
Some months ago bithw1 posted an interesting question on my Github about multiple SparkSessions sharing the same SparkContext. If you have similar interrogations, feel free to ask - maybe it will give a birth to more detailed post adding some more value to the community. This post, at least, tries to do so by answering the question.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post goes level by level to answer that question. Its first section explains the role of 2 mentioned objects: SparkSession and SparkContext. The second part talks about the possibility to define multiple SparkSession for the same SparkContext while the last tries to give some use cases of it.
SparkSession and SparkContext
To better understand the problem discussed in this post it's important to define what we'll discuss about. The first discussion point is SparkContext. Historically it's an entry point for all Apache Spark pipelines located on the driver. It's a materialized connection to a Spark cluster providing all required abstractions to create RDDs, accumulators and broadcast variables. In our pipeline definition we can only use a single one active SparkContext. Otherwise the framework will throw an Only one SparkContext may be running in this JVM (see SPARK-2243). error. This behavior can change though when we set the spark.driver.allowMultipleContexts configuration flag to true:
"two SparkContexts created with allowMultipleContexts=true" should "work" in {
val sparkConfiguration = new SparkConf().set("spark.driver.allowMultipleContexts", "true")
val sparkContext1 = new SparkContext("local", "SparkContext#1", sparkConfiguration)
val sparkContext2 = new SparkContext("local", "SparkContext#2", sparkConfiguration)
}
"two SparkContexts" should "fail the processing" in {
val exception = intercept[Exception] {
new SparkContext("local", "SparkContext#1")
new SparkContext("local", "SparkContext#2")
}
exception.getMessage should startWith("Only one SparkContext may be running in this JVM (see SPARK-2243)")
}
However having multiple SparkContexts in the same JVM is not considered as a good practice. It's useful for tests execution and it's, by the way, its primary use in Apache Spark library. Outside the test scope, it's not guaranteed that the pipeline will work correctly with multiple active contexts. Besides, it makes the whole data pipeline more difficult to manage. The workflow is not isolated - a potential failure of one context can impact another and even it can break down the whole JVM. It also brings some extra hardware pressure on everything the driver does. Even though we collect a part of data with toLocalIterator (read more in the post Collecting a part of data to the driver with RDD toLocalIterator), it's always multiple times more data to process than with isolated processes.
One of the drawbacks of SparkContext was its specific character regarding the processing context. In order to work with Hive we needed to use HiveContext. If we wanted to deal with structured data the SQLContext instance had to be used. StreamingContext was devoted to streaming applications. That problem was addressed with SparSession which appears as one common entry point for all different pipelines. The instance of SparkSession is constructed with a builder common for all processing types except Hive which requires a call to enableHive() method.
SparkSessions sharing SparkContext
As told previously, having multiple SparkContexts per JVM is technically possible but at the same time it's considered as a bad practice. Apache Spark provides a factory method getOrCreate() to prevent against creating multiple SparkContext:
"two SparkContext created with a factory method" should "not fail" in {
// getOrCreate is a factory method working with singletons
val sparkContext1 = SparkContext.getOrCreate(new SparkConf().setAppName("SparkContext#1").setMaster("local"))
val sparkContext2 = SparkContext.getOrCreate(new SparkConf().setAppName("SparkContext#2").setMaster("local"))
sparkContext1.parallelize(Seq(1, 2, 3))
sparkContext2.parallelize(Seq(4, 5, 6))
sparkContext1 shouldEqual sparkContext2
}
Having multiple SparkSessions is possible thanks to its character. SparkSession is a wrapper for SparkContext. The context is created implicitly by the builder without any extra configuration options:
"Spark" should "create 2 SparkSessions" in {
val sparkSession1 = SparkSession.builder().appName("SparkSession#1").master("local").getOrCreate()
