
Streaming joins are an interesting feature that heavily uses state store. Even though I already blogged about it in the past (2018), some changes were made and also - I hope so - my explanation capacity improved.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post will start by introducing the StreamingSymmetricHashJoinExec operator responsible for performing the joins and managing the state stores. The second part will explain what different state stores are involved in state management. Three last sections will close the presentation with a deep dive into inner and outer joins for streaming data sources.
StreamingSymmetricHashJoinExec
If you verify the physical plan for a stream-to-stream join, you will see there a StreamingSymmetricHashJoin node. Below you can find an example of such a plan:
+- StreamingSymmetricHashJoin [ad_id#58], [ad_id#26], LeftOuter, condition = [ leftOnly = null, rightOnly = null, both = (event_time#57 >= click_time#29-T20000ms), full = (event_time#57 >= click_time#29-T20000ms) ], state info [ checkpoint = file:/tmp/data+ai/stateful/stream_stream_joins/checkpoint/state, runId = 8304706f-3b2a-4c63-99fb-75ed24c2956b, opId = 0, ver = 0, numPartitions = 2], 0, state cleanup [ left = null, right = null ], 2
:- Exchange hashpartitioning(ad_id#58, 2), true, [id=#49]
: +- Project [from_json(StructField(event_time,TimestampType,true),
# ...
+- Exchange hashpartitioning(ad_id#26, 2), true, [id=#59]
+- *(3) Filter isnotnull(click_time#29-T20000ms)
+- EventTimeWatermark click_time#29: timestamp, 20 seconds
+- Project [from_json(StructField(event_time,TimestampType,true), StructField(ad_id,IntegerType,true), cast(value#8 as string), Some(Europe/Paris)).event_time AS click_time#29, from_json(StructField(event_time,TimestampType,true), StructField(ad_id,IntegerType,true), cast(value#8 as string), Some(Europe/Paris)).ad_id AS ad_id#26]
# ...
As you can see, the data is shuffled before Apache Spark performs the physical joining in the StreamingSymmetricHashJoinExec operator. In the doExecute() method, the operator starts by resolving the state store names for both sides of the join. They're later passed as a parameter to the underlying RDD class (StateStoreAwareZipPartitionsRDD) where they're used in the getPreferredLocations to find the executor where every partition should execute:
class StateStoreAwareZipPartitionsRDD[A: ClassTag, B: ClassTag, V: ClassTag](
sc: SparkContext,
var f: (Int, Iterator[A], Iterator[B]) => Iterator[V],
var rdd1: RDD[A],
var rdd2: RDD[B],
stateInfo: StatefulOperatorStateInfo,
stateStoreNames: Seq[String],
@transient private val storeCoordinator: Option[StateStoreCoordinatorRef])
extends ZippedPartitionsBaseRDD[V](sc, List(rdd1, rdd2)) {
override def getPreferredLocations(partition: Partition): Seq[String] = {
stateStoreNames.flatMap { storeName =>
val stateStoreProviderId = StateStoreProviderId(stateInfo, partition.index, storeName)
storeCoordinator.flatMap(_.getLocation(stateStoreProviderId))
}.distinct
}
Once retrieved, the RDD's compute method executes the f: (Int, Iterator[A], Iterator[B]) => Iterator[V] function passed to the constructor from the StreamingSymmetricHashJoinExec. This function is nothing more than the function where the rows are really joined and an output is produced:
private def processPartitions(
partitionId: Int,
leftInputIter: Iterator[InternalRow],
rightInputIter: Iterator[InternalRow]): Iterator[InternalRow]
State stores in joins
All the interactions with the state stores are performed inside this function. And by the way, why "state stores" in plural? Simply because there are 2 instances. The first is called KeyToNumValuesStore. Spark uses it to store the number of values for every join key. Why is storing it important? The number of values per key helps to consume the correct number of elements from the second state store. You can see its use case in SymmetricHashJoinStateManager.KeyWithIndexToValueStore#getAll(key: UnsafeRow, numValues: Long): Iterator[KeyWithIndexAndValue]:
// KeyWithIndexToValueStore
def getAll(key: UnsafeRow, numValues: Long): Iterator[KeyWithIndexAndValue] = {
val keyWithIndexAndValue = new KeyWithIndexAndValue()
var index = 0
