
Last time you discovered data writing in Apache Hudi. Today it's time to see the 2nd file format from my list, Apache Iceberg.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Operations and configuration
As previously, I'll start this time with some general info first. Since Apache Iceberg doesn't have different table types, let's see the available writing operations:
- Insert, update, merge, and delete. Those are classical DML operations supporting row-level operations, such as deleting a particular item from the dataset by id.
- Insert overwrite. A more advanced insert version that replaces the table. It supports a dynamic and static modes. The former impacts only the rows located in the partition path from the query. The static mode on the other hand, the overwrite must have a PARTITION clause aligned with the query filter. The documentation recommends using MERGE instead of the INSERT OVERWRITE to replace only affected (changed) rows, though.
- Streaming inserts. An insert but executed from Structured Streaming.
- Partition delete. Although it exists as a specialization of the regular DELETE, it's worth a separate mentioning. The partition delete is a metadata-only operation that will not overwrite the data files. Apache Iceberg uses it when the condition from DELETE matches the partition value.
Write configuration properties are defined in TableProperties class as constants prefixed with WRITE_. Again, among subjectively chosen the most important ones, you'll find:
- write.format.default. One of "parquet", "avro", "orc". It defines the table file format.
- write.parquet.row-group-size-bytes, write.parquet.dict-size-bytes, write.parquet.page-size-bytes. Sets respectively, the Parquet row group size, dict size, and page size. They define the storage for the Parquet files composing the table.
- write.target-file-size-bytes. Defines the target size of the generated files.
- write.distribution-mode. Configures the data distribution for the writing step. It can shuffle the data by partition id (good if the partitions are evenly distributed), use range partitioning (good to mitigate data skew), or nothing (good for few partitions, otherwise may lead to small files problem).
- write.metadata.delete-after-commit.enabled, write.metadata.previous-versions-max. Both add an extra step of deleting old metadata information after committing the write. The feature is disabled by default, though.