val sparkSession2 = sparkSession1.newSession()
sparkSession1.sparkContext shouldEqual sparkSession2.sparkContext
sparkSession1.stop()
// Since both SparkContexts are equal, stopping the one for sparkSession1 will make the context of
// sparkSession2 stopped too
sparkSession2.sparkContext.isStopped shouldBe true
// and that despite the different sessions
sparkSession1 shouldNot equal(sparkSession2)
}
But as you can notice, if we stay with the builder, we'll always get the same SparkSession instance:
"Spark" should "create 1 instance of SparkSession with builder"in {
val sparkSession1 = SparkSession.builder().appName("SparkSession#1").master("local").getOrCreate()
val sparkSession2 = SparkSession.builder().appName("SparkSession#2").master("local").getOrCreate()
sparkSession1 shouldEqual sparkSession2
}
Multiple SparkSessions use cases
Hence, having multiple SparkSessions is pretty fine - at least we don't need to play with specific configuration options. However, why we could need it? The first obvious use case - when we need to use data coming from different SparkSessions which can't share the same configuration. The configuration can concern for instance 2 different Hive metastores and their data that somehow must be mixed together. Just for the illustration purposes I tried this scenario with JSON files:
"Spark" should "launch 2 different apps for reading JSON files" in {
val commonDataFile = new File("/tmp/spark_sessions/common_data.jsonl")
val commonData =
"""
| {"id": 1, "name": "A"}
| {"id": 2, "name": "B"}
| {"id": 3, "name": "C"}
| {"id": 4, "name": "D"}
| {"id": 5, "name": "E"}
| {"id": 6, "name": "F"}
| {"id": 7, "name": "G"}
""".stripMargin
FileUtils.writeStringToFile(commonDataFile, commonData)
val dataset1File = new File("/tmp/spark_sessions/dataset_1.jsonl")
val dataset1Data =
"""
| {"value": 100, "join_key": 1}
| {"value": 300, "join_key": 3}
| {"value": 500, "join_key": 5}
| {"value": 700, "join_key": 7}
""".stripMargin
FileUtils.writeStringToFile(dataset1File, dataset1Data)
val dataset2File = new File("/tmp/spark_sessions/dataset_2.jsonl")
val dataset2Data =
"""
| {"value": 200, "join_key": 2}
| {"value": 400, "join_key": 4}
| {"value": 600, "join_key": 6}
""".stripMargin
FileUtils.writeStringToFile(dataset2File, dataset2Data)
// Executed against standalone cluster to better see that there is only 1 Spark application created
val sparkSession = SparkSession.builder().appName(s"SparkSession for 2 different sources").master("local")
.config("spark.executor.extraClassPath", sys.props("java.class.path"))
.getOrCreate()
val commonDataset = sparkSession.read.json(commonDataFile.getAbsolutePath)
commonDataset.cache()
import org.apache.spark.sql.functions._
val oddNumbersDataset = sparkSession.read.json(dataset1File.getAbsolutePath)
.join(commonDataset, col("id") === col("join_key"), "left")
val oddNumbers = oddNumbersDataset.collect()
// Without stop the SparkSession is represented under the same name in the UI and the master remains the same
// sparkSession.stop()
// But if you stop the session you won't be able to join the data from the second session with a dataset from the first session
SparkSession.clearActiveSession()
SparkSession.clearDefaultSession()
val sparkSession2 = SparkSession.builder().appName(s"Another Spark session").master("local")
.config("spark.executor.extraClassPath", sys.props("java.class.path"))
.getOrCreate()
SparkSession.setDefaultSession(sparkSession2)
val pairNumbersDataset = sparkSession2.read.json(dataset2File.getAbsolutePath)
.join(commonDataset, col("id") === col("join_key"), "left")
val pairNumbers = pairNumbersDataset.collect()
sparkSession shouldNot equal(sparkSession2)
def stringifyRow(row: Row): String = {
s"${row.getAs[Int]("id")}-${row.getAs[String]("name")}-${row.getAs[Int]("value")}"
}
val oddNumbersMapped = oddNumbers.map(stringifyRow(_))
oddNumbersMapped should have size 4
oddNumbersMapped should contain allOf("1-A-100", "3-C-300", "5-E-500", "7-G-700")
val pairNumbersMapped = pairNumbers.map(stringifyRow(_))
pairNumbersMapped should have size 3
pairNumbersMapped should contain allOf("2-B-200", "4-D-400", "6-F-600")
}
Also, at least theoretically, we can launch 2 different independent Spark jobs from one common code. Using an orchestration tool seems a better idea though because in the case of the second's session failure, you'll need only to relaunch it without needing to recompute the first dataset.
