
In my previous post I introduced the classes involved in the interactions with the state store, and also shown the big picture of the implementation. Today it's time to write some code :)
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
POC
TL;TR - it's not prod-ready
The code from this post never left its POC stage. I wrote it to see how to extend a state store and play with the API. I also wanted to try to see how to reduce the memory pressure made by the state store. You're free to test the implementation at scale even though I don't believe that the network access for the state values will be faster than the memory lookups, even for fast storage like DynamoDB. Maybe the solution is in-between these 2 approaches and, for instance, we could set up the max size of the state cache for values, like saying "I want to store 3000 most recent values and the rest retrieve on demand from an external place"?
If you're curious about the limits of my proposal, stay tuned. Next week I will publish a new post with few of them.
If you want to discover other available state store customizations, you can check chermenin's RocksDB implementation.
I will start this post by explaining the details of DynamoDB tables introduced in the last week's post. In the next part, I'll show you the code persisting state changes. After that, I will go to the code reading the state values. In the next post, the last one about the customized state store, I will cover the data reprocessing part, verify if the provider works, and also discuss the limits of this solution.
Tables model
My DynamoDB-based state store provider will use 2 tables. Let's call the first of them state store and the second one snapshot. The former one will store every state modification, exactly like the delta files. Its design looks like in the following schema:
| StateKey_QueryVersion | State |
|---|---|
| This column will store the key used in mapping function alongside the query version that changed the associated state. | The state data as a compressed gzip UnsafeRow to keep things sample. |
The snapshot table has the following design:
| SnapshotGroup_Partition | StateKey | DeltaVersions | DeleteVersion |
|---|---|---|---|
| The snapshot group represents all states present in the X most recent query versions. This partition key will be suffixed with a number computed from the StateKey column to avoid write throughputs. | It's the sort key of the table. It stores the state key associated with the row. The definition of the sort key is important. Without it, it wouldn't be possible to add multiple lines for the snapshot groups. | This column stores all version numbers that are present for given state in state store table. | An optional column with the version where given state has been deleted. It will be used at the state recovery stage to figure out whether the state should be returned for processing or not. |
Global picture for the interactions between the storage and the code looks like:
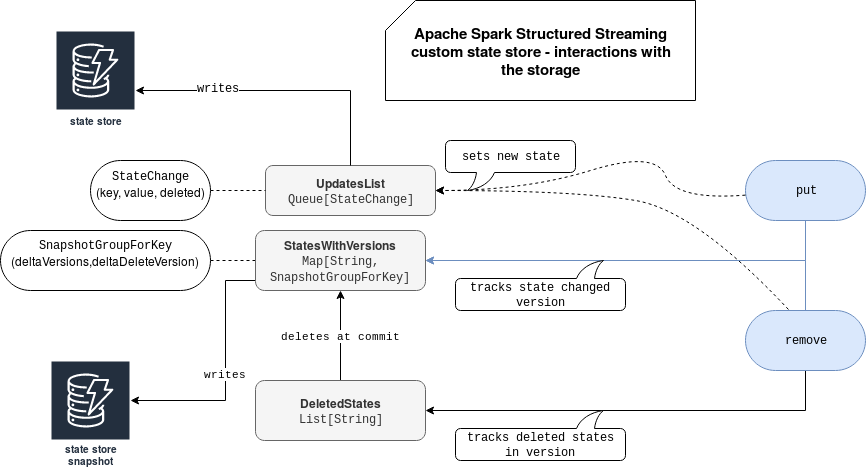
Writing state
Two state store methods will be responsible for writing the state to the DynamoDB tables, namely put and remove. Even though they're called for different purposes, their logic is quite similar. First, the changed state will be added to a queue. Next, the state key will be updated in the map storing states with all versions seen so far. At the end the actions will be eventually flushed to the DynamoDB:
override def put(key: UnsafeRow, value: UnsafeRow): Unit = {
UpdatesList.offer(StateStoreChange.fromUpdateAction(key.copy(), Some(value.copy()), false))
val stateVersions = StatesWithVersions.getOrElseUpdate(key.toString, SnapshotGroupForKey())
val updatedStateVersion = stateVersions.addVersion(version)
StatesWithVersions.put(key.toString, updatedStateVersion)
flushChangesForThreshold()
}
override def remove(key: UnsafeRow): Unit = {
UpdatesList.offer(StateStoreChange.fromUpdateAction(key.copy(), None, true))
// We'll remove the state that for sure exists in the state store - otherwise, fail fast because it's not
// normal to remove a not existent state
val stateVersions = StatesWithVersions(key.toString)
val deletedStateVersion = stateVersions.delete(version)
StatesWithVersions.put(key.toString, deletedStateVersion)
deletedStates.append(key.toString)
flushChangesForThreshold()
}
private def flushChangesForThreshold() = {
if (UpdatesList.size == DynamoDbStateStoreParams.FlushThreshold) {
flushChanges()
}
}
private def flushChanges(): Unit = {
val itemsToWrite = (0 until DynamoDbStateStoreParams.FlushThreshold).map(_ => UpdatesList.poll())
.filter(item => item != null)
if (itemsToWrite.nonEmpty) {
calledFlushes += 1
dynamoDbProxy.writeItems[StateStoreChange](StateStoreTable, itemsToWrite,
(stateStoreItem => stateStoreItem.toItem(version)))
dynamoDbProxy.writeItems[StateStoreChange](SnapshotTable, itemsToWrite,
(stateStoreItem => createItemForSnapshotGroupState(stateStoreItem.key))
)
}
}
override def commit(): Long = {
flushChanges()
// I got the reason of keeping deletedStates apart => it'll be useful for abort
// If we abort, we cancel all changes made so far, so we can simply change the versions
deletedStates.foreach(stateKey => {
StatesWithVersions.remove(stateKey)
})
if (isFirstSnapshotGroup) {
// It simulates the real snapshot from HDFS-backed data source
// For the last version in given snapshot group we save all state in the snapshot table
// to retrieve them in the next group
val mappingFunction: (String) => Item = (stateKey => {