- write.spark.fanout.enabled. Enables the usage of Apache Spark fanout writer. It's disabled by default. By enabling this property you eliminate the need for the local sort before writing the rows. Instead, the writer keeps one writer open for each partition.
Besides, Apache Iceberg also has some Apache Spark-specific configuration properties for the writer:
- check-nullability. Can be used to enforce null checks on the fields.
- check-ordering. Checks if the input and table schemas are the same.
File writers
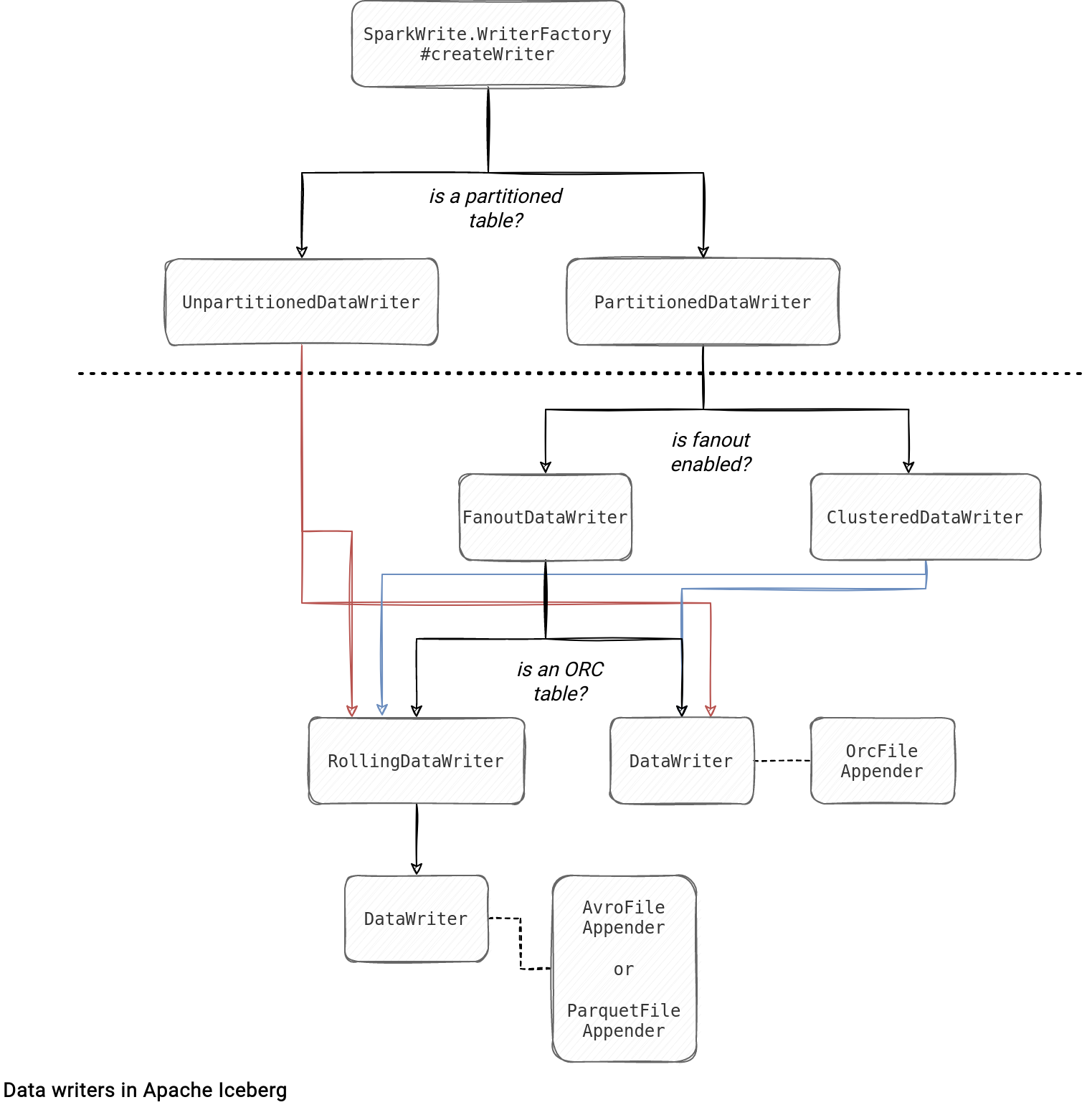
Apache Iceberg writes the data files from one of 4 DataWriter implementations:
- UnpartitionedDataWriter and PartitionedDataWriter. They're high-level data writer abstractions used when the partitioning information is, respectively, missing and present. Both don't perform the physical row writing, though. This task is delegated to a specialized data writer. Instead, they act as wrappers adding an optional partitioning logic.
- FanoutDataWriter. It's a specialization of the PartitionedDataWriter. Its usage is controled by the write.spark.fanout.enabled flag explained before.
- ClusteredDataWriter. When the fanout remains disabled, Apache Iceberg partitioning writer uses the ClusteredDataWriter instance. This writer is more optimal than the FanoutDataWriter in terms of memory usage since it only keeps the writer for one partition open at a time. On the other hand, it's more demanding in CPU since it requires the data to be sorted before writing.
- RollingDataWriter. This one is used for all data formats but ORC when the table is not partitioned. It's also used as a physical writing layer in the FanoutDataWriter. This rolling writer creates a new data file whenever the number of buffered records reaches the targeted threshold from write.target-file-size-bytes.
- DataWriter with OrcFileAppender. It's used when the table format is set to ORC.
Since there is no 1-1 relationship between the high-level and low-level writers, I prepared a summary here:
Metadata delete
Apart from the writing classes, another point from the documentation that spotted my attention was the DELETE operation, and more precisely, its version working on the whole partitions. Why it's so interesting? Because Apache Iceberg can somehow manage this to not overwrite the data files but only the metadata.