new NextIterator[KeyWithIndexAndValue] {
override protected def getNext(): KeyWithIndexAndValue = {
if (index >= numValues) {
finished = true
null
} else {
// Build the row to return
As you can deduce from the previous snippet, the second state store is called KeyWithIndexToValueStore and it physically stores the joined rows at "key + index"-basics. The key is then a composition of the join key and the index you can also see in the previous snippet. Everything is standardized in the state store's key schema:
// KeyWithIndexToValueStore
private val keyWithIndexExprs = keyAttributes :+ Literal(1L)
private val keyWithIndexSchema = keySchema.add("index", LongType)
private val indexOrdinalInKeyWithIndexRow = keyAttributes.size
// Projection to generate (key + index) row from key row
private val keyWithIndexRowGenerator = UnsafeProjection.create(keyWithIndexExprs, keyAttributes)
Whenever a new row is added or an old one removed, the following keyWithIndexRow(key: UnsafeRow, valueIndex: Long) is called first to generate the id and pass it to the state store instance:
// KeyWithIndexToValueStore
def put(key: UnsafeRow, valueIndex: Long, value: UnsafeRow, matched: Boolean): Unit = {
val keyWithIndex = keyWithIndexRow(key, valueIndex)
val valueWithMatched = valueRowConverter.convertToValueRow(value, matched)
stateStore.put(keyWithIndex, valueWithMatched)
}
/**
* Remove key and value at given index. Note that this will create a hole in
* (key, index) and it is upto the caller to deal with it.
*/
def remove(key: UnsafeRow, valueIndex: Long): Unit = {
stateStore.remove(keyWithIndexRow(key, valueIndex))
}
private def keyWithIndexRow(key: UnsafeRow, valueIndex: Long): UnsafeRow = {
val row = keyWithIndexRowGenerator(key)
row.setLong(indexOrdinalInKeyWithIndexRow, valueIndex)
row
}
Apart from that, it's worth noticing that the KeyWithIndexToValueStore supports 2 versions for the value. The V1 stores only the matched value, whereas V2 has a boolean flag called matched to avoid returning the left side in the left outer join after the expiration if it was already matched and returned. It's one of the new features of Apache Spark 3, and you can learn more about it in Structured Streaming 3 bug fixes blog post.
If you set the checkpoint location and check what state store files are stored on disk, you should see something like that:
left-keyToNumValues left-keyWithIndexToValue right-keyToNumValues right-keyWithIndexToValue
Those are the 2 state stores, but they couldn't work alone. The access to them is controlled by SymmetricHashJoinStateManager that knows how to reconcile both of them and expose them to the caller as a consistently joined entity.
Inner join
Let's focus now on the first type of joins supported in Structured Streaming, the inner join. In fact, the logic behind inner join is also a part of the logic behind the outer joins.The physical execution of the join, in both cases, is delegated to OneSideHashJoiner class created on every side (left and right). The instance takes multiple parameters in the constructor like, of course, the join information (keys, output columns) but also filters. The join happens by combining OneSideHashJoiners:
val leftOutputIter = leftSideJoiner.storeAndJoinWithOtherSide(rightSideJoiner) {
(input: InternalRow, matched: InternalRow) => joinedRow.withLeft(input).withRight(matched)
}
val rightOutputIter = rightSideJoiner.storeAndJoinWithOtherSide(leftSideJoiner) {
(input: InternalRow, matched: InternalRow) => joinedRow.withLeft(matched).withRight(input)
}
As you can notice, the whole logic is executed inside the storeAndJoinWithOtherSide function. What happens first? In the beginning, the joiner filters out the late rows, so the rows older than the current watermark (if specified). After a preJoinFilter is applied on every row of this join side. This filter is extracted from the join's ON clause to filter out not matching rows and avoid unnecessary state store lookups. This filter will often be pushed down to the data source thanks to the org.apache.spark.sql.catalyst.optimizer.PushDownPredicates logical optimization. So to see the preJoinFilter in action, be sure to exclude this rule from the planning stage.
