
In this post I will start the customization part of the topics covered during my talk. The first customized class will be the class responsible for the checkpoint management.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first part of the post I will illustrate the interactions made between Structured Streaming and checkpoint location. After that, I will describe the API of CheckpointFileManager. In the last part, I will implement a sample manager working on the local file system. The post has a purely exploratory purpose so using it on production is not a good idea.
Interactions with the checkpoint manager
To customize the checkpoint, you need to implement the contract exposed by CheckpointFileManager interface. It's responsible for manipulating file system on behalf of different parts using the checkpoint location, like state store or metadata checkpoint. A more complete view of the interactions is presented in the following schema:
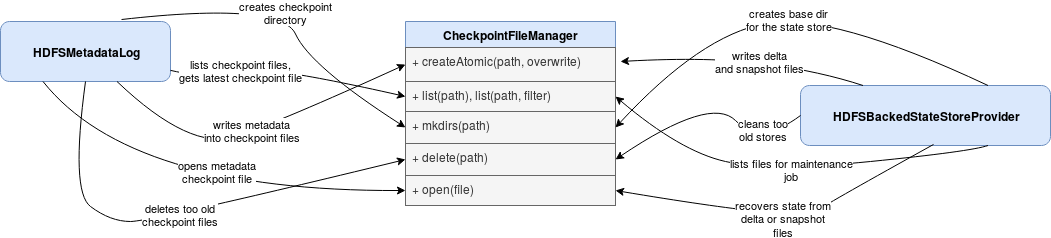
As you can see, CheckpointFileManager is used for state store and checkpoint files management. It lists the content of them but also creates or deletes their files.
Checkpoint manager API
If you will implement your own CheckpointFileManager, you will have to implement the following methods:
- createAtomic(path: Path, overwriteIfPossible: Boolean) - creates a file which content is available only at the end of writing. The atomicity of the default implementation consists of creating a temporary file that at the end of writing is renamed to the final name. Overwrite flag indicates whether the manager should try to overwrite already existent file.
- open(path: Path) - opens a file and returns Hadoop's FSDataInputStream
- list(path: Path, filter: PathFilter) - lists files from the path matching the filter.
- mkdirs(path: Path) - creates the directories from the path.
- exists(path: Path) - checks whether the path exists.
- delete(path: Path) - deletes the path recursively.
- isLocal - to check whether the file system is local.
How can I customize checkpointing?
To customize the checkpoint manager you must define the configuration property called spark.sql.streaming.checkpointFileManagerClass and set it to your class. The class itself must implement CheckpointFileManager class and the contract explained in the previous section. In my example I will use the following implementation based on the Java NIO package:
class JavaNioCheckpointFileManager(path: Path, hadoopConf: Configuration) extends CheckpointFileManager {
private val fs = path.getFileSystem(hadoopConf)
override def createAtomic(path: Path, overwriteIfPossible: Boolean): CancellableFSDataOutputStream = {
println(s"#createAtomic(${path}, ${overwriteIfPossible})")
ActionsTracker.CreateAtomicCalls.append(path.toString)
val temporaryPath = Paths.get(path.suffix("-tmp").toUri)
new CancellableFSDataOutputStream(Files.newOutputStream(temporaryPath)) {
override def cancel(): Unit = {
Files.delete(temporaryPath)
}
override def close(): Unit = {
super.close()
Files.move(temporaryPath, Paths.get(path.toUri))
}
}
}
override def open(path: Path): FSDataInputStream = {
println(s"#open(${path})")
// InputStream must be a seekable or position readable - I'm using the same as
// in the default implementation for the sake of simplicity. Otherwise an exception like this
// one will occur:
// java.lang.IllegalArgumentException: In is not an instance of Seekable or PositionedReadable
fs.open(path)
}
override def list(path: Path, filter: PathFilter): Array[FileStatus] = {
println(s"#list(${path}, ${filter})")
import scala.collection.JavaConverters._
Files.list(Paths.get(path.toUri)).filter(new Predicate[file.Path] {
override def test(localPath: file.Path): Boolean = {
filter.accept(new Path(localPath.toUri))
}
})
.collect(Collectors.toList()).asScala
.map(path => {
val fileStatus = new FileStatus()
fileStatus.setPath(new Path(path.toUri))
fileStatus
})
.toArray
}
override def list(path: Path): Array[FileStatus] = {
println(s"#list(${path})")
list(path, new PathFilter { override def accept(path: Path): Boolean = true })
}
override def mkdirs(path: Path): Unit = {
ActionsTracker.MakeDirsCalls.append(path.toString)
println(s"#mkdirs(${path})")
Files.createDirectories(Paths.get(path.toUri))
}
override def exists(path: Path): Boolean = {
println(s"#exists(${path})")
ActionsTracker.ExistencyChecks.append(path.toString)
Files.exists(Paths.get(path.toUri))
}
override def delete(path: Path): Unit = {
println(s"#delete(${path})")
if (exists(path)) {
Files.delete(Paths.get(path.toUri))
}
}
override def isLocal: Boolean = true
}
object ActionsTracker {
val ExistencyChecks = new mutable.ListBuffer[String]()
val MakeDirsCalls = new mutable.ListBuffer[String]()
val CreateAtomicCalls = new mutable.ListBuffer[String]()
}
As you can see, I'm doing nothing special. Almost every time the code is a simple call to Java's Files class with Java's Path created from Hadoop's Path URI. Although the code is simple, I have 2 things to share. The first one is the constructor - you have to define one accepting Path and Configuration parameters. Otherwise, you will get this exception:
java.lang.NoSuchMethodException: com.waitingforcode.sparksummit2019.customcheckpoint.JavaNioCheckpointFileManager.(org.apache.hadoop.fs.Path, org.apache.hadoop.conf.Configuration) at java.lang.Class.getConstructor0(Class.java:3082) at java.lang.Class.getConstructor(Class.java:1825) at org.apache.spark.sql.execution.streaming.CheckpointFileManager$.create(CheckpointFileManager.scala:181) at org.apache.spark.sql.execution.streaming.HDFSMetadataLog. (HDFSMetadataLog.scala:63) at org.apache.spark.sql.execution.streaming.OffsetSeqLog. (OffsetSeqLog.scala:46)
Another point is that the InputStream from the open method must be a Seekable or ReadablePosition implementation. I simplified this part by using the same code as the original checkpoint manager. To assert that the code is working as expected, I do a simple accumulation of calls on ActionsTracker class and making some assertions on their emptiness at the end of the code:
val sparkSession = SparkSession.builder()
.appName("Spark Structured Streaming custom checkpoint")
.config("spark.sql.shuffle.partitions", 5)
.config("spark.sql.streaming.checkpointFileManagerClass", "com.waitingforcode.sparksummit2019.customcheckpoint.JavaNioCheckpointFileManager")
.master("local[1]").getOrCreate()
import sparkSession.implicits._
private val MappingFunction: (Long, Iterator[Row], GroupState[Seq[String]]) => Seq[String] = (_, values, state) => {
val stateNames = state.getOption.getOrElse(Seq.empty)
val stateNewNames = stateNames ++ values.map(row => row.getAs[String]("name"))
state.update(stateNewNames)
stateNewNames
}
"the state" should "be initialized for the same data source" in {
val testKey = "state-init-same-source-mode"
val schema = StructType(
Seq(StructField("id", DataTypes.LongType, false), StructField("name", DataTypes.StringType, false))
)
val sourceDir = "/tmp/batch-state-init"
val stateDataset = Seq((1L, "old_page1"), (2L, "old_page2")).toDF("id", "name")
stateDataset.write.mode(SaveMode.Overwrite).json(sourceDir)
val stateQuery = sparkSession.readStream
.schema(schema)
.json(sourceDir).groupByKey(row => row.getAs[Long]("id"))
.mapGroupsWithState(MappingFunction)
.writeStream
.option("checkpointLocation", "/tmp/batch-checkpoint")
.outputMode(OutputMode.Update())
.foreach(new InMemoryStoreWriter[Seq[String]](testKey, (stateSeq) => stateSeq.mkString(",")))
.start()
stateQuery.awaitTermination(45000)
stateQuery.stop()
ActionsTracker.ExistencyChecks should not be empty
ActionsTracker.MakeDirsCalls should not be empty
ActionsTracker.CreateAtomicCalls should not be empty
}
In the post you can see a simple implementation of a custom checkpoint file manager. I bet that you will never have to implement it on your own since the default implementation is good enough. However, in case if you want to go further and write the checkpointing on a less standard file system, this blog post can be a good start.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Extending state store in Structured Streaming - reprocessing and limits
- Extending state store in Structured Streaming - reading and writing state
- Why UnsafeRow.copy() for state persistence in the state store?
- Extending state store in Structured Streaming - introduction
- Extending data reprocessing period for arbitrary stateful processing applications
Today I begin the last part of my summit follow-up posts ?. During the next 4 weeks I will cover #ApacheSpark #StructuredStreaming customization. The 1st presented item is the checkpoint file manager https://t.co/s0oCH5ZMEC
— Bartosz Konieczny (@waitingforcode) December 1, 2019