
I started the series about Apache Spark SQL customization from the last parts of query execution, which are logical and physical plans. But you must know that before the framework generates these plans, it must first parse the query.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post will start by analyzing the place where Apache Spark translates the query into a structure called Abstract Syntax Tree. At this occasion, I will introduce ANTLR library used to execute this operation. In the second part, I will focus more on the use of this library in Apache Spark SQL. In this post, you won't find contain any customization part. I will present it in the next one.
From text to plan
Before I deep delve into implementation details, I would like to start with the global picture of creating executable code from a SQL query. The transformation happens in 2 steps. In the first, the framework performs a lexical analysis with the help of a lexer. This stage is also known as tokenization and this name should give you more context about its outcome. At the end of the process, lexer generates a list of tokens which are strings with assigned and identified meaning. Among SQL tokens you will retrieve the operators like SELECT, FROM, WHERE, ... so globally everything that is the central part of the language.
Later another actor called parser goes through the tokens and builds a tree that will be later interpreted by Apache Spark to build the logical plan. The following image summarizes these 2 steps:
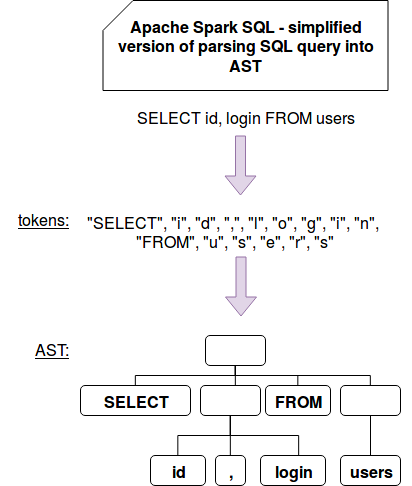
To do all these things Apache Spark uses ANTLR library that I will detail in the next section. But before we go there, let's see the central place where these 2 steps logic is defined, the parse[T](command: String)(toResult: SqlBaseParser => T): T method of AbstractSqlParser:
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command))) // ... val tokenStream = new CommonTokenStream(lexer) val parser = new SqlBaseParser(tokenStream) // ... toResult(parser)
As you can see, we retrieve here our 3 main parts, a lexer (SqlBaseLexer), tokens (CommonTokenStream) and a parser (SqlBaseParser). This protected parse method is invoked from several different places responsible for converting some text into a LogicalPlan, Expression, TableIdentifier, FunctionIdentifier, StructType or DataType instances. The purpose of these conversions is to convert either full SQL queries into logical plans, to transform DDL schemas to corresponding StructType objects or to parse small textual inputs, like myDataset.filter("my_column > 1") into expressions understandable by the engine.
The second interesting point of above snippet is toResult parameter. It defines a function responsible for consuming each read token. Usually it's implemented as one of visit* methods of AstBuilder class being a child of SqlBaseBaseVisitor.
You can find a summary of these methods in the following test cases:
behavior of "parser"
it should "convert SELECT into a LogicalPlan" in {
val parsedPlan = sparkSession.sessionState.sqlParser.parsePlan("SELECT * FROM numbers WHERE nr > 1")
parsedPlan.toString() should include ("'Project [*]")
parsedPlan.toString() should include ("+- 'Filter ('nr > 1)")
parsedPlan.toString() should include (" +- 'UnresolvedRelation `numbers`")
}
it should "convert filter into an Expression" in {
val parsedExpression = sparkSession.sessionState.sqlParser.parseExpression("nr > 1")
parsedExpression shouldBe a [GreaterThan]
parsedExpression.asInstanceOf[GreaterThan].left shouldBe a [UnresolvedAttribute]
parsedExpression.asInstanceOf[GreaterThan].right shouldBe a [Literal]
}
it should "convert data type into Spark StructType" in {
val parsedType = sparkSession.sessionState.sqlParser.parseDataType("struct")
parsedType.toString shouldEqual "StructType(StructField(nr,IntegerType,true), StructField(letter,StringType,true))"
}
it should "convert data type into a schema" in {
val parsedSchema = sparkSession.sessionState.sqlParser.parseTableSchema("nr INTEGER, letter STRING")
parsedSchema.toString shouldEqual "StructType(StructField(nr,IntegerType,true), StructField(letter,StringType,true))"
}
ANTLR and Apache Spark SQL
As I mentioned before, Apache Spark uses a library called ANTLR to transform a textual query into an AST. The syntax definition is included in a .g4 file which is also called a grammar file. In other terms, it's nothing more than a set of lexer and parser rules. To understand the difference between them, let's take an example of the grammar file used by Apache Spark SQL:
fragment LETTER
: [A-Z]
;
IDENTIFIER
: (LETTER | DIGIT | '_')+
;
The lexer is represented here as LETTER whereas the parser as IDENTIFIER. Put another way, the parser is composed of one or more different lexers. In the example, you can see that the identifier can be composed of one or many characters being a letter, a digit or an underscore (_).
Grammar file is the key specification for all the processing logic. Once written, it's used by ANTLR to generate 3 other important components, lexer, parser, and listener. In Apache Spark SQL the former one is represented by org.apache.spark.sql.catalyst.parser.SqlBaseLexer class. You will find there the vocabulary used by the language so in our case all SQL operators. The second important class is SqlBaseParser. It provides a set of rules being the instances of ParserRuleContext which can be thought as a representation for different parts of the constructed tree. Each rule corresponds to the parsed strings. So you will retrieve there the rules for data types, expressions, logical plans or schemas:
abstract class AbstractSqlParser extends ParserInterface with Logging {
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
// ...
