit misleading in the current (0.10.0) version because it always returns true. The buildProfile method consists of running an RDD-based processing counting global and partition-based stats. Below, the Spark computation used in the method:
private Pair<HashMap<String, WorkloadStat>, WorkloadStat> buildProfile(JavaRDD<HoodieRecord<T>> inputRecordsRDD) {
HashMap<String, WorkloadStat> partitionPathStatMap = new HashMap<>();
WorkloadStat globalStat = new WorkloadStat();
// group the records by partitionPath + currentLocation combination, count the number of
// records in each partition
Map<Tuple2<String, Option<HoodieRecordLocation>>, Long> partitionLocationCounts = inputRecordsRDD
.mapToPair(record -> new Tuple2<>(
new Tuple2<>(record.getPartitionPath(), Option.ofNullable(record.getCurrentLocation())), record))
.countByKey();
// ..
The profiling is only one part of the file balancing feature. The other one is the partitioner. Just after creating the workload profiles, Hudi gets a corresponding Apache Spark partitioner. As of this writing, the default partitioner for both insert and upsert actions is UpsertPartitioner (CoW table), or SparkUpsertDeltaCommitPartitioner (MoR table). This partitioner is used as a part of partition(...) method where Hudi uses one of Apache Spark's repartitioning to evenly balance the records across the input partitions:
private JavaRDD<HoodieRecord<T>> partition(JavaRDD<HoodieRecord<T>> dedupedRecords, Partitioner partitioner) {
JavaPairRDD<Tuple2<HoodieKey, Option<HoodieRecordLocation>>, HoodieRecord<T>> mappedRDD = dedupedRecords.mapToPair(
record -> new Tuple2<>(new Tuple2<>(record.getKey(), Option.ofNullable(record.getCurrentLocation())), record));
JavaPairRDD<Tuple2<HoodieKey, Option<HoodieRecordLocation>>, HoodieRecord<T>> partitionedRDD;
// ...
if (table.requireSortedRecords()) {
// ...
partitionedRDD = mappedRDD.repartitionAndSortWithinPartitions(partitioner, comparator);
} else {
// Partition only
partitionedRDD = mappedRDD.partitionBy(partitioner);
}
return partitionedRDD.map(Tuple2::_2);
}
The distribution logic is not fully transparent to the end user who can configure the max file size in the hoodie.parquet.max.file.size property.
Even though I haven't planned to write about Apache Hudi (and Apache Iceberg, and Delta Lake) specifically, I'm satisfied with this direction changing. Hopefully by the end of the year I'll be better placed to understand what's going on with these 3 ACID file formats, and hence, explain it better in the blog post and videos. See you in the next part of the series, this time about writes in Apache Iceberg!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about ACID file formats - writing: Apache Hudi here:
Related blog posts:
- ACID file formats - writing: Delta Lake
- ACID file formats - writing: Apache Iceberg
- ACID file formats - file system layout
- ACID file formats - API
I was wrong. Comparing ACID file formats in a single post leads to long and less understandable posts. Now I'm going to split each feature presentation into 3 articles. To start, the writing data part for #ApacheHudi ? https://t.co/8BBKltLvuM
— Bartosz Konieczny (@waitingforcode) June 5, 2022