
When I started to think about implementing my own state store, I had an idea to load the state on demand for given key from a distributed and single-digit milliseconds latency store like AWS DynamoDB. However, after analyzing StateStore API and how it's used in different places, I saw it won't be easy.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Despite the fact that the implementation is not fully operational I didn't give up the idea of implementing a state store. But rather than providing another available state store, I focused on presenting the implementation process and different points that made the use of DynamoDB difficult in real life. But before revealing you the code, I will start by describing some of state store internals. In the second part, I will provide an architecture schema for the solution. I will show you the implementation only in the next post of the series.
How customize state internals?
A part of the answer to this question is in the checkpointed metadata file. The file contains a list of different configuration entries related to the given streaming query and one of them is spark.sql.streaming.stateStore.providerClass. It represents a class used to manage state.
To implement your own provider, you must extend StateStoreProvider trait and provide a zero-arg constructor. StateStoreProvider exposes different methods doing some initialization and maintenance work but the most important one is the method returning the state store used for a particular version of the store:
def getStore(version: Long): StateStore
StateStoreProvider is only a class returning the state store. The specific store must implement StateStore contract and it's this contract that will be used to manage group states for every key:
def get(key: UnsafeRow): UnsafeRow def put(key: UnsafeRow, value: UnsafeRow): Unit def remove(key: UnsafeRow): Unit def commit(): Long def abort(): Unit
Among existing custom implementations for state stores you can find a RocksDB which is one of the solutions available on Databricks Runtime. That being said, you can also find some Open Source implementations for this backend in the project called Spark-states.
Interactions diagram
That's all for the internal classes. Let's see now how they're interacting with Apache Spark Structured Streaming objects:
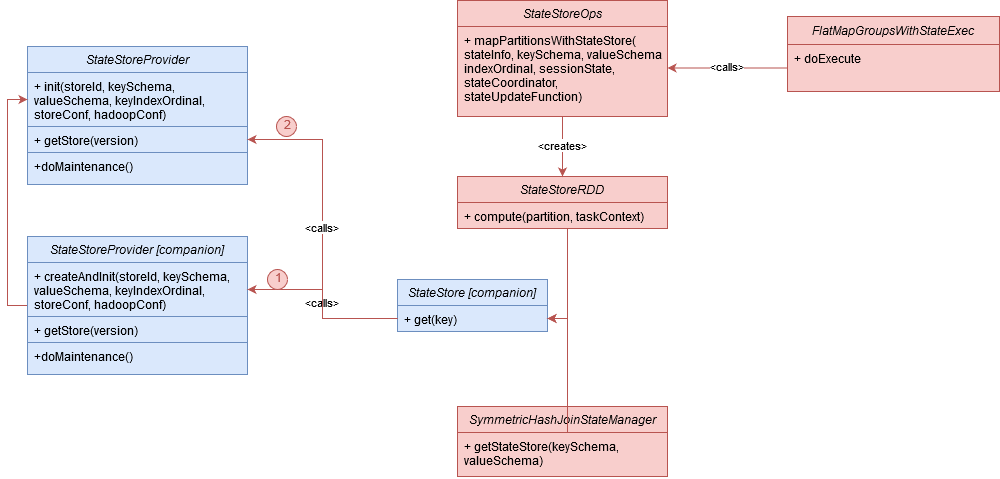
This first diagram illustrates how Apache Spark enters to the state store. As you can see, it retrieves the store from 2 places. The first place is a StateStoreRDD's compute method where it gets the state and later updates it with one of available state store update methods. For the case of an arbitrary stateful processing the method is defined in FlatMapGroupsWithStateExec's doExecute and more exactly, as the last parameter of child.execute().mapPartitionsWithStateStore[InternalRow] call. The function calls everything we learned so far. It updates the state with new events and also manages the state expiration. And all these operations are made with the help of a StateManager class, which after performing some preparation work, delegates these calls to the state store implementation:
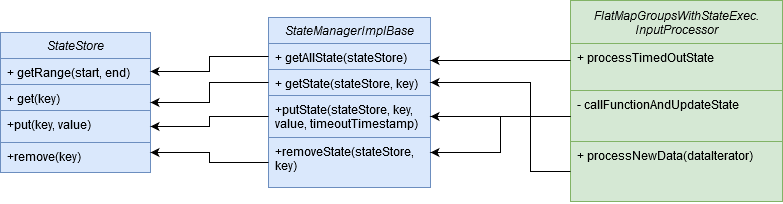
Solution overview
After learning all these details about the API, it's a good moment to define some classes of our custom state store:
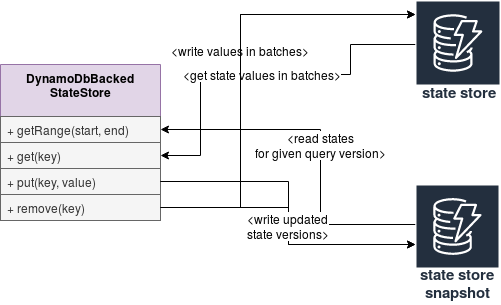
The general idea for this storage is to keep 2 collections in the DynamoDbBackedStateStore class. The first one will store all states with their most recent versions, Map[StateKey, Versions]. And these values are written at every state store commit into state store snapshot table. The second collection is a List[UpdatedStates] that will be written in batches to the state store table. The list contains all states modified in given query execution.
For the reading part, DynamoDbBackedStateStore will first retrieve all state keys and their versions from state store snapshot. Later it will use this information to retrieve state values in batches in the iterator returned by getRange function.
And that's all for that introduction post. My goal is not to create the next state store implementation. Rather than that, I want to focus on the pure aspect of extending the state store. That's something I will show you in more detail in the next post of the series.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Extending state store in Structured Streaming - introduction here:
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending data reprocessing period for arbitrary stateful processing applications
- Custom checkpoint file manager in Structured Streaming
Before going more in depth next week, I wrote a short introduction to extending #ApacheSpark #StructuredStreaming state store https://t.co/TyfmQYjX4e
— Bartosz Konieczny (@waitingforcode) December 8, 2019