
State store uses checkpoint location to persist state which is locally cached in memory for faster access during the processing. The checkpoint location is used at the recovery stage. An important thing to know here is that there are 2 file formats with checkpointed state, delta and snapshot files.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
And I will answer some questions about delta and snapshot files in Structured Streaming default state store implementation. Since it's a short post, I will omit the outline and go directly to the questions.
How delta is performed?
Every time a new state is added, or an already existent state is modified or expired, the changes go through put or remove methods of HDFSBackedStateStoreProvider. These methods do 2 things actually. The first one is the manipulation of the underlying in-memory map and updating or removal of the state. The second one is the update of the state store by calling writeUpdateToDeltaFile(output: DataOutputStream, key: UnsafeRow, value: UnsafeRow) for an update or writeRemoveToDeltaFile(output: DataOutputStream, key: UnsafeRow) for a removal. Both methods interact with a DataOutputStream that is flushed when all updates of the current query execution are done. The buffer is closed and therefore flushed in finalizeDeltaFile(output: DataOutputStream) method.
It means that your delta file won't contain all entries. Instead, it will only store modified or deleted entries:
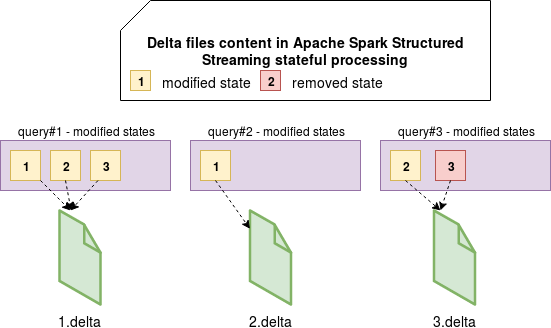
The output stream of delta files is a LZ4-compressed so the state is written in blocks of spark.io.compression.lz4.blockSize k.
How snapshot is performed?
Delta files are written continuously, at the end of each query. Snapshot files are different because they're maintained by a background maintenance thread. This thread wakes up every spark.sql.streaming.stateStore.maintenanceInterval (by default 60 seconds) and performs some cleaning job. One of them is "merging" (actually it's not a real physical merge of the files) multiple delta files into one snapshot file.
The snapshot is performed the following way. First, the maintenance thread lists all files from the checkpoint location. Since the files are called with "${query_version}.${extension}" pattern, the returned names are sorted by the number of versions. Later the thread counts the number of delta files from the previous snapshot. If this number is greater than spark.sql.streaming.stateStore.minDeltasForSnapshot (default = 10), then it performs the snapshot.
What data is taken for the snapshot? The maintenance thread will use the in-memory state store corresponding to the latest delta version. If the meantime that version was removed from the memory cache, the operation is aborted. Otherwise, all data present in the map, so updated and not updated states, are written to the snapshot file. As you can deduce, since any removal automatically removes the state from the in-memory map, any removed state is written to the snapshot.
What is the difference between snapshot and delta files?
As you can see, the state is checkpointed in 2 different types of files, deltas and snapshot. What's the difference between them? As said, delta files store all updates of the state. We can say then that they store the things that happened with the state. On the other hand, snapshot takes the current version of the state, not only the most recent evolutions. That's why you can find there the states that changed a long time ago and that are still active.
Another, maybe the most important difference that at the same time shows the real purpose of a snapshot, comes from the recovery part. If you need to reload your state and your query version has a snapshot file, Apache Spark will directly put it into the memory cache and restart the query. Otherwise, it will load the state incrementally from all delta files, leading to some bigger I/O overhead. I will cover this part more in detail in one of the next posts about data reprocessing of stateful pipelines.
Does snapshot contain all group states (modified + removed)?
No. The content of snapshot version will be the same as the content of in-memory map representing all states for given version. And since StateStore's remove function will call a remove function on this map, the snapshot will contain only alive states:
override def remove(key: UnsafeRow): Unit = {
verify(state == UPDATING, "Cannot remove after already committed or aborted")
val prevValue = mapToUpdate.remove(key)
if (prevValue != null) {
writeRemoveToDeltaFile(compressedStream, key)
}
}
And for the snapshot creation, there are the most important parts:
private def doSnapshot(): Unit = {
// ...
synchronized { Option(loadedMaps.get(lastVersion)) } match {
case Some(map) =>
if (deltaFilesForLastVersion.size > storeConf.minDeltasForSnapshot) {
val (_, e2) = Utils.timeTakenMs(writeSnapshotFile(lastVersion, map))
logDebug(s"writeSnapshotFile() took $e2 ms.")
}
And that's all. Understanding delta and snapshot files is quite easy. You can consider the deltas as an iterative version of your state whereas the snapshot as the final...well snapshot of the data store, ie. a 1-to-1 copy of it.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
A brand new #SparkAISummit follow-up post is online. This time it's about delta and snapshot formats in #ApacheSpark #StructuredStreaming https://t.co/Ih7xpKETmd
— Bartosz Konieczny (@waitingforcode) November 2, 2019