
Last week I presented the API of the 3 analyzed ACID file formats. Under-the-hood, they obviously generate data files but not only. And that's something we'll focus on in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The demo code consists of 3 applications manipulating a dataset of Letter(id: String, lowerCase: String):
- The first application creates a dataset composed of Letter("A", "a"), Letter("B", "b"), Letter("C", "c"), Letter("D", "d"), Letter("E", "e").
- The second application updates the "A", deletes the "C" and inserts a Letter("F", "f").
- The last job overwrites the current dataset by Letter("G", "g").
You'll find the code for each file format in the 001_storage_layout module on Github. Instead, I'll dig into the code for the first time to understand the relationship between the stored files and the classes.
Apache Hudi
The files left after running the 3 jobs in Apache Hudi looks like in the following schema:
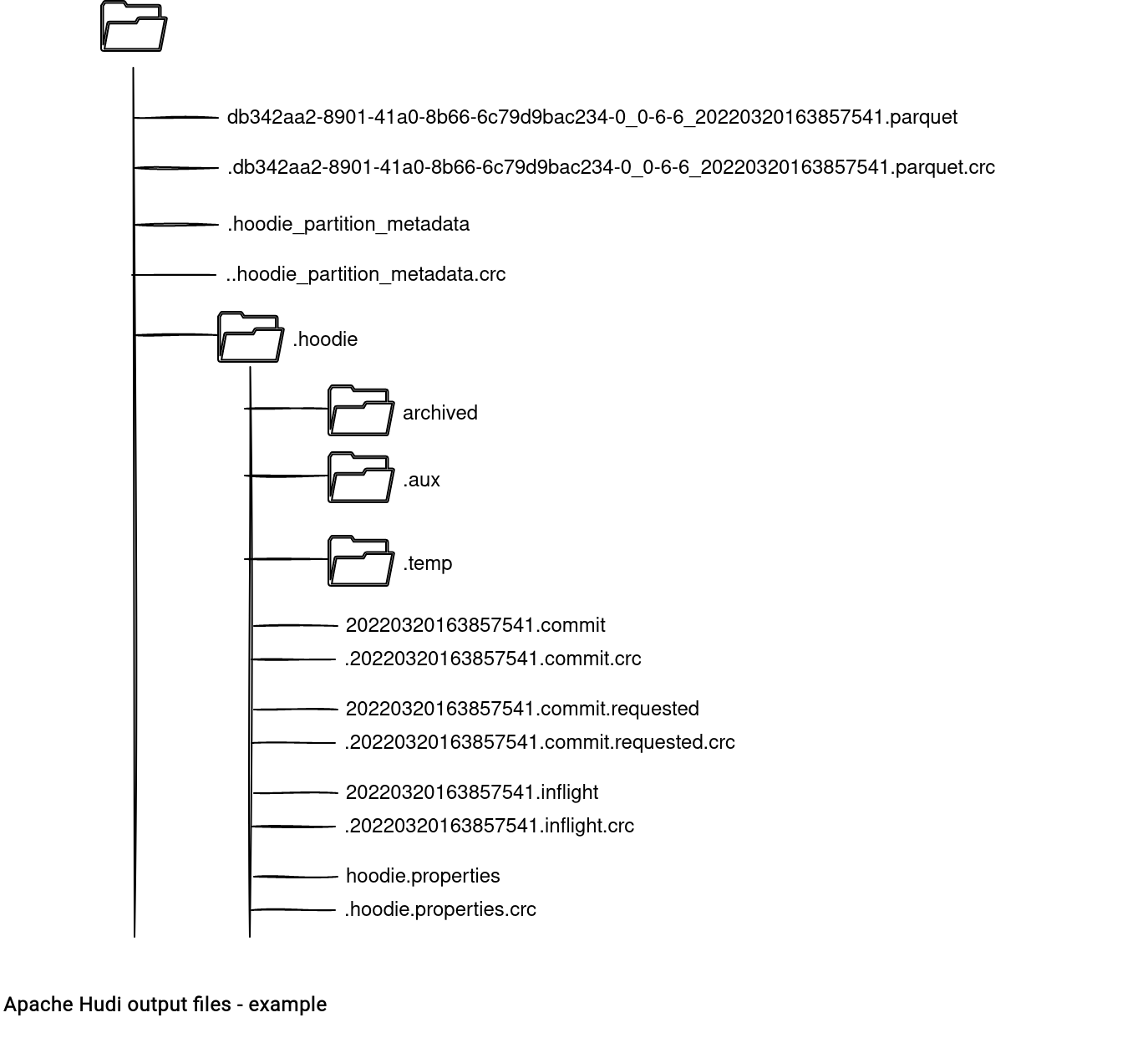
The first interesting file is hoodie_partition.metadata, represented in the code by the HoodiePartitionMetadata class. Apache Hudi creates it for each partition and writes 2 related information:
- the commit time
- the partition depth - in my example I don't use the partitioning, so this value will be 0. Otherwise, this number shows how deep the partition is within the root directory. This information is useful to find the root directory and access the table metadata.
