
Apache Spark Structured Streaming relies on the micro-batch pattern which evaluates the same query in each execution. That's only a high level vision, though. Under-the-hood, there are many other interesting things that happen.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
From query to the plan
A Structured Streaming job evaluation starts when you call the start() function:
val consoleSink: DataStreamWriter[Row] = filtered
.select($"timestamp", $"value", functions.spark_partition_id())
.writeStream.format("console").trigger(Trigger.ProcessingTime("2 seconds"))
.option("checkpointLocation", "/tmp/wfc/checkpointTemp$")
consoleSink.start().awaitTermination()
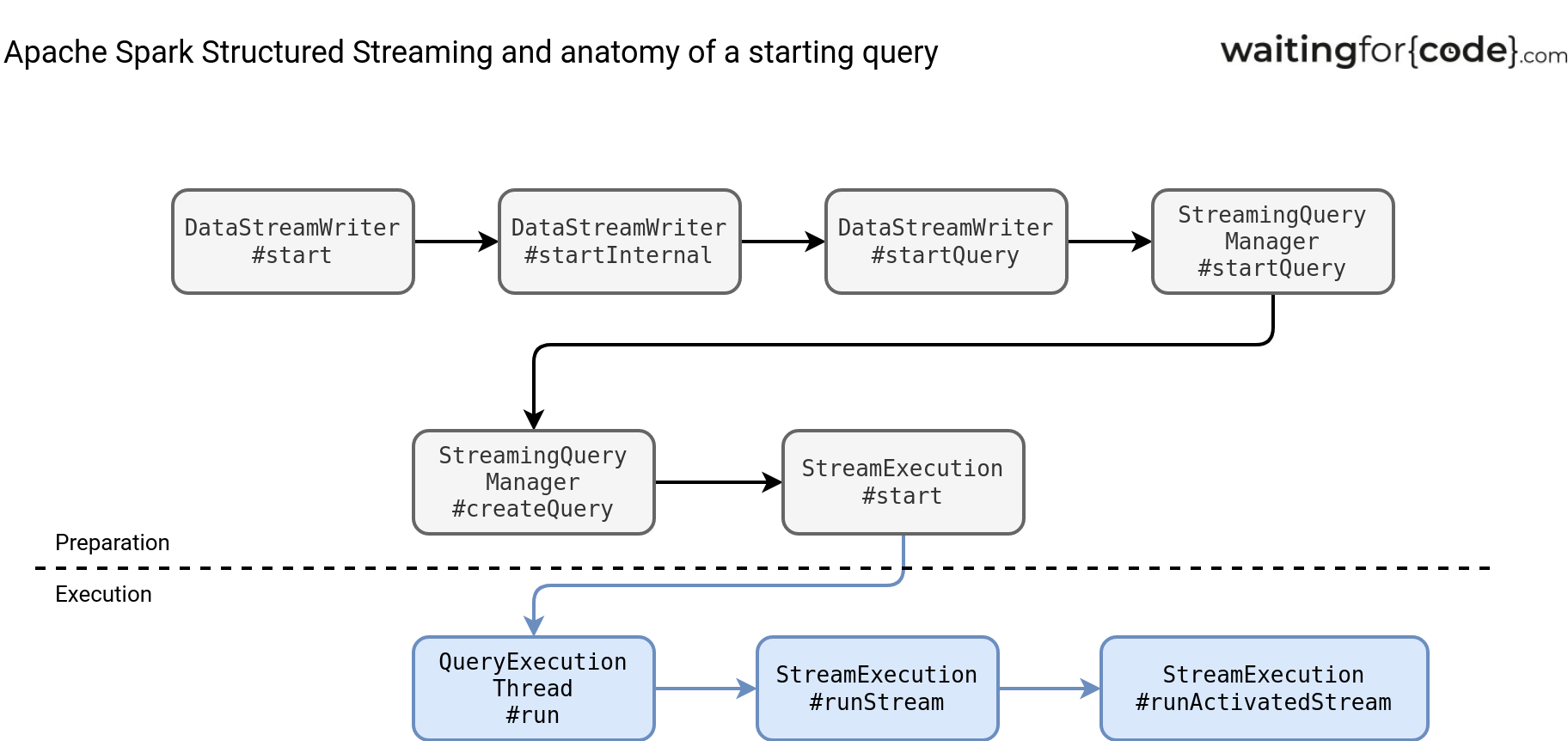
What interesting things happen at each step?