Apache Iceberg comes with a set of logical rules and one of them is RewriteDelete. As you might already deduce, it's used to handle Apache Spark's DeleteFromTable command:
case class RewriteDelete(spark: SparkSession) extends Rule[LogicalPlan] with RewriteRowLevelOperationHelper {
override def apply(plan: LogicalPlan): LogicalPlan = plan transform {
// don't rewrite deletes that can be answered by passing filters to deleteWhere in SupportsDelete
case d @ DeleteFromTable(r: DataSourceV2Relation, Some(cond))
if isMetadataDelete(r, cond) && isIcebergRelation(r) =>
d
// rewrite all operations that require reading the table to delete records
case DeleteFromTable(r: DataSourceV2Relation, Some(cond)) if isIcebergRelation(r) =>
// TODO: do a switch based on whether we get BatchWrite or DeltaBatchWrite
The key for understanding the metadata delete is this isMetadataDelete method that checks whether the delete query contains exactly one condition for the partition. Besides, the comments come from the original codebase and are pretty self-explanatory! When the delete doesn't target the partition, hence is not a metadata-delete, this logical rule rewrites the plan to something like that:
ReplaceData IcebergBatchWrite(table=local.db.letters, format=PARQUET), org.apache.spark.sql.execution.datasources.v2.ExtendedDataSourceV2Strategy$$Lambda$2737/229014598@5d2bc446
+- *(4) Project [id#26, upperCase#27, lowerCase#28, nestedLetter#29, creationTime#30]
+- *(4) Sort [_file#43 ASC NULLS FIRST, _pos#44L ASC NULLS FIRST], false, 0
+- *(4) Filter NOT ((isnotnull(lowerCase#28) AND (lowerCase#28 = xx)) <=> true)
+- DynamicFileFilterExec[id#26, upperCase#27, lowerCase#28, nestedLetter#29, creationTime#30, _file#43, _pos#44L]
:- *(1) Project [id#26, upperCase#27, lowerCase#28, nestedLetter#29, creationTime#30, _file#43, _pos#44L]
: +- ExtendedBatchScan[id#26, upperCase#27, lowerCase#28, nestedLetter#29, creationTime#30, _file#43, _pos#44L] local.db.letters [filters=lowerCase IS NOT NULL, lowerCase = 'xx']
+- *(3) HashAggregate(keys=[_file#43], functions=[], output=[_file#43])
+- Exchange hashpartitioning(_file#43, 200), ENSURE_REQUIREMENTS, [id=#62]
+- *(2) HashAggregate(keys=[_file#43], functions=[], output=[_file#43])
+- *(2) Project [_file#43]
+- *(2) Filter (isnotnull(lowerCase#28) AND (lowerCase#28 = xx))
+- ExtendedBatchScan[id#26, upperCase#27, lowerCase#28, nestedLetter#29, creationTime#30, _file#43, _pos#44L] local.db.letters [filters=lowerCase IS NOT NULL, lowerCase = 'xx']
As you can see, the process eliminates the rows matching the filter from the files containing removed rows. The plan for the metadata delete is much simpler:
== Physical Plan == DeleteFromTable local.db.letters, [IsNotNull(upperCase), EqualTo(upperCase,B)], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2582/830929141@467cd4b9
It follows the classical Apache Spark delete path from the DeleteFromTableExec:
case class DeleteFromTableExec(table: SupportsDelete, condition: Array[Filter], refreshCache: () => Unit) extends V2CommandExec {
override protected def run(): Seq[InternalRow] = {
table.deleteWhere(condition)
refreshCache()
Seq.empty
}
The table implementation is SparkTable and it invokes the following to delete the files:
@Override
public class SparkTable implements org.apache.spark.sql.connector.catalog.Table,
SupportsRead, SupportsWrite, ExtendedSupportsDelete, SupportsMerge {
public void deleteWhere(Filter[] filters) {
// ...
icebergTable.newDelete()
.set("spark.app.id", sparkSession().sparkContext().applicationId())
.deleteFromRowFilter(deleteExpr)
.commit();
In this deleteFromRowFilter, Apache Iceberg creates an instance of PartitionAndMetricsEvaluator and checks whether the rows from each evaluated data file match the filtering expression which in our case, is the condition on the partitioning column. If the outcome is true, Apache Iceberg filters out the data file from the generated manifest without currently touching this data file physically. It's just a metadata marker saying that the readers shouldn't see the records from these files.
