
It's time for the last data generation part of the ACID file formats series. This time we'll see how Delta Lake writes new files.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Operations and options
Among the DML operations, Delta Lake supports:
- Inserts. It's a classic operation among all the supported ACID file formats but with an interesting constraints support. While you create a new table, you can add a CONSTRAINT rule that will prevent from adding the rows breaking the condition.
- Updates.
- Deletes. Both deletes in place as well as overwrite deletes which by the way, are a recommended way to clear up the whole table. This operation doesn't work on the files but only at the metadata level. Moreover, it's an atomic operation that can be reverted to one of the previous valid versions.
- Merges.
The writing process might look easy but despite this apparency, Delta Lake has some specific writing configuration entries:
- dataChange. This boolean flag determines whether the processed data is new and should be included in the streaming data source. For example, if you want to repartition the dataset only, setting dataChange to false will avoid the reprocessing on the streaming side. Delta Lake uses it in the DeltaSource#verifyStreamHygieneAndFilterAddFiles to get only the new files for the streaming reader.
- userMetadata. It defines extra information added to the commit. It's always a text without a native data processing capability.
- replaceWhere. It adds an extra constraint on the rewritten rows. The whole input DataFrame must comply with this constraint. Otherwise, Delta Lake will throw a CHECK constraint EXPRESSION(...) violated by row with values error.
- optimizeWrite. It's present in the options list in DeltaWriteOptions but seems to be implemented in the Databricks Delta Lake only. For now, there are some plans to include it in the vanilla Delta Lake by leveraging the Adaptive Query Execution engine to reduce the number of generated files. Stay tuned!
Additionally to these writing parameters, you will find writing configuration entries in the DeltaSQLConfBase:
- spark.databricks.delta.stats.collect. The flag enables statistics collection while writing Delta Lake files, such as {"numRecords":31,"minValues" {"id":0,"multiplication_result":0},"maxValues" {"id":30,"multiplication_result":60},"nullCount":{"id":0,"multiplication_result":0}}.
- spark.databricks.delta.stats.skipping. It's a boolean flag enabling statistics-based data skipping. If disabled, Delta Lake will be unable to get files statistics and use them in the filtering clause.
- spark.databricks.delta.merge.optimizeInsertOnlyMerge.enabled. An optimization strategy for the MERGE operation that will avoid rewriting old files and generate only the new ones for a special insert-only merge type. It's enabled by default and marked as "internal" configuration.
- spark.databricks.delta.replaceWhere.dataColumns.enabled. This flag enables arbitrary predicates in the replaceWhere option. If disabled, the condition accepts only partitioning columns and you will get an error like Predicate references non-partition column '...'. Only the partition columns may be referenced.
- spark.databricks.delta.replaceWhere.constraintCheck.enabled. By default, the replaceWhere only accepts the DataFrame that matches the predicate. You can change this behavior by turning this constraintCheck option to false.
Data skipping
The first intriguing feature is data skipping. As you already know from the previous section, Delta Lake collects several statistics about the generated files. And they have an important role for the in-place operations. To understand why let's see what happens if they're missing and we want to delete the rows matching a predicate:
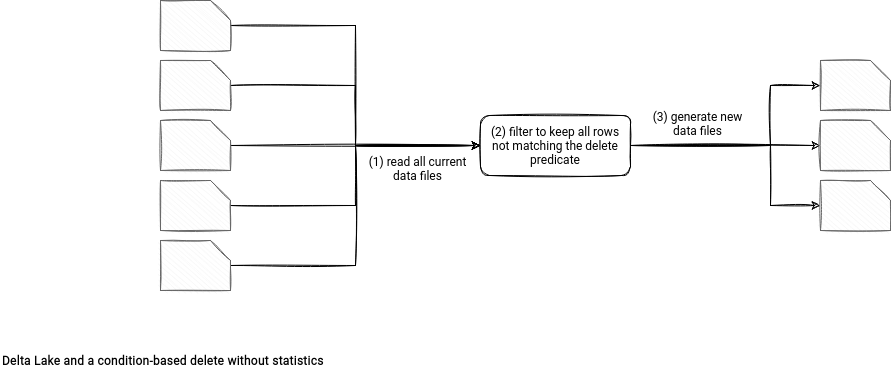
An optimized version uses data skipping to avoid reading the data files not matching the delete condition. How? When the spark.databricks.delta.stats.collect flag is enabled, Delta Lake writers generate additional statistics for each data file by using a new DeltaJobStatisticsTracker instance. The tracker is a factory class exposing 2 methods:
class DeltaJobStatisticsTracker // ...