}
}
For instance, a SELECT id, login FROM users WHERE id > 1 AND active = true will be internally represented by the following set of parser context rules:
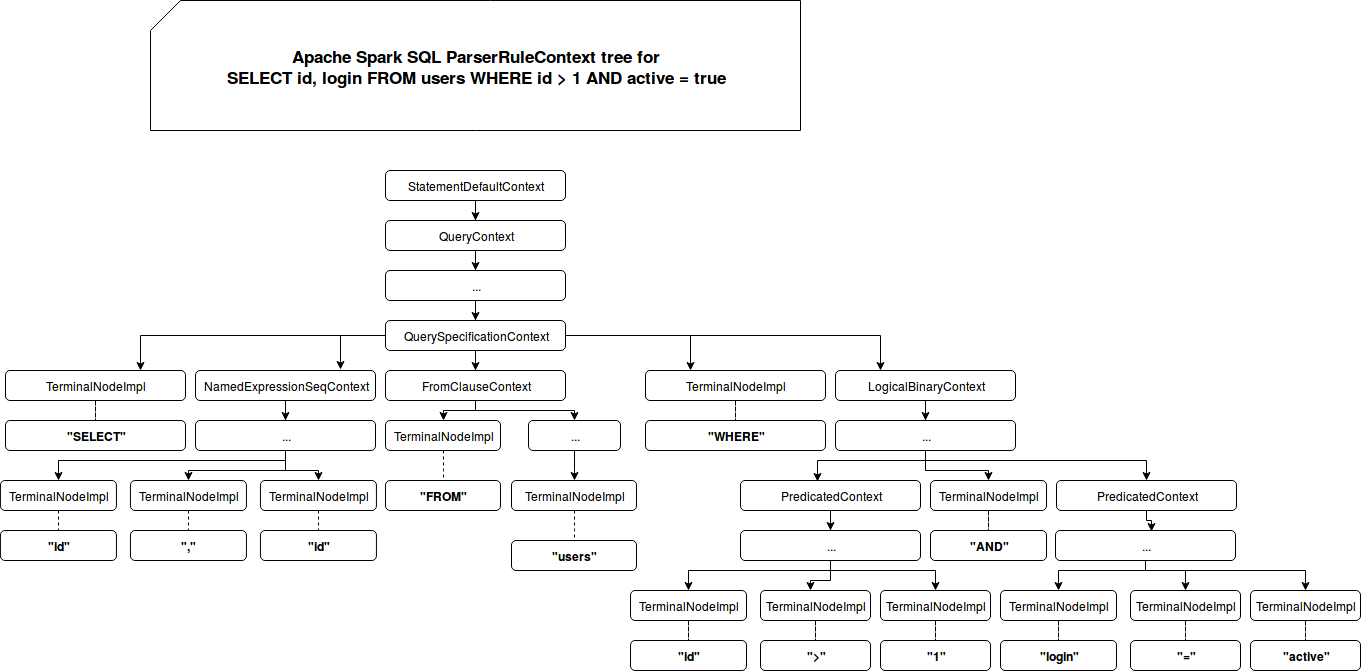
The tree is converted into one of previously mentioned Apache Spark classes (Expression, LogicalPlan, ...) by an ANTLR structure called visitor, implemented as AstBuilder. The implementation defines a set of visit* methods called every time a parse tree is constructed by the parser:
/**
* Visit a parse tree produced by {@link SqlBaseParser#singleStatement}.
* @param ctx the parse tree
* @return the visitor result
*/
T visitSingleStatement(SqlBaseParser.SingleStatementContext ctx);
The visitor is used by org.apache.spark.sql.execution.SparkSqlParser and org.apache.spark.sql.catalyst.parser.CatalystSqlParser classes. They are exposed by SessionState class related to the current SparkSession instance. Maybe you're wondering here what is the difference between SparkSqlParser and CatalystSqlParser? The former one works mainly on Apache Spark SQL statements whereas the latter is reserved to Catalyst expressions, like casting DataTypes or manipulating StructTypes.
As you can see in the post, ANTLR is one of the libraries widely used by Apache Spark to do one of the most important features - converting SQL queries into internal framework objects. The conversion happens in 2 steps called tokenization and parsing. The former one is responsible for generating comprehensible tokens by the framework whereas the latter is used to build a structure used to initialize appropriate classes. Everything is managed by ANTLR's grammar file defining both lexer and parser rules.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Writing custom optimization in Apache Spark SQL - parser here:
- Creating a simple parser with ANTLR Parser rules SqlBase.g4 CatalystSqlParser — DataTypes and StructTypes Parser
Related blog posts:
- Writing custom external catalog listeners in Apache Spark SQL
- Writing custom optimization in Apache Spark SQL - custom parser
- Writing custom optimization in Apache Spark SQL - Union rewriter MVP version
- Writing custom optimization in Apache Spark SQL - generated code
- Writing Apache Spark SQL custom logical optimization - improved code and summary
Today, before exploring parser customization next week, a short recall of #ApacheSpark #SparkSQL parser basics https://t.co/4mhaaXOixv
— Bartosz Konieczny (@waitingforcode) August 7, 2019