
After my Summit's talk I got an interesting question on "off" for the data reprocessing of sessionization streaming pipeline. I will try to develop the answer I gave in this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first section I will introduce the context of the question. The second part will contain a simple solution implemented on top of AWS.
Reprocessing boundary
Data reprocessing capability in Structured Streaming is limited by spark.sql.streaming.minBatchesToRetain. This property indicates how many of the most recent queries will be stored in the checkpoint location. Its default value is 100. If you're triggering your data every 5 minutes, it means that you'll be able to reprocess up to ~8 hours ago which can not be enough.
So to solve the problem you can simply increase this value to more than 100. Let's suppose we're targeting the data reprocessing boundary of 2 days for our 5 minutes triggering period. We'll then need to store 576 queries which is still quite fine.
But what if you will need to have a longer guarantee and for instance, have to store 100 000 versions? You can simply change the minBatchesToRetain property and see what happens. Normally, the performances should start to suffer. Apache Spark lists the checkpointed files, as well for the metadata as for the state store part, to figure out how many of them it accumulated so far and if some of the oldest ones should be removed. If the time took for fetching the files is too big, you can use another technique that I will describe in the second part of this post. But if the performances are still fine, do not over-complicate your life and keep things simple.
Cold storage backup
To overcome the problem with slower listing because of the increased amount of versions, you can simply store the versions in 2 places. The first place is your checkpoint location and it's Apache Spark who will generate the files there. The second place is a kind of backup storage where an application will copy every file from the checkpoint location for more long-term storage. Below you can find the implementation using AWS Lambda and its event-driven system:
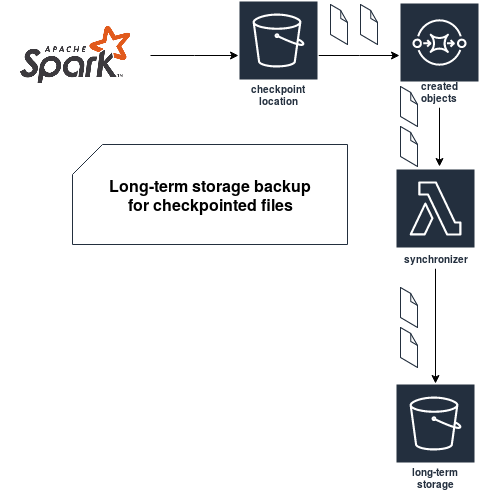
The idea is straightforward. Every new file is intercepted by the synchronizer and copied into a new bucket containing the versions that will never be removed (or if you want, you can configure the expiration policy directly on the bucket). With that approach, you can keep the minBatchesToRetain property small and have a guarantee that you will be able to reprocess the data ever for a long period in the past.
The synchronizer is a simple Lambda which copies every object with CopyObjectRequest class, so the operation is not very risky. And even if it fails, you will always be able to replay it from the queue. On the other hand, you've just complexified your pipeline. Now in addition to your streaming application, you also have to monitor everything that happens in the synchronization part. Hopefully, it uses the managed services and does a simple copy, so the maintenance burden should not have a big impact.
Now to reprocess a very old query, you will need to:
- create a new checkpoint location (for simplicity) and change it in your code
- move there all files from the required query versions, so globally it will be {snapshot version} -> {restored version}
- restart the query
- if everything works, delete the previous checkpoint location
Of course, if you store the last year of your queries, you must also ensure that the same amount of data is available on your streaming broker. To recall, the metadata files store offsets information so if the data retention policy on your Apache Kafka topic is lower than that, you will not be able to reprocess all historical versions.
By presenting you this solution I don't want to say "do that every time". Rather than that, I wanted to share an alternative way to keep as many query versions as you want without impacting the performance of maintenance jobs on Apache Spark side. If you don't observe any impact on your side ("fetchFiles() took ...." messages in the logs), you should always keep your architecture as simple as possible. But if you do, you can always consider moving the backup files elsewhere, like in the solution from the second part of this post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Extending data reprocessing period for arbitrary stateful processing applications here:
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Custom checkpoint file manager in Structured Streaming
I've just published a proposal to extend the data reprocessing capability of #ApacheSpark #StructuredStreaming stateful apps without keeping all versions on the checkpoint location https://t.co/qnPhnc6Emj
— Bartosz Konieczny (@waitingforcode) December 7, 2019