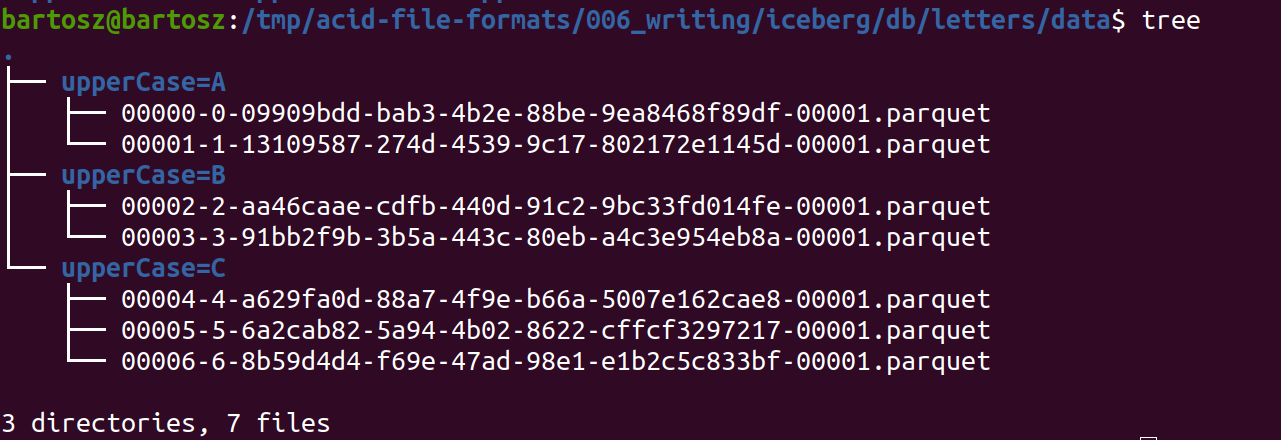
To confirm my sayings, below you can find an example of the manifest created after the partition delete operation (I removed the stats part for readability):
{
"status" : 0,
"snapshot_id" : 2113420582962524200,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=A/00000-0-09909bdd-bab3-4b2e-88be-9ea8468f89df-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "A"
},
"record_count" : 1,
"file_size_in_bytes" : 1835,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 0,
"snapshot_id" : 2113420582962524200,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=A/00001-1-13109587-274d-4539-9c17-802172e1145d-00001.parquet",
"file_format" : "PARQUET",
"partition" : {icon expand},
"record_count" : 1,
"file_size_in_bytes" : 1842,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 2,
"snapshot_id" : 6974932437942515000,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=B/00002-2-aa46caae-cdfb-440d-91c2-9bc33fd014fe-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "B"
},
"record_count" : 1,
"file_size_in_bytes" : 1835,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 2,
"snapshot_id" : 6974932437942515000,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=B/00003-3-91bb2f9b-3b5a-443c-80eb-a4c3e954eb8a-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "B"
},
"record_count" : 1,
"file_size_in_bytes" : 1842,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 0,
"snapshot_id" : 2113420582962524200,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=C/00004-4-a629fa0d-88a7-4f9e-b66a-5007e162cae8-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "C"
},
"record_count" : 1,
"file_size_in_bytes" : 1835,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 0,
"snapshot_id" : 2113420582962524200,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=C/00005-5-6a2cab82-5a94-4b02-8622-cffcf3297217-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "C"
},
"record_count" : 1,
"file_size_in_bytes" : 1841,
"block_size_in_bytes" : 67108864
}
}
{
"status" : 0,
"snapshot_id" : 2113420582962524200,
"data_file" : {
"file_path" : "file:/tmp/acid-file-formats/006_writing/iceberg/db/letters/data/upperCase=C/00006-6-8b59d4d4-f69e-47ad-98e1-e1b2c5c833bf-00001.parquet",
"file_format" : "PARQUET",
"partition" : {
"upperCase" : "C"
},
"record_count" : 1,
"file_size_in_bytes" : 1849,
"block_size_in_bytes" : 67108864
}
}
The key part is the status attribute defined in org.apache.iceberg.ManifestEntry.Status as:
public static enum Status {
EXISTING(0),
ADDED(1),
DELETED(2);
// ...
}
And the tree output for the data files (deleted partition was "B", and the data is still there):
Distribution mode
To finish investigating the interesting internals of Apache Iceberg writers, I had to understand what the write.distribution-mode is for. The first thing to notice, it only works if the table is partitioned. Below you can see a method mapping the table distribution:
public static Distribution buildRequiredDistribution(org.apache.iceberg.Table table) {
DistributionMode distributionMode = distributionModeFor(table);
switch (distributionMode) {
case NONE:
return Distributions.unspecified();
case HASH:
if (table.spec().isUnpartitioned()) {
return Distributions.unspecified();
} else {
return Distributions.clustered(toTransforms(table.spec()));
}
case RANGE:
if (table.spec().isUnpartitioned() && table.sortOrder().isUnsorted()) {
return Distributions.unspecified();
} else {
org.apache.iceberg.SortOrder requiredSortOrder = SortOrderUtil.buildSortOrder(table);
return Distributions.ordered(convert(requiredSortOrder));
}
default:
throw new IllegalArgumentException("Unsupported distribution mode: " + distributionMode);
}
}
A partitioned table is a requirement, but what is this distribution mode? At first I thought it was a kind of bucketing-like feature of Iceberg, but it doesn't make sense since the partitioning already defines how the records are colocated. Moreover, you won't find a mention of it during the inserts. It's a table-based property you can set like me just below:
sparkSession.sql(
s"""
|CREATE OR REPLACE TABLE local.db.letters_hash (
| id INT,
| upperCase STRING,
| lowerCase STRING
|)
|USING iceberg
|PARTITIONED BY (upperCase)
|TBLPROPERTIES('write.distribution-mode' = 'hash')
|""".stripMargin)