The table metadata is stored under the .hoodie subdirectory, in the hoodie.properties file. The class generating this file is HoodieTableConfig and it defines all the attributes of the table, such as the type (copy on write in the example), storage format (Parquet), name (letters), or the partition fields (missing).
Other interesting files are the ones starting with a timestamp. They're the markers for the actions made on the table:
- 20220320163857541.commit stores a JSON with all parameters related to the successful write operation. Inside you'll find things like the number of written rows, their size, reference to the previous commit, operation type, or the schema of the dataset.
- 20220320163857541.commit.requested is empty and marks the beginning of the commit action.
- 20220320163857541.inflight has a similar structure to the .commit but a lot of attributes are empty. It marks the commit operation as ongoing.
Why these 3 files? They're useful for performing the rollbacks and avoiding doing that with the rename() operation that is not atomic on the object stores. In the code they're defined in the HoodieTimeline and HoodieInstant classes.
The 3 subdirectories from the directory listing are:
- archived is the folder storing the archived timeline instants. The location can be changed in the hoodie.archivelog.folder property.
- .aux is an abbreviation for the auxiliary. It's used to track compaction workloads:
public class HoodieActiveTimeline extends HoodieDefaultTimeline { // ... public void saveToCompactionRequested(HoodieInstant instant, Option<byte[]> content, boolean overwrite) { ValidationUtils.checkArgument(instant.getAction().equals(HoodieTimeline.COMPACTION_ACTION)); // Write workload to auxiliary folder createFileInAuxiliaryFolder(instant, content); createFileInMetaPath(instant.getFileName(), content, overwrite); } - .temp where Hudi creates marker files. Hudi uses marker files to track and automatically delete files generated from uncommitted (failed) transactions.
And these are only the metadata files! Apache Hudi root directory also contains the data files. If you analyze their names, you'll find an interesting pattern. Let's take the example from the directory tree which is db342aa2-8901-41a0-8b66-6c79d9bac234-0_0-6-6_20220320163857541.parquet. The file name is composed as:
- an arbitrary uuid (db342aa2-8901-41a0-8b66-6c79d9bac234) which is the identifier of the file group (note: it's probably a different value if a key is defined), plus the number of files written for the group so far (-0)
- a write token consisting of: task partition id (0), Spark stage id (6), and task attempt id (6)
- the commit time (20220320163857541)
You'll find the information about them in the FSUtils makeWriteToken and makeDataFileName methods.
Apache Iceberg
As you have seen, Apache Hudi has a quite extended directory structure. What about Apache Iceberg? I found the organization a bit simpler because after running the first 2 jobs it looks like that:
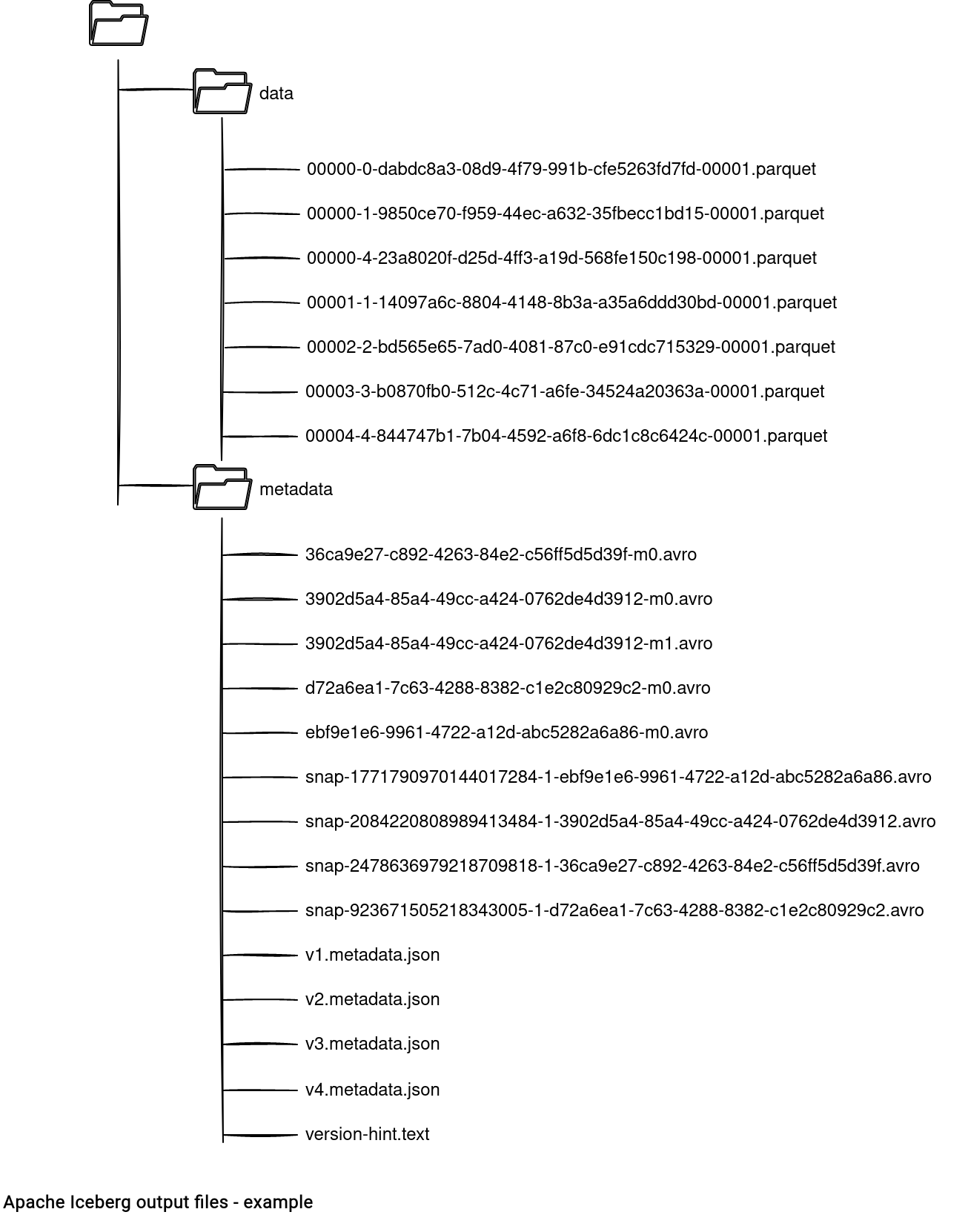
What do we have here? Let me start with the metadata subdirectory where Iceberg stores:
- Vx.metadata.json files. It's Hudi's commit file with the summary information about the writing operation. You'll find here the summar number of written rows, their total size, the schema, but also reference links to the previous metadata files and to the snap files. The full content is available in the TableMetadata and TableMetadataParser classes.
- snap-x.avro files. They're called manifest lists. Apache Iceberg uses them to store the attributes useful to optimize the reading path, like partition value ranges. Each manifest list references manifest files.