var recordedStats: Map[String, String] = _
override def newTaskInstance(): WriteTaskStatsTracker = {
val rootPath = new Path(rootUri)
val hadoopConf = srlHadoopConf.value
new DeltaTaskStatisticsTracker(dataCols, statsColExpr, rootPath, hadoopConf)
}
override def processStats(stats: Seq[WriteTaskStats], jobCommitTime: Long): Unit = {
recordedStats = stats.map(_.asInstanceOf[DeltaFileStatistics]).flatMap(_.stats).toMap
}
The newTaskInstance method gets invoked when data writers put the input rows to the files. The returned DeltaTaskStatisticsTracker instance exposes 2 important stats tracking methods:
class DeltaTaskStatisticsTracker // ... override def newFile(newFilePath: String): Unit override def newRow(filePath: String, currentRow: InternalRow): Unit
The newFile creates a stats tracking buffer for the file generated in the writing task and passed as parameter. Later on, whenever a row is written to this file, the data writer calls the newRow function that loads the stats buffer and updates the statistic values for all the columns.
Once the file gets all the writes, the writer task calls the DeltaTaskStatisticsTracker#closeFile(filePath: String) function that computes the final statistics and puts them to the results = new collection.mutable.HashMap[String, String] map as a JSON. Once all tasks terminate, the transaction adds the statistics to the commit log.
Now comes the reading. The overall flow uses an extra step summarized in the updated reading schema:
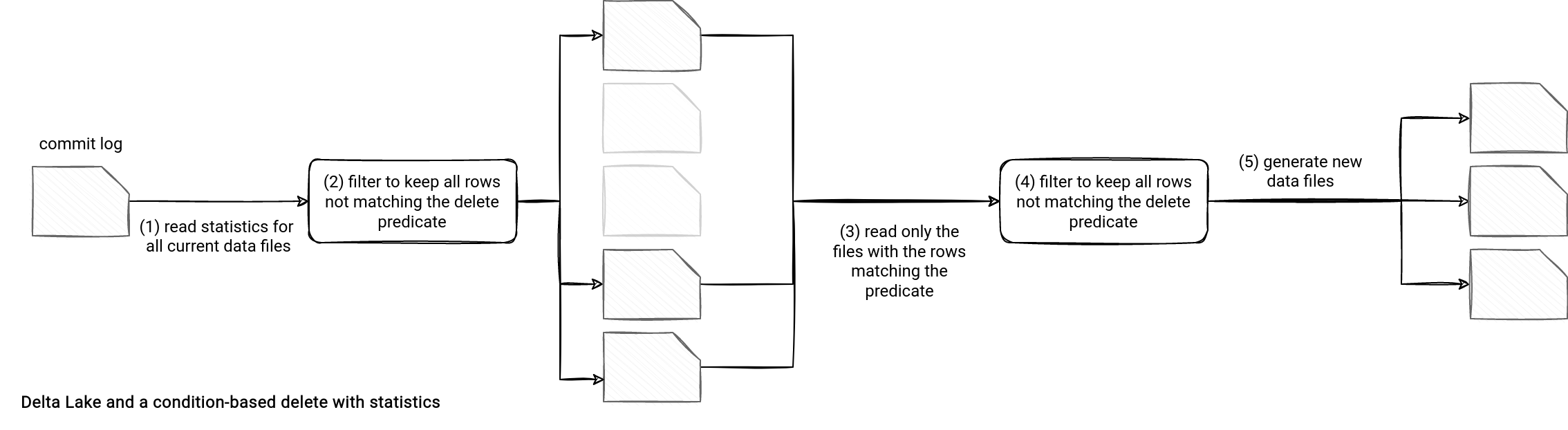
Let's see this feature in action for a query replacing the files matching a predicate from the replaceWith action. When it happens, Delta Lake performs a DeleteCommand that calls the OptimisticTransactionImpl#filterFiles(filters: Seq[Expression]) under-the-hood. This filterFiles method uses DataSkippingReader#filesForScan method to get the files matching the predicate filter and put them to the reading index. While the execution of this delete step, the task knows the files to rewrite and can do this without processing the whole table. Since this part concerns the reading, I'll focus on it more next time.