If this table property is not used in the inserts, then when? The answer is, in the row-level operations, such as update, delete [not partition delete], and merge. In the code you will find its mention in the RewriteRowLevelOperationHelper implementations which are RewriteDelete, RewriteUpdate, and RewriteMerge. They're logical rules that replace the initial Apache Spark plan by, among others, including the shuffling corresponding to the distribution mode. Need a proof? Below you can find execution plans for MERGE operation for 3 different scenarios where the distribution is respectively set to none, hash, and range:
- NONE. Nothing changes, the plan is a simple join with data append:
== Physical Plan == AppendData local.db.letters_none, [], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2306/1342257685@29c21acb +- *(2) Sort [upperCase#37 ASC NULLS FIRST], false, 0 +- *(2) BroadcastHashJoin [id#36], [id#33], LeftAnti, BuildRight, false :- *(2) Project [id#36, upperCase#37, lowerCase#38] : +- BatchScan[id#36, upperCase#37, lowerCase#38] local.db.letters [filters=] +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#52] +- *(1) Project [id#33] +- *(1) Filter isnotnull(id#33) +- BatchScan[id#33, upperCase#34, lowerCase#35, _file#44, _pos#45L] local.db.letters_none [filters=] - HASH. Here, the plan is different. It has an extra shuffle step on the partition column (upperCase):
== Physical Plan == AppendData local.db.letters_hash, [], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2306/1342257685@1dae9e61 +- *(3) Sort [upperCase#84 ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(upperCase#84, 200), REPARTITION, [id=#124] +- *(2) BroadcastHashJoin [id#83], [id#80], LeftAnti, BuildRight, false :- *(2) Project [id#83, upperCase#84, lowerCase#85] : +- BatchScan[id#83, upperCase#84, lowerCase#85] local.db.letters [filters=] +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#120] +- *(1) Project [id#80] +- *(1) Filter isnotnull(id#80) +- BatchScan[id#80, upperCase#81, lowerCase#82, _file#91, _pos#92L] local.db.letters_hash [filters=]
It's worth mentioning that the partition column is not used in the MERGE statement at all!sparkSession.sql( s""" |MERGE INTO local.db.letters_hash lmode |USING (SELECT * FROM local.db.letters) l |ON lmode.id = l.id |WHEN NOT MATCHED THEN INSERT * |""".stripMargin) - RANGE. Here too, the plan contains an extra repartitioning step. Unlike previously for the hash distribution, it uses range partitioning:
== Physical Plan == AppendData local.db.letters_range, [], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$2306/1342257685@21262bde +- *(3) Sort [upperCase#131 ASC NULLS FIRST], false, 0 +- Exchange rangepartitioning(upperCase#131 ASC NULLS FIRST, 200), REPARTITION, [id=#195] +- *(2) BroadcastHashJoin [id#130], [id#127], LeftAnti, BuildRight, false :- *(2) Project [id#130, upperCase#131, lowerCase#132] : +- BatchScan[id#130, upperCase#131, lowerCase#132] local.db.letters [filters=] +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [id=#191] +- *(1) Project [id#127] +- *(1) Filter isnotnull(id#127) +- BatchScan[id#127, upperCase#128, lowerCase#129, _file#138, _pos#139L] local.db.letters_range [filters=]
After writing this blog post I appreciate even more the idea of changing the blog format and instead of covering one aspect from a high level, getting down to finer level of details. Even though I'm aware there are certainly some other interesting writing aspects to cover! If you have something in mind, please leave a comment below to complete the article. And meantime, see you next week, this time with Delta Lake writing logic.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about ACID file formats - writing: Apache Iceberg here:
- DistributionMode Implement spark fanout writer #1746 Is it better to have one large parquet file or lots of smaller parquet files?
Related blog posts:
- ACID file formats - writing: Delta Lake
- ACID file formats - writing: Apache Hudi
- ACID file formats - file system layout
- ACID file formats - API
It's time to present the writing part for the second analyzed ACID file format which is #ApacheIceberg . A general introduction with a deeper look at 2 features are in this blog post ? https://t.co/IMqJxielKW
— Bartosz Konieczny (@waitingforcode) June 12, 2022