Another purely theoretical example where we could use multiple SparkSessions is the case when some external input defines the number of jobs not sharing the same configuration to launch:
"Spark" should "launch 3 applications in 3 different threads" in {
val logAppender = InMemoryLogAppender.createLogAppender(Seq("SparkSession#0",
"SparkSession#1", "SparkSession#2"))
val latch = new CountDownLatch(3)
(0 until 3).map(nr => new Thread(new Runnable() {
override def run(): Unit = {
// You can submit this application to a standalone cluster to see in the UI that always only 1 app name
// is picked up and despite of that, all 3 applications are executed inside
val config = new SparkConf().setMaster("local").setAppName(s"SparkSession#${nr}")
.set("spark.executor.extraClassPath", sys.props("java.class.path"))
val sparkSession = SparkSession.builder().config(config)
.getOrCreate()
import sparkSession.implicits._
val dataset = (0 to 5).map(nr => (nr, s"${nr}")).toDF("id", "label")
val rowsIds = dataset.collect().map(row => row.getAs[Int]("id")).toSeq
// Give some time to make the observations
Thread.sleep(3000)
println(s"adding ${rowsIds}")
AccumulatedRows.data.appendAll(Seq(rowsIds))
latch.countDown()
}
}).start())
latch.await(3, TimeUnit.MINUTES)
// Add a minute to prevent against race conditions
Thread.sleep(1000L)
AccumulatedRows.data should have size 3
AccumulatedRows.data.foreach(rows => rows should contain allOf(0, 1, 2, 3, 4, 5))
logAppender.getMessagesText() should have size 1
// Since it's difficult to deduce which application was submitted, we check only the beginning of the log message
val firstMessage = logAppender.getMessagesText()(0)
firstMessage should startWith("Submitted application: SparkSession#")
val Array(_, submittedSessionId) = firstMessage.split("#")
val allSessions = Seq("0", "1", "2")
val missingSessionsFromLog = allSessions.diff(Seq(submittedSessionId))
missingSessionsFromLog should have size 2
}
Notice however that SparkSession encapsulates SparkContext and since by default we can have only 1 context per JVM, all the SparkSessions from above example are represented in the UI within a single one application - usually the first launched. The following image shows the UI after multiple consequent executions of above code snippet. As you can see, the executed app takes always one of 3 submitted names:
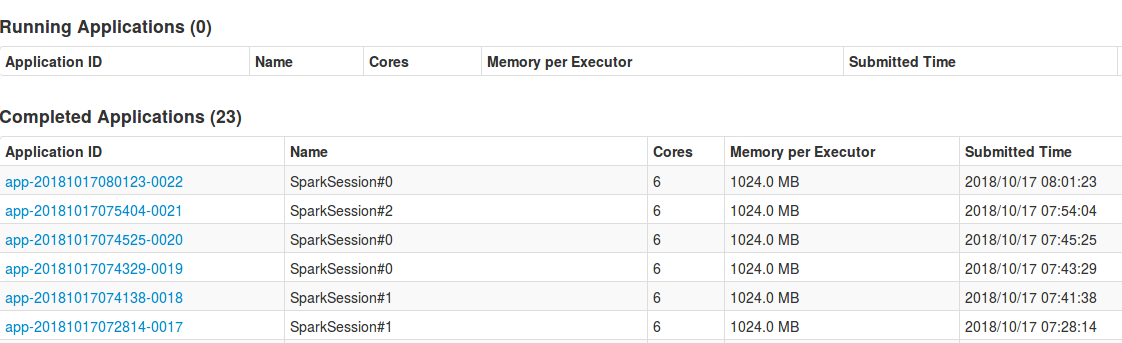
Thus, even though we specify a different configuration for each SparkSession, as for instance different master address, it won't have any effect. Spark will always use the configuration of the first launched session, and thus, of the first created SparkContext. We could of course force the context to stop by calling stop() method of given SparkSession instance. But in such a case we lose the possibility to interact with DataFrames created by stopped session.
The behavior described in the previous paragraph proves also that debugging such applications is hard and much easier would be the use of an orchestration tool to submit these 3 jobs independently. Aside from a monitoring facility, this solution benefits from a much easier data recovery process and less complicated code - the logic of failed or succeeded job is left to the orchestration tool and the processing code can stay focused on what it should do the best with the data.
This post explained the interaction between SparkContext and SparkSession. The first section introduced both classes responsible for managing RDDs, broadcast variables, accumulators and DataFrames. The second part showed how to have multiple instances of SparkContext and SparkSession in a single JVM. Even though it's not an advised practice, with some extra configuration effort, it's possible. The third part tried to explain why multiple SparkSessions could be used. Any of the presented use cases didn't convince me. Every time a solution of the external orchestration of multiple jobs seemed easier to debug, monitor and recover.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Multiple SparkSession for one SparkContext here:
- About multiple SparkSessions that share the same SparkContext How many SparkSessions can a single application have? - Stack Overflow Support multiple SparkContexts in the same JVM Can we able to use mulitple sparksessions to access two different Hive servers SparkContext - Mastering Apache Spark [SPARK-4180] [Core] Prevent creation of multiple active SparkContexts Using the Spark session Run 2 Spark Queries in Parallel
Related blog posts:
- The why of code generation in Apache Spark SQL
- Introduction to custom optimization in Apache Spark SQL
- The who, when, how and what of Apache Spark SQL code generation
- Apache Spark and off-heap memory
- Apache Spark SQL, Hive and insertInto command
I've never done the exercise of having multiple SparkSessions in a single driver process. Fortunately a Github question encouraged me to do a small research about this #ApacheSpark topic : https://t.co/90CY2MSw4T
— Bartosz Konieczny (@waitingforcode) November 30, 2018