The execution flow so far looks like that:
val watermarkAttribute = inputAttributes.find(_.metadata.contains(delayKey))
val nonLateRows =
WatermarkSupport.watermarkExpression(watermarkAttribute, eventTimeWatermark) match {
case Some(watermarkExpr) => // Filter too old rows
case None => // Return every input row
}
nonLateRows.flatMap { row =>
val thisRow = row.asInstanceOf[UnsafeRow]
if (preJoinFilter(thisRow)) {
// The join logic here
The join logic starts by generating the join key from the ON expression. Next, it calls the state store manager of the opposite side to retrieve the persisted rows for the join key. The result of this fetch is an iterator that is later wrapped around AddingProcessedRowToStateCompletionIterator. The AddingProcessedRowToStateCompletionIterator instance returns only the rows matching another type of filter called postJoinFilter which is the filter from ON clause applying on the joined row. In the picture below you can see the correspondence between all these predicates and the input query:

The AddingProcessedRowToStateCompletionIterator instance, once all rows returned, calls an internal callback defined in completion where the matched rows are added to the state store if they don't match watermark predicates:
override def completion(): Unit = {
val shouldAddToState = // add only if both removal predicates do not match
!stateKeyWatermarkPredicateFunc(key) && !stateValueWatermarkPredicateFunc(thisRow)
if (shouldAddToState) {
joinStateManager.append(key, thisRow, matched = iteratorNotEmpty)
updatedStateRowsCount += 1
}
}
}
Join with state store
You still don't know how the join is performed. The join logic is based on the state store and works as follows. When the left side is executed, even if the matching row is not found, every non late, not expiring, and not filtered row is added to the state store in the completion() method you saw previously. It's important to notice that even if the joined row doesn't fit the postJoinFilter predicate, the "one side row" can still be added to the state store if it doesn't break the 2 watermark-based predicates.
Next, the other side of the join goes through the same process. And since it uses the state store of the first join side to find the matches, it will be able to get all rows added so far in the first side's process. On a picture, in could be represented like that:
The combined rows are directly returned to the sink and never stored in the state store. But as you saw, it doesn't apply to the input rows. Does it mean the state store persists them forever? No. If we continue the workflow, you will see that the OneSideHashJoiner#removeOldState method is called once all combined rows (for all keys) are returned:
// StreamingSymmetricHashJoinExec#processPartitions
// Function to remove old state after all the input has been consumed and output generated
def onOutputCompletion = {
// ...
val cleanupIter = joinType match {
case Inner => leftSideJoiner.removeOldState() ++ rightSideJoiner.removeOldState()
case LeftOuter => rightSideJoiner.removeOldState()
case RightOuter => leftSideJoiner.removeOldState()
case _ => throwBadJoinTypeException()
}
while (cleanupIter.hasNext) {
cleanupIter.next()
}
// ...
// OneSideHashJoiner
def removeOldState(): Iterator[KeyToValuePair] = {
stateWatermarkPredicate match {
case Some(JoinStateKeyWatermarkPredicate(expr)) =>
joinStateManager.removeByKeyCondition(stateKeyWatermarkPredicateFunc)
case Some(JoinStateValueWatermarkPredicate(expr)) =>
joinStateManager.removeByValueCondition(stateValueWatermarkPredicateFunc)
case _ => Iterator.empty
}
}
As you can see, there is a different treatment for the outer joins that is covered in the next section.
