
After previous introductory posts, it's time to deep delve into the state store API and implement our own custom state store.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The article starts with a short presentation of 5 main groups of functions every state store has to implement. The second part shows how they interact with the MapDB state store API.
State store methods categories
To implement your own state store you have to provide 2 classes, org.apache.spark.sql.execution.streaming.state.StateStoreProvider and org.apache.spark.sql.execution.streaming.state.StateStore. Technically, the former one is more a builder for the state store but both can share the same responsibilities.
The first main group of operations is called CRUD and it represents all functions that your StateStore will use to write and read the state. More exactly, they're represented by these methods:
trait StateStore {
def get(key: UnsafeRow): UnsafeRow
def put(key: UnsafeRow, value: UnsafeRow): Unit
def remove(key: UnsafeRow): Unit
}
There is nothing more to say, maybe except highlighting the fact that the UnsafeRow instance from put method can be reused. In consequence, if you decided to store UnsafeRows in the state store, in the end, you may only store the last entry (since UnsafeRow is mutable and can be reused). That's why it's important to use copy() method before saving anything to the state store.
The second group composes the functions for state expiration. Surprisingly, you will find here 2 reading functions but since they're mostly used in the state expiration logic, they can be classified as the "state expiration" rather than the "CRUD" ones. These functions are getRange and iterator. More exactly, since as of this writing ranges are not implemented in the state store, the single function you have to provide is the latter one. The default implementation of getRange calls under-the-hood the iterator one:
trait StateStore {
def getRange(start: Option[UnsafeRow], end: Option[UnsafeRow]): Iterator[UnsafeRowPair] = {
iterator()
}
def iterator(): Iterator[UnsafeRowPair]
}
The next category of functions groups everything related to the transactions management. Because yes, the state store has the transactional aspect. For every task, so for every processed partition, so automatically for every state store (is partition-based), Apache Spark adds a task listener where it verifies whether the state store has been committed. If it didn't happen, the abort() method is invoked. Otherwise, nothing happens. The state store is committed after successfully processing all input elements and after removing any expired state. Technically, it happens thanks to the callbacks registered in NextIterator and CompletionIterator, both being used in the stateful operations. Below you can find a short summary for this part:
// Transactional methods
trait StateStore {
def commit(): Long
def abort(): Unit
def hasCommitted: Boolean
}
// Transaction management
package object state {
implicit class StateStoreOps[T: ClassTag](dataRDD: RDD[T]) {
private[streaming] def mapPartitionsWithStateStore[U: ClassTag]( // ...
val cleanedF = dataRDD.sparkContext.clean(storeUpdateFunction)
val wrappedF = (store: StateStore, iter: Iterator[T]) => {
// Abort the state store in case of error
TaskContext.get().addTaskCompletionListener[Unit](_ => {
if (!store.hasCommitted) store.abort()
})
cleanedF(store, iter)
}
// ...
// Transaction commit - same logic for all stateful operations, example of an arbitrary stateful processing
case class FlatMapGroupsWithStateExec( //...
override protected def doExecute(): RDD[InternalRow] = {
// ...
child.execute().mapPartitionsWithStateStore[InternalRow](
getStateInfo,
groupingAttributes.toStructType,
stateManager.stateSchema,
indexOrdinal = None,
sqlContext.sessionState,
Some(sqlContext.streams.stateStoreCoordinator)) { case (store, iter) =>
// ...
CompletionIterator[InternalRow, Iterator[InternalRow]](outputIterator, {
commitTimeMs += timeTakenMs {
store.commit()
}
setStoreMetrics(store)
}
)
The 4th group are the functions responsible for metrics tracking. Here, for the first time, you will find the methods from StateStore and StateStoreProvider. The former implementation returns the metrics for the current state store version. The latter only returns the list of supported custom metrics by the state store. Internally these metrics are represented as one of 3 implementations of StateStoreCustomMetric, and before returning them to the logs, they're converted to SQLMetrics that are in fact the accumulators:
trait StateStore {
def metrics: StateStoreMetrics
}
trait StateStoreProvider {
def supportedCustomMetrics: Seq[StateStoreCustomMetric] = Nil
}
trait StateStoreWriter extends StatefulOperator { self: SparkPlan =>
// ...
private def stateStoreCustomMetrics: Map[String, SQLMetric] = {
val provider = StateStoreProvider.create(sqlContext.conf.stateStoreProviderClass)
provider.supportedCustomMetrics.map {
case StateStoreCustomSumMetric(name, desc) =>
name -> SQLMetrics.createMetric(sparkContext, desc)
case StateStoreCustomSizeMetric(name, desc) =>
name -> SQLMetrics.createSizeMetric(sparkContext, desc)
case StateStoreCustomTimingMetric(name, desc) =>
name -> SQLMetrics.createTimingMetric(sparkContext, desc)
}.toMap
}
}
class SQLMetric(val metricType: String, initValue: Long = 0L) extends AccumulatorV2[Long, Long] { // ...
