
The main Apache Spark component enabling stateful processing is StateStoreRDD. It creates a partition-based state store instance but also triggers state-based computation.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This short blog post explains the role of StateStoreRDD in the stateful processing. In the first sections you will find the details about the data processing part. They will then cover the compute() method. In the third part, you will discover another component interacting with the StateStoreRDD instance, the StateStoreCoordinatorRef.
StateStoreRDD initialization
StateStoreRDD is created from an implicit class called StateStoreOps, and more exactly one of its implementations of mapPartitionsWithStateStore. If you are not a Scala-guy or forgot the definition, an implicit class is often used to extend the behavior of the existing classes whose code source you can't change. Let's take this example where I added a method called printWithDots to Scala's String basic class:
implicit class StringDotPrinter(textToPrint: String) {
def printWithDots = println(textToPrint.split("").mkString("."))
}
"abc".printWithDots
The mapPartitionsWithStateStore uses the same technique. All of the stateful operation classes call this method on their child nodes:
private[streaming] def mapPartitionsWithStateStore[U: ClassTag](...): StateStoreRDD[T, U] = {
val cleanedF = dataRDD.sparkContext.clean(storeUpdateFunction)
val wrappedF = (store: StateStore, iter: Iterator[T]) => {
// Abort the state store in case of error
TaskContext.get().addTaskCompletionListener[Unit](_ => {
if (!store.hasCommitted) store.abort()
})
cleanedF(store, iter)
}
new StateStoreRDD(
dataRDD,
wrappedF,
// ...
}
override protected def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithStateStore(
The implicit class doesn't include any complex logic but it includes a quite important element which is the TaskCompletionListener function. If you check the code snippet once again, you will see that if the state store associated with the task is not correctly terminated (committed) after completing the task, any operation it recorded should be aborted. Apart from that, you can also notice how the stateful function is passed to the StateStoreRDD as the wrappedF instance.
StateStoreRDD and compute method
Once initialized, Apache Spark can use StateStoreRDD's compute(partition: Partition, ctxt: TaskContext) to perform stateful operation and interact with the state store. At the beginning, Apache Spark creates an instance of StateStoreProviderId and uses it to initialize the StateStoreProvider instance here:
// StateStore companion object
def get(...): StateStore = {
val storeProvider = loadedProviders.synchronized {
startMaintenanceIfNeeded()
val provider = loadedProviders.getOrElseUpdate(
storeProviderId,
StateStoreProvider.createAndInit(
storeProviderId.storeId, keySchema, valueSchema, indexOrdinal, storeConf, hadoopConf)
)
reportActiveStoreInstance(storeProviderId)
provider
}
storeProvider.getStore(version)
}
An important point to notice at this occasion is the property of the StateStoreProviderId called StateStoreId. It's composed of 3 fields which show pretty clearly that the state store will be unique per stateful operation, task (partition) and also the type of operation (you'll learn more about this in the blog post about streaming joins):
case class StateStoreId(
checkpointRootLocation: String,
operatorId: Long,
partitionId: Int,
storeName: String = StateStoreId.DEFAULT_STORE_NAME)
After setting up this contextual information, Apache Spark determines the version of the state store either from the micro-batch or epoch number. Later, this information is used, alongside the StateStoreProviderId and a few other attributes (schemas, state store configuration) to get the input data and pass it to the state store update function:
store = StateStore.get(
storeProviderId, keySchema, valueSchema, indexOrdinal, currentVersion,
storeConf, hadoopConfBroadcast.value.value)
val inputIter = dataRDD.iterator(partition, ctxt)
storeUpdateFunction(store, inputIter)
The storeUpdateFunction is different for every stateful operation and that's why I won't explain it here. Instead, you will find a focus on them and their interaction with the state store in next blog posts.