- startInternal creates a Sink, so the structure responsible for writing the processed dataset. It closes the data transformation loop.
- StreamingQueryManager#startQuery performs the plan analysis to ensure all operators are valid. Next, it generates the job runner. Today, most of the time it'll be an instance of MicroBatchExecution.
- QueryExecutionThread#run prepares the query for execution. It configures the SparkSession and calls the runActivatedStream provided by the job runner class.
You may be wondering why the SparkSession needs to be configured. The configuration is necessary to avoid any unexpected side-effects of Apache Spark optimization techniques such as the Cost-Based Optimization and the Adaptive Query Execution. Both are disabled. The former to avoid rearranging the query plan that could impact the stateful operations and their state store location management. The latter could change the number of shuffle partitions which is also disallowed for stateful queries. Remember, they manage one state store instance for each shuffle partition so having thus number changing across micro-batches would break this logic.
Plan execution
Next comes the plan execution, so running the aforementioned runActivatedStream. I'll focus here on the MicroBatchExecution which is the most mature and popular runner implementation.
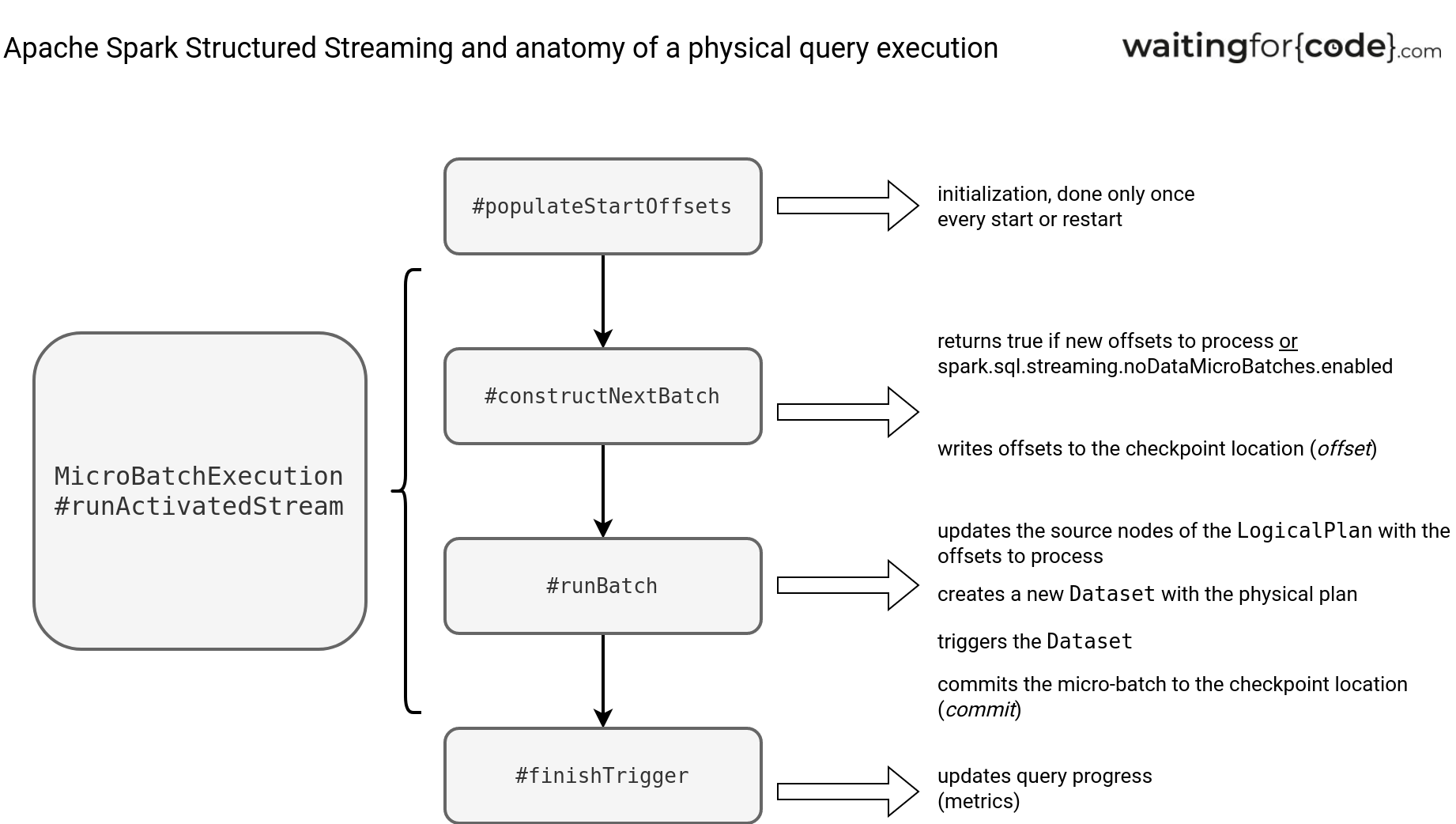
Above is what happens when the MicroBatchExecution runs. First, it populates start offsets. It happens only once per job, so typically when you start and restart it. Next, the runner calls the constructNextBatch method which is a kind of gatekeeper. If it returns false, it means there is no sense to schedule a new micro-batch. It may happen if the offsets hasn't changed and the spark.sql.streaming.noDataMicroBatches.enabled is turned off.
If there is a reason to run a micro-batch, the physical processing happens in the runBatch function. One of the first tasks here is the offsets resolution and the update of the data source nodes in the LogicalPlan with them:
val newBatchesPlan = logicalPlan transform {
// ...
// For v2 sources.
case r: StreamingDataSourceV2Relation =>
mutableNewData.get(r.stream).map {
case OffsetHolder(start, end) =>
r.copy(startOffset = Some(start), endOffset = Some(end))
}.getOrElse {
LocalRelation(r.output, isStreaming = true)
}
}
This newBatchesPlan is the root for the new LogicalPlan that is going to be evaluated at this moment:
lastExecution = new IncrementalExecution(
sparkSessionToRunBatch,
triggerLogicalPlan,
outputMode,
checkpointFile("state"),
id,
runId,
currentBatchId,
offsetLog.offsetSeqMetadataForBatchId(currentBatchId - 1),
offsetSeqMetadata,
watermarkPropagator)
lastExecution.executedPlan // Force the lazy generation of execution plan
Next, a new Dataset is initialized with this plan and evaluated:
val nextBatch = new Dataset(lastExecution, ExpressionEncoder(lastExecution.analyzed.schema))
The evaluation - at least for the V2 Data Source API considered here - involves calling the collect() action:
val batchSinkProgress: Option[StreamWriterCommitProgress] = reportTimeTaken("addBatch") {
SQLExecution.withNewExecutionId(lastExecution) {
sink match {
// ...
case _: SupportsWrite =>
// This doesn't accumulate any data - it just forces execution of the microbatch writer.
nextBatch.collect()
}
// ...
In the end, the runner updates the query progress, saves new commit in the commit log, and sets the new value for the global watermark. An important thing to learn from here is the logical query plan. It's evaluated only once for its general template but as you saw in the previous code snippets, the data source nodes get updated with the new offsets to process. As a result, each micro-batch works on a new logical plan instance.
That's the little story behind a micro-batch execution in Apache Spark Structured Streaming. On the surface, it looks similar to the batch query execution. The process shares all the steps of analysis, logical optimization, and logical-to-physical plan translation. However, there are some subtle differences, such as the logical plan reuse with the updated sources and sinks parts, or the execution method based on the chosen trigger.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