The final category of functions - well technically it's a single function - covers the maintenance of the state store. It means that this function implements any performance optimization and clean up tasks. It's invoked as a background thread and in the default state store, it creates snapshot files and deletes old state store versions:
trait StateStoreProvider {
def doMaintenance(): Unit = { }
}
StateStore and MapDB API
The following image summarizes the interactions between StateStore and MapDB APIs:
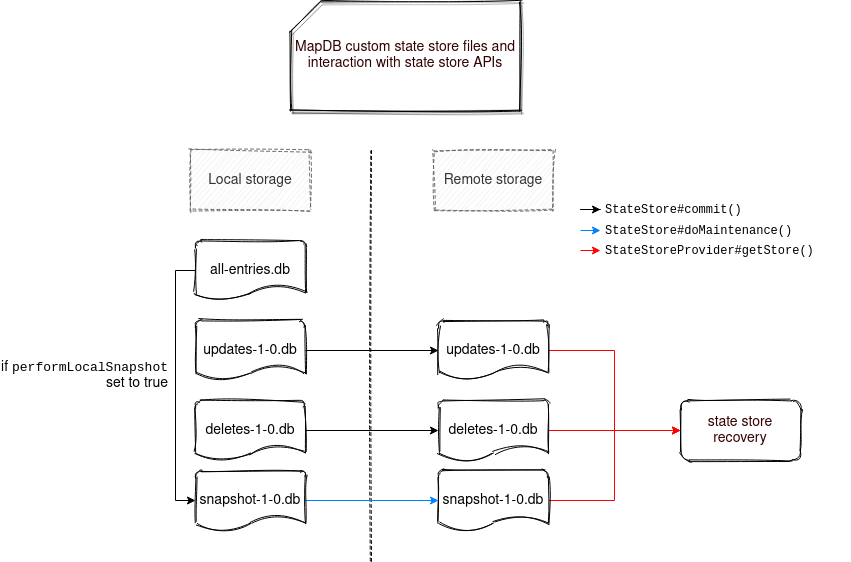
As you can see, from left to right, the stateful application interacts with three types of files. The first of them called all-entries-default-1-0.db is the snapshot version of the state store, ie. it stores all states committed so far. When the performLocalSnapshot flag is true, all its values are copied to a "snapshot" file, which will be later synchronized by the maintenance task to some more resilient storage.
Besides that, the stateful operation writes the state store changes to updates-default-1-0.db for updates, and deletes-default-1-0.db for deletes. Whenever a key changes, it's automatically removed from the all-entries-default-1-0.db. Thanks to that action, only one copy of each state is kept at a time. When the commit happens, both files are synchronized to the fault-tolerant remote storage and all changes from the update file are replayed on the all-entries-default-1-0. Thanks to that, if the file has to be transformed to a snapshot, it will contain all processed states in the current version.
On the rightmost part of the diagram, you can see a state store recovery operation that will be used in case of the application's restart. This operation will read either the snapshot file or the updates and deletes if the snapshot is unavailable, exactly like in the default state store implementation.
Sure, it was only a high-level view of the implementation, but I hope it helps to catch better the interactions between state store and MapDB. If you are interested more in the code, you can check this repository prepared for this Data+AI 2020 Summit follow-up post series.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data+AI Summit follow-up post: Why RocksDB rocks?
- Data+AI Summit: custom state store integration feedback
- Data+AI follow-up: Introduction to MapDB
- Data+AI Summit follow-up: arbitrary stateful processing and state management
- Data+AI Summit follow-up: joins and state management
State store API has 5 main groups responsible among others for simple CRUD operations and more complex transaction management. You can discover them and the global overview of the MapDB store implementation in the new #StructuredStreaming blog post ? https://t.co/Ihick56M3F
— Bartosz Konieczny (@waitingforcode) January 23, 2021