
In my previous post I have shown you the writing and reading parts of my custom state store implementation. Today it's time to cover the data reprocessing and also the limits of the solution.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
POC
TL;TR - it's not prod-ready
To see why, please read the info block from Extending state store in Structured Streaming - reading and writing state post.
Delta and snapshot in DynamoDB state store
I was wondering how to implement delta vs snapshot on my custom state store. Finally, I opted for something I called snapshot groups. A snapshot group is a set of all states with their versions either created or changed since the last snapshot group. Let me explain that on the picture:
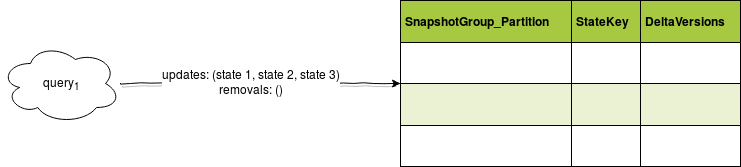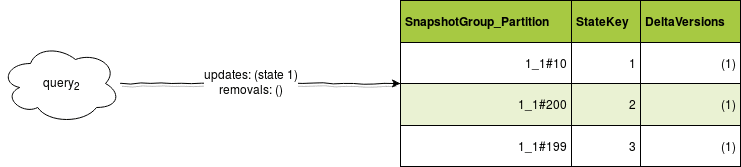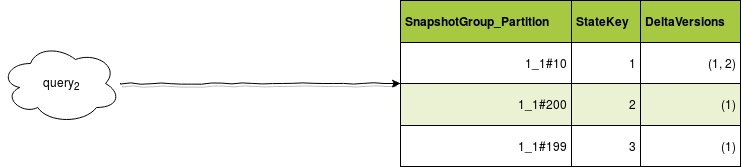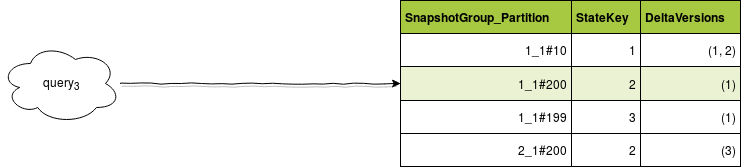
As you can see, I tried to mix delta and snapshot in a single data store. To retrieve the states during data reprocessing, I will need to:
- figure out the snapshot group - I'm doing that directly from spark.sql.streaming.stateStore.minDeltasForSnapshot property: snapshotGroup = newVersion / storeConf.minDeltasForSnapshot
- load all states that are present in the given snapshot group by making BatchGetItem requests
- filter out the delta versions to keep by comparing the version of reprocessed state store with the versions from the DynamoDB item
The implementation looks like:
def recoverState(snapshotGroup: Long, partition: Int, maxDeltaVersion: Long, maxSuffixNumber: Int,
dynamoDbProxy: DynamoDbProxy): Map[String, SnapshotGroupForKey] = {
val partitionKeys = (0 until maxSuffixNumber).map(suffix => {
DynamoDbStateStoreParams.snapshotPartitionKey(snapshotGroup, partition, suffix)
})
partitionKeys.flatMap(partitionKey => {
dynamoDbProxy.queryAllItemsForPartitionKey(SnapshotTable, PartitionKey, partitionKey, Seq(StateKey, DeltaVersions,
DeleteDeltaVersion),
(attributes) => {
val versionsToKeep = DynamoDbStateStoreParams.deltaVersionFromString(attributes(DeltaVersions).getS)
.filter(deltaVersion => deltaVersion <= maxDeltaVersion)
val deletedInVersion = Option(attributes(DeleteDeltaVersion).getS)
val snapshotGroupForKey = deletedInVersion.map(deleteVersion => {
if (deleteVersion.toLong == versionsToKeep.last) {
None
} else {
Some(SnapshotGroupForKey(versionsToKeep))
}
}).getOrElse(Some(SnapshotGroupForKey(versionsToKeep)))
(attributes(StateKey).getS, snapshotGroupForKey)
}
)
}).filter {
case (_, snapshotGroupForKey) => snapshotGroupForKey.isDefined
}
.map {
case (key, snapshotGroupForKey) => (key, snapshotGroupForKey.get)
}
.toMap
}
As you can see, I'm using here DynamoDB's Query to get all suffixed states per partition. The reason for that is simple. You can't use the Get request if you provide only partition key for a table with a sort key. In my case, I only know the partition key and have no idea what sort keys exist for given partition.
Here I'm also filtering the expired states by checking the value of the DeleteDeltaVersion column. If it exists and is the same as the last eligible version for given group, we can consider given state as expired and so, do not put it into the states with versions map.
Demo time
To show you how that MVP implementation works, I will use a simple dataset adding the following data in batches:
#1 = (1L, "test10"), (1L, "test11"), (2L, "test20")
#2, #3, #4, #5 = (1L, s"test ${new Date()}")
#6, #7, #8, #9 = (2L, s"test ${new Date()}")
#10, #11, #12, #13 = (3L, s"test ${new Date()}")
#14, #15, #16, #17 = (4L, s"test ${new Date()}")
# and so forth
My sink will simply print aggregated values and I expect to see something like (date will correspond to the execution date):
Expiring state for 1 processing Some(test10, test11, testThu Nov 14 19:04:24 CET 2019, testThu Nov 14 19:04:27 CET 2019, testThu Nov 14 19:04:29 CET 2019, testThu Nov 14 19:04:32 CET 2019, testThu Nov 14 19:04:34 CET 2019) Expiring state for 2 processing Some(testThu Nov 14 19:04:37 CET 2019, testThu Nov 14 19:04:39 CET 2019, testThu Nov 14 19:04:42 CET 2019, testThu Nov 14 19:04:44 CET 2019, testThu Nov 14 19:04:47 CET 2019)
In the following video you can see how the custom state store works:
Limits of the solution
I didn't say that the solution isn't prod-ready without reason. It still has a lot of drawbacks Among the obvious latency issues for the items retrieved unitary, even with the help of DAX, there are some other important points to take into account. The first one is about snapshot and deltas covered in this article. In fact, the solution works as it only when you try to retrieve the last version. For other scenarios,especially if you changed your business logic and compute different state versions, it may not work as expected. Imagine that scenario:
- execution#1: query#1={ 1, 2, 3}; query#2={2}; query#3={2, 3}; DynamoDB table:
state key 1, group 1={1}, state key 2, group 1={1, 2}, state key 3, group 1={1}
state key 2, group 2 = {2}, state key 3, group 2={3} - Now, you need to reprocess the data from the query 2. After reprocessing, the output of your query#3 is empty because you changed the business rule and the states 2 and 3 were invalidated. So the state key 2, group 2 = {2}, state key 3, group 2={3} aren't valid anymore.
- If you need now to reprocess the query 3, you will retrieve the invalid entries from the previous point.
To overcome that issue, you can do at least one of 2 things. Either you can clean the groups or use the system of aliases that I covered already on the Big Data immutability approaches - aliasing blog post.
Another point to improve is state retrieval. Because getRange() method needs the state groups to figure out which ones are about to expire, I fetch the state twice: once when there are the new data to add and once to check the state expiration time. As an improved, I could store the expiration time in the StatesWithVersions map alongside the modified versions but it's rather a hacky solution. For my use case of an arbitrary stateful aggregation, the getRange() is used to check the state expiration but the method is tended to be more global and it must return the state groups contained in the specified ranges. So assuming that it's only used for the state expiration, even though it's true for the tested use case, is a little bit too strong.
The next concern is also about performance. In my code, I use a synchronous DynamoDB client. It works in the MVP but in general, the performance could be improved with an asynchronous client. It's true, especially for the places calling 2 different tables, like flushing where state groups and state store tables are invoked. That being said, the latency issue for the state retrieval will still be there.
And finally, among the limitations, you will find the case where only one snapshot group can be written for a given state, ie. you can't close the state in the first query and create a new one in one of the next queries. In the end, you will always have only the last state written. To overcome that issue, the sort key can be written with a timestamp value and such a modified state can be later reconciled from multiple entries. However, for this demo version, I didn't want to complicate too much.
As I said many times, please do not consider this blog post as "the" implementation of "the" state store. I wrote it, alongside the state store code, to see how to integrate Structured Streaming stateful processing with distributed, fast access data stores like DynamoDB. At the same time, it's a good summary for all posts written so far about the state store, and also a good way to terminate the chapter of Spark+AI Summit 2019 follow-up blog posts :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
- Custom checkpoint file manager in Structured Streaming
The last part of my custom #ApacheSpark #StructuredStreaming state store implementation is online. Check the new post https://t.co/tFxGaMMDN0 ?
— Bartosz Konieczny (@waitingforcode) December 21, 2019