- x-mx.avro files. They're manifest files and store more detailed information about the content of each data file. It's a fine grained level view of the table's content up to this version. If we take the example of the partition boundaries, the manifest list stores a summary for these values across all the manifest files. The file is composed of the commit UUID and the number of the manifest file (mx):
abstract class SnapshotProducer<ThisT> implements SnapshotUpdate<ThisT> { // ... protected ManifestWriter<DataFile> newManifestWriter(PartitionSpec spec) { return ManifestFiles.write(ops.current().formatVersion(), spec, newManifestOutput(), snapshotId()); } - version-hint.text file. It's an optional metadata file storing the table's current version number.
Let me terminate by analyzing the data files and more specificaly, the 00003-3-b0870fb0-512c-4c71-a6fe-34524a20363a-00001.parquet. As for Apache Hudi, all Iceberg output files ve a standardized name composed of:
- the partition id (00003). It uses Apache Spark task's partition id under-the-hood which is the id of the RDD partition.
- the task id (3). Technically speaking, it's Apache Spark's task attempt id.
- the operation id (b0870fb0-512c-4c71-a6fe-34524a20363a). It's a unique uuid for each Apache Spark job writing the data files. This information can be useful to detect all files generated by the job.
- the number of so far generated files for the group (00001)
To see the method creating the name for the output files, you can go to OutputFileFactory#generateFilename.
Delta Lake
Delta Lake is the last format to analyse in this article. The output of the first 2 jobs looks like:

The separation is pretty clear. The _delta_log subdirectory is the metadata location storing the commits representing the incremental state of the table. This state lists the added and removed files, persist the protocol information, the schema, and the commit info.
The code's interaction with _delta_log commits mainly involves 2 classes. The first is the OptimisticTransaction that asks for the creation of the the file in the commit method. The second class is LogStore that takes the request and materializes the commit information in the file. Since the LogStore is an interface, the underlying implementation will depend on the file system (local, distributed, object store) used for Delta Lake tables.
When it comes to the data files, they use the same naming mechanism as Apache Spark, so: part- + task attempt id + random UUID + the number of files written so far in the process. The logic naming logic is defined in the DelayedCommitProtocol#getFileName method.
The storage layout for the 3 analyzed file formats is similar. They all consider the datasets in terms of metadata and data. Although the metadata part is mostly responsible for the transactional guarantee, it can also contain some performance tips, such as the partition boundaries in Apache Iceberg. The data files are usually generated in the output root directory (Delta Lake, Apache Hudi) or in a separate subdirectory (Apache Iceberg).
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about ACID file formats - file system layout here:
- [SUPPORT]What does deltacommit.requested,deltacommit.inflight mean Apache Iceberg terms Update version-hint.txt atomically Improving Marker Mechanism in Apache Hudi
Related blog posts:
- ACID file formats - writing: Delta Lake
- ACID file formats - writing: Apache Iceberg
- ACID file formats - writing: Apache Hudi
- ACID file formats - API
After the introductory article from the previous week, it's time to start understanding ACID file formats. In the new blog post you'll find a short analysis of the storage layout ? https://t.co/9pRShUNPo3
— Bartosz Konieczny (@waitingforcode) April 3, 2022