String statistics
Additionally to the classic statistics for numerical values, Delta Lake also supports strings. The file format stores a string prefix in the data skipping index. The prefix length definition depends on the spark.databricks.io.skipping.stringPrefixLength configuration entry.
For example, the following dataset with stringPrefixLength set to 2 will store the max value only up to 2 characters:
val inputData = (0 to 30).map(nr => (nr, nr*2, (0 to nr).mkString("")))
.toDF("id", "multiplication_result", "concat_numbers")
And the stats:
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|path |stats |
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|part-00000-3dfc3c2d-fc13-4b64-92ce-c65486ea3a56-c000.snappy.parquet|{"numRecords":31,"minValues":{"id":0,"multiplication_result":0,"concat_numbers":"0"},"maxValues":{"id":30,"multiplication_result":60,"concat_numbers":"01�"},"nullCount":{"id":0,"multiplication_result":0,"concat_numbers":0}}|
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
On the other hand, increasing the prefix length to 20 will keep fine-grained statistics for the single text field of the input:
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|path |stats |
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|part-00000-fa3c14d4-3180-40cf-aabc-8b49c0ef616a-c000.snappy.parquet|{"numRecords":31,"minValues":{"id":0,"multiplication_result":0,"concat_numbers":"0"},"maxValues":{"id":30,"multiplication_result":60,"concat_numbers":"01234567891011121314�"},"nullCount":{"id":0,"multiplication_result":0,"concat_numbers":0}}|
+-------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Partition delete
Delta Lake also supports partition-based operations. It means that in case of a delete or update involving the whole partition, Delta Lake doesn't need to open each file and find the matching rows - even with the statistics enabled! Instead, it simply takes all the files from the partition and marks them as deleted in the commit log.
The key moment of this operation is the classification of the predicates as the data and metadata conditions. The method involved is:
object DeltaTableUtils extends PredicateHelper with DeltaLogging {
def isPredicateMetadataOnly(
condition: Expression,
partitionColumns: Seq[String],
spark: SparkSession): Boolean = {
isPredicatePartitionColumnsOnly(condition, partitionColumns, spark) &&
!containsSubquery(condition)
}
Whenever the filters contain only the partitioning column, it's classified as a metadata-only predicate. The DeltaLog#filterFileList employed in the data skipping, can use this filter to extract the files modified by the partition operation only.
On the other hand, the operation with a data filter does modify the data and doesn't use data skipping. The physical plan for this scenario looks like that:
== Physical Plan ==
*(1) Filter UDF()
+- *(1) Filter NOT ((id#636 > 3) <=> true)
+- *(1) ColumnarToRow
+- FileScan parquet [id#636,multiplication_result#637,is_even#638] Batched: true, DataFilters: [NOT ((id#636 > 3) <=> true)], Format: Parquet, Location: TahoeBatchFileIndex(1 paths)[file:/tmp/acid-file-formats/002_writing/delta_lake], PartitionFilters: [], PushedFilters: [], ReadSchema: struct
In the end, the DataFrame is materialized to Parquet files, the new files are added to the commit log and the old ones marked as deleted.
dataChange
The last discussed option, the dataChange option looks inoffensive at first glance. Just a flag to mark an operation as changing the underlying data. However, semantically speaking, it's not as easy.
Let's take an example of the DELETE operation. As you saw in the previous section, it does change the data, so logically the dataChange flag should be set to true. But from the streaming standpoint, this change only involves deleting something already processed. What should be the value of dataChange?
Tathagata Das sheds some light on a possible solution in Should the AddFiles from DELETE have dataChange=true? issue. He recommends using Change Data Feed to catch only the changed rows without compromising the dataChange purpose.
And here we are! The writing part of the 3 ACID file formats ends with this Delta Lake presentation. Next time you'll learn about reading, and this time, I will start by the reverse lexicographical order, so by Delta Lake!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- ACID file formats - writing: Apache Iceberg
- ACID file formats - writing: Apache Hudi
- ACID file formats - file system layout
- ACID file formats - API
The last chapter for the writing in ACID file formats series is online. This time, you can learn about #DeltaLake data generation options, data skipping, and metadata operations ? https://t.co/A3kJj9OD46
— Bartosz Konieczny (@waitingforcode) June 19, 2022