State store coordinator
But data processing is not the single thing happening in the StateStoreRDD. Another one happens in getPreferredLocations(partition: Partition) method. It returns the executors where the scheduler should execute the partition's task. And to get this location, StateStoreRDD uses a StateStoreCoordinatorRef:
override def getPreferredLocations(partition: Partition): Seq[String] = {
val stateStoreProviderId = StateStoreProviderId(
StateStoreId(checkpointLocation, operatorId, partition.index),
queryRunId)
storeCoordinator.flatMap(_.getLocation(stateStoreProviderId)).toSeq
}
It sends an RPC call of GetLocation type and gets the location information found in StateStoreCoordinator's instances: mutable.HashMap[StateStoreProviderId, ExecutorCacheTaskLocation]. In the picture below, you can find how the state store communicates with the coordinator:
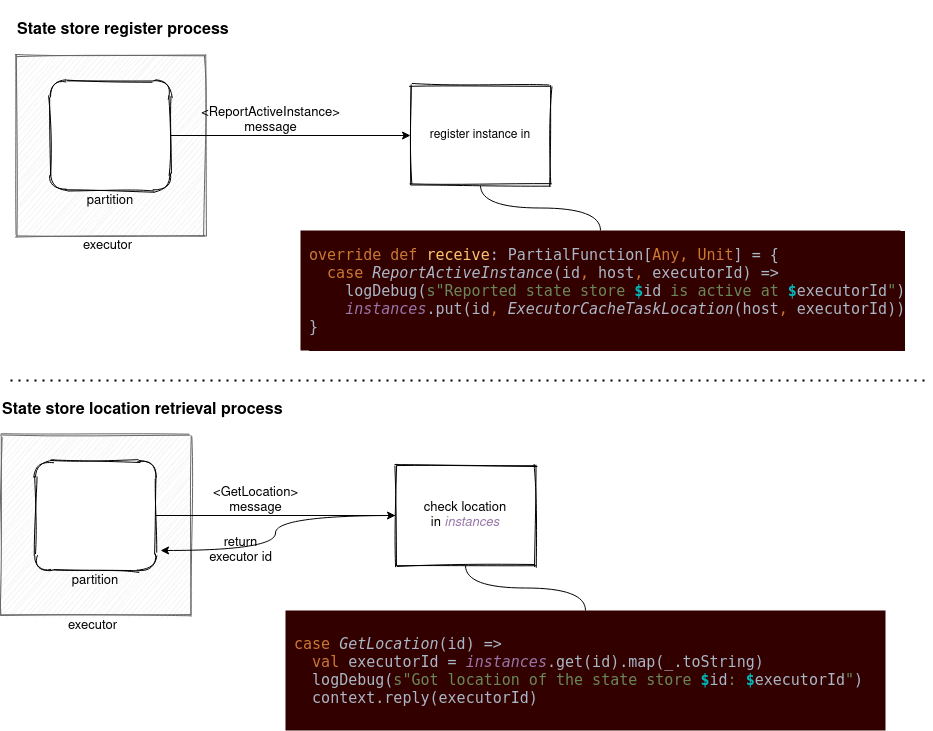
StateStoreRDD is the abstraction performing stateful operations and interacting with the state store inside them. However, as you saw in the code snippets, it wraps the stateful logic defined in the stateful operations like joins or drop duplicates. If you are curious and want to see what do they include, you will find some answers in the next blog posts!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data+AI follow-up: StateStoreRDD - building block for stateful processing here:
Related blog posts:
- Data+AI Summit follow-up post: Why RocksDB rocks?
- Data+AI Summit: custom state store integration feedback
- Data+AI Summit: Custom state store - API
- Data+AI follow-up: Introduction to MapDB
- Data+AI Summit follow-up: arbitrary stateful processing and state management
The first follow-up post for this year's Data+AI Summit talk is online. To start, a quick presentation of #ApacheSpark #StructuredStreaming StateStoreRDD ? https://t.co/AG57wVPC4W And see you in less than 2 weeks ?
— Bartosz Konieczny (@waitingforcode) November 7, 2020