createItemForSnapshotGroupState(stateKey)
})
dynamoDbProxy.writeItems[String](SnapshotTable, StatesWithVersions.keys.toSeq, mappingFunction)
}
isCommitted = true
version
}
As you can see, the remove method does an extra thing which is adding the key of the deleted state to a buffer with deleted states. This map is used in the commit action to remove the state history from the statesWithVersions map. I'm not doing that before because of the abort method that should cancel all changes made in the given version. And having a trace of deleted rows will help me to do that:
override def abort(): Unit = {
val modifiedStates = StatesWithVersions.filter {
case (_, stateVersions) => stateVersions.lastVersion == version
}
val statesToWrite = modifiedStates.grouped(DynamoDbStateStoreParams.FlushThreshold)
statesToWrite.foreach(states => {
abortAlreadyExistentSnapshots(states.toMap)
abortNewSnapshots(states)
abortDeltaChanges(states)
})
deletedStates.clear()
}
Regarding the flush part, I'm writing the state changes to both tables every time the number of accumulated items is equal to 25. Why 25? Because that's the maximal number of items we can put into a single BatchWriteItem request. Among other limits, you can find things like the maximal size for the batch request (16MB) and the individual item (400KB). For the sake of simplicity, I'm not enforcing them.
I copied the format of written data from the default state store implementation. Every state change is written either as: (key size, key, value size, optionally value). If the state is removed, the value size is set to -1 and the value part is missing. All that data is written GZIP-compressed to save the space and not reach the size limits of DynamoDB:
def compressKeyAndValue(key: UnsafeRow, value: Option[UnsafeRow], isDelete: Boolean): Array[Byte] = {
val byteArrayOutputStream = new ByteArrayOutputStream()
val gzipCodec = new GzipCodec().createOutputStream(byteArrayOutputStream)
val dataOutputStream = new DataOutputStream(gzipCodec)
val keyBytes = key.getBytes()
dataOutputStream.writeInt(keyBytes.size)
dataOutputStream.write(keyBytes)
if (isDelete) {
dataOutputStream.writeInt(-1)
} else {
val valueBytes = value.get.getBytes()
dataOutputStream.writeInt(valueBytes.size)
dataOutputStream.write(valueBytes)
}
dataOutputStream.close()
byteArrayOutputStream.toByteArray
}
Reading state
Writing part was quite easy. Making reads in the context of my challenge of not storing all the state in memory was more difficult. That's because of the iterator(). The iterator returned by this method is used by FlatMapGroupsWithStateExecHelper.StateManagerImplBase#getAllState(StateStore) to retrieve all states and figure out which ones are expiring. In this specific method I'm retrieving all states present in the StatesWithVersions and it's one of my small defeats. As you can deduce, the value for a particular state can be retrieved twice, once for iterator() and once for get(key), if there are some new input logs for it. I will cover that bad aspects of the solution in the next post about custom state store.
An individual state is fetched directly from DynamoDB. But before sending the request, I retrieve the last state version for the given key and if it doesn't exist, I consider that it's the first time I see that key. Otherwise, in case of data reprocessing, it should already have been loaded from snapshot table:
override def get(inputStateKey: UnsafeRow): UnsafeRow = {
calledGets += 1
val lastVersionOption = StatesWithVersions.getOrElse(inputStateKey.toString, SnapshotGroupForKey())
.deltaVersions.lastOption
lastVersionOption.map(lastVersion => {
val state = dynamoDb.getTable(StateStoreTable)
.getItem(new PrimaryKey(MappingStateStore.PartitionKey, s"${inputStateKey.toString}_${lastVersion}"))
val (_, value) = UnsafeRowConverter.getStateFromCompressedState(
state.getBinary(MappingStateStore.StateData), keySchema, valueSchema)
value
}).getOrElse({
null
})
}
I don't know if you see the problem but getting a single state at once will be slow, especially if you multiply the retrieval time by thousands or millions of states. And so even though DynamoDB is a single-digit millisecond data store. Hopefully, you can accelerate the retrieval time by using a DynamoDB Accelerator (DAX) which is an in-memory cache for DynamoDB. It's able to process queries in microseconds (up to 10x performance improvement according to the AWS' documentation), even for millions of requests (still according to the doc). I haven't had a chance yet to test DAX but it worth a try when the performances start to suffer (that being said, the state memory access will be always faster).
In this part about Structured Streaming custom state store implementation you can discover the writing and reading part details. Both use AWS SDK to interact with DynamoDB, with a little support of queue and hash map data structures to keep intermediary data on the main memory. In the next blog post from the series, you will discover delta and snapshot management and also see a short demo of the code.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Extending state store in Structured Streaming - reading and writing state here:
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
- Custom checkpoint file manager in Structured Streaming
This morning I published the first part of my #ApacheSpark #StructuredStreaming custom state store implementation. You can learn there more about read and write parts https://t.co/2Tj5jJoICC
— Bartosz Konieczny (@waitingforcode) December 15, 2019