Outer join
First, the output generation uses a dedicated case in the join type pattern matching of processPartitions. The logic for both of them is the same, except applied on different sides, so let's focus only on the left outer join case:
case LeftOuter =>
def matchesWithRightSideState(leftKeyValue: UnsafeRowPair) = {
rightSideJoiner.get(leftKeyValue.key).exists { rightValue =>
postJoinFilter(joinedRow.withLeft(leftKeyValue.value).withRight(rightValue))
}
}
val removedRowIter = leftSideJoiner.removeOldState()
val outerOutputIter = removedRowIter.filterNot { kv =>
stateFormatVersion match {
case 1 => matchesWithRightSideState(new UnsafeRowPair(kv.key, kv.value))
case 2 => kv.matched
case _ =>
throw new IllegalStateException("Unexpected state format version! " +
s"version $stateFormatVersion")
}
}.map(pair => joinedRow.withLeft(pair.value).withRight(nullRight))
innerOutputIter ++ outerOutputIter
The first step consists of retrieving all expired rows on the left side because these rows are the candidates for the null-join result (= no match on the right side). Later every null-join row that doesn't have the match on the right side (V1) or was not already matched, is returned alongside all matched rows built with the inner join logic presented before.
Before terminating, a few words about the watermark predicates used to figure out whether the row should be added to the state store or not, or whether it should be considered as a state to remove. The logic is based either on stateKeyWatermarkPredicateFunc or on stateValueWatermarkPredicateFunc predicates. What's the difference? Nothing better than a picture to explain it:
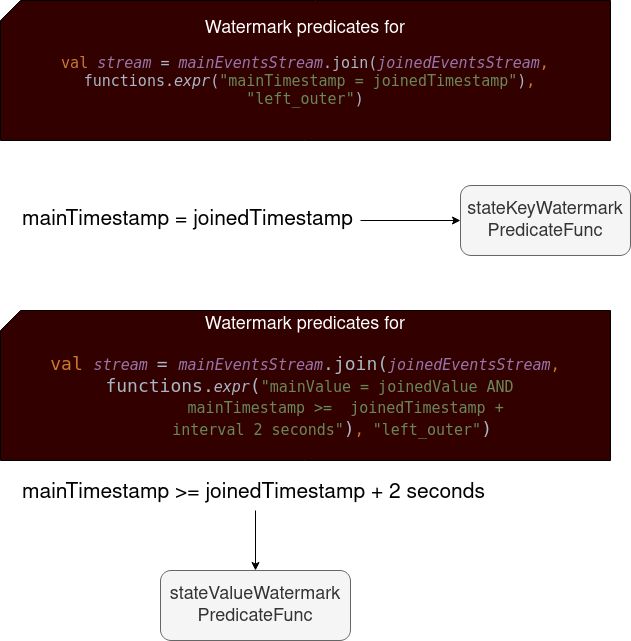
As you can see, the former predicate (stateKey) is used when the join keys are the same as the watermark columns. The latter one applies when the join expression has a range condition on the watermark columns. An important thing to notice on this occasion is that the predicate works only on one side of the join, the "main" (left from the picture) one. It means that the rows from the other side won't be persisted in the state store because they use the default watermark predicate functions, which return true. That's the reason why the shouldAddToState condition from the following snippet won't be met:
// completion() method already quoted
val shouldAddToState = // add only if both removal predicates do not match
!stateKeyWatermarkPredicateFunc(key) && !stateValueWatermarkPredicateFunc(thisRow)
To be honest, I didn't expect to see so many things to cover when I planned this blog post. But I hope that despite the unusual length and thanks to the visual components, you understood what's going on with the state store for stream-to-stream joins. Feel free to comment if it's not the case, and see you tomorrow for another blog post!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Data+AI Summit follow-up post: Why RocksDB rocks?
- Data+AI Summit: custom state store integration feedback
- Data+AI Summit: Custom state store - API
- Data+AI follow-up: Introduction to MapDB
- Data+AI Summit follow-up: arbitrary stateful processing and state management
All the best for 2021! To start it on the blog, a new part of Data+AI follow-up posts is online. This time you can see how #ApacheSpark #StructuredStreaming uses state store for joins ? https://t.co/PdxgrXPALR
— Bartosz Konieczny (@waitingforcode